1. Вступ
1.1. Історична довідка

Python – динамічна інтерпретована об’єктно-орієнтована скриптова мова програмування із строгою динамічною типізацією. Розроблена в 1990 році голандським програмістом Гвідо ван Россумом .
Автор назвав мову на честь популярного британського комедійного серіалу 1970-х років «Літаючий цирк Монті Пайтона». Найчастіше вживане прочитання назви мови — «Па́йтон».
Офіційний сайт мови програмування Python https://www.python.org/ .
1.2. Python в реальному світі
1.2.1. Короткий опис
Python – багатоцільова мова програмування, яка дозволяє писати код, що добре читається. Відносний лаконізм мови Python дозволяє створити програму, яка буде набагато коротше свого аналога, написаного на іншій мові.
Python - багатоплатформова мова програмування. Це означає, що програми на Python можна запускати в різних операційних системах без будь-яких змін.
Ще однією перевагою Python є його стандартна бібліотека, яка встановлюється разом з Python і містить готові інструменти для роботи з операційною системою, вебсторінками, базами даних, різними форматами даних, для побудови графічного інтерфейсу програм тощо.
Програми, написані на мові програмування Python, можуть бути як невеликими скриптами, так і складними системами.
Python абсолютно безкоштовний.
1.2.2. Використання Python
Python використовується для різних цілей: для створення ігор і веб-застосунків, розробки внутрішніх інструментів для різноманітніх проектів. Мова також широко застосовується в науковій області для досліджень і розв’язування прикладних завдань.
1.2.3. Версії Python
Мови програмування з часом змінюються - розробники додають в них нові можливості, а також виправляють помилки. Так з’являються різні версії мови. Наприклад, код написаний на Python 2 здебільшого не буде працювати у версії Python 3 без внесення додаткових змін.
Основна команда розробників мови Python припинила підтримку версії Python 2.x 1 січня 2020 року.
|
У посібнику використовується версія 3.x. Зокрема, усі приклади коду написані і протестовані для версій Python 3.4 і вище. Тобто, використання новіших версій інтерпретатора Python 3 не повинно викликати появу помилок при виконанні прикладів коду (де це необхідно, наводиться пояснення щодо версії, яка використовується). Якщо необхідно дізнатися, що і коли було додано у різні версії мови програмування Python, відвідайте сторінку з документацією Python .
|
2. Початок роботи
2.1. Від машинної мови до мови високого рівня
Процесор є найважливішим компонентом в комп’ютері. Одна з основних функцій процесора - це обробка даних згідно комп’ютерної програми, яка є списком інструкцій, шляхом виконання арифметичних і логічних операцій над фрагментами даних.
Кожна інструкція в програмі - це команда, яка «повідомляє» процесору, яку операцію він повинен виконати. Ось приклад інструкції, яка може бути присутня в програмі
10111010Для нас - це лише послідовність 0 і 1. Однак для процесора - це інструкція виконати певну операцію. Процесор комп’ютера може розуміти лише ті інструкції, які написані на машинній мові.
| Машинна мова - це штучна мова, створена для передачі команд комп’ютеру. За допомогою машинної мови створюються ефективні програми, оскільки розробник отримує доступ до всіх можливостей процесора. Машинна мова - мова низького рівня. |
Інструкція машинної мови існує для кожної операції, яку процесор здатний виконати - є інструкція для додавання чисел, є інструкція для віднімання чисел і т. д.
| Увесь набір інструкцій, який центральний процесор може виконати, відомий як набір інструкцій процесора. |
Наприклад, у вас є певна програма, яка зберігається на диску вашого комп’ютера. Для виконання програми, ви здійснюєте подвійний клік на значку програми. Це змушує програму копіюватися з диска в оперативну пам’ять, після чого процесор комп’ютера виконує копію програми, яка знаходиться в оперативній пам’яті.
Коли процесор виконує інструкції програми, він бере участь у процесі, який є відомим як цикл fetch - decode - execute (отримати - декодувати - виконати). Цей цикл виконується для кожної інструкції у програмі і складається з трьох кроків:
- Отримати
-
Програма - це послідовність інструкцій на машинній мові. Першим кроком циклу є завантаження (отримання) наступної інструкції з пам’яті в процесор.
- Декодувати
-
Інструкція машинної мови - це двійкове число, яке представляє команду, що повідомляє процесору виконати певну операцію. На цьому кроці процесор декодує інструкцію, яку було «витягнуто» з пам’яті, для визначення того, яка операція повинна виконуватись.
- Виконати
-
Останній крок циклу - виконати операцію.
Хоча процесор комп’ютера розуміє тільки машинну мову, людині непрактично писати програми на машинній мові. Така програма може мати тисячі або навіть мільйони бінарних інструкцій, і написання такої програми буде дуже обтяжливим процесом.
З цієї причини була створена мова асемблера як альтернатива машинній мові. Замість використання двійкових чисел для написання інструкцій, мова асемблера використовує короткі слова, відомі як мнемокоди.
Наприклад, на мові асемблера, мнемокод add, як правило, означає, що потрібно додати числа, а mul, як правило, означає, множення чисел, а mov, як правило, означає переміщення значення у певне місце в пам’яті.
Знову ж таки, процесор «розуміє» лише машинну мову, тому спеціальна програма, відома як Асемблер, використовується для збірки програми у програму на машинній мові. Цей процес можна проілюструвати так:
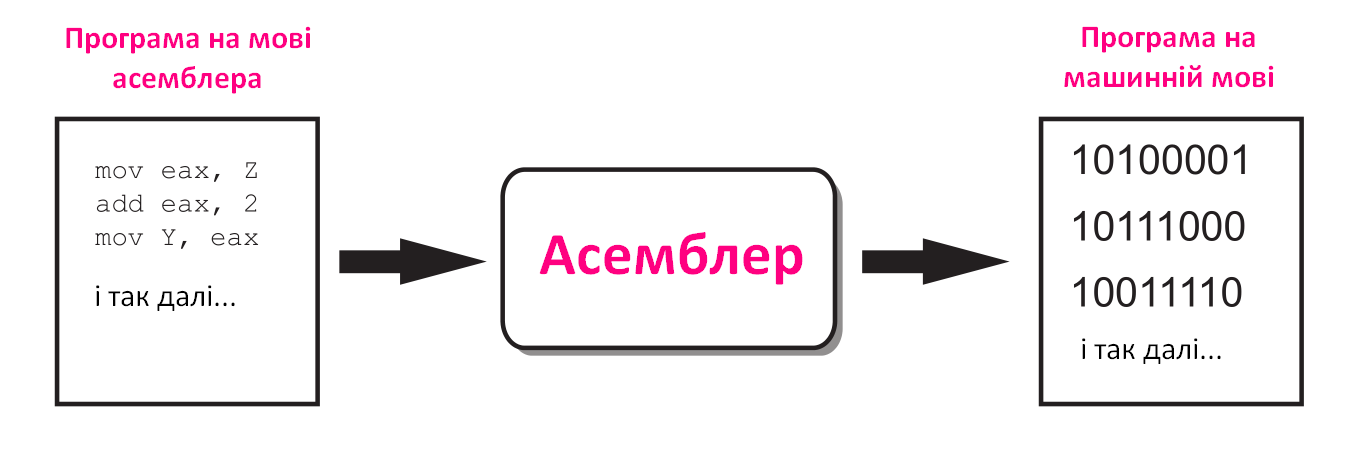
Незважаючи на те, що мова асемблера не вимагає двійкових інструкцій, як у випадку машинної мови, проте вона вимагає високих знань про процесор. Використовуючи мову асемблера, навіть для найпростішої програми, необхідно написати велику кількість інструкцій.
| Оскільки мова асемблера близька за своєю природою до машинної мови, вона є мовою низького рівня. |
Мова програмування високого рівня дозволяє створювати cкладні програми, не знаючи, як працює процесор, і не записуючи великої кількості інструкцій низького рівня. Крім того, більшість мов програмування високого рівня використовують слова, які легко зрозуміти.
Python - одна із популярних сучасних мов програмування високого рівня.
Наприклад, у Python для відображення повідомлення Hello, World! необхідно записати наступну інструкцію:
print('Hello, World!')Щоб виконати те ж саме, записавши інструкції мовою асемблера, потрібно декілька вказівок та глибокі знання про те, як процесор взаємодіє з пристроями комп’ютера:
section .text
global _start
_start:
mov edx, len
mov ecx, msg
mov ebx, 1
mov eax, 4
int 0x80
mov eax, 1
int 0x80
section .data
msg db 'Hello, World!',0xa
len equ $ - msgЯк видно з цього прикладу, мови високого рівня дозволяють зосередитися на завданнях, які необхідно виконати, а не на тому, як процесор буде виконувати комп’ютерні програми.
2.2. Python - інтерпретована мова програмування
Python - це високорівнева інтерпретована мова програмування, на відміну від C++, яка є прикладом компільованої мови програмування.
Назва Python відноситься як до мови програмування, так і до інтерпретатора - комп’ютерної програми, яка зчитує початковий код (написаний на Python) і виконує інструкції (команди).
Програми, написані на мові високого рівня, називаються початковим кодом. Для виконання програми комп’ютером необхідно перекласти початковий код на машинну мову, яка складається лише з двійкових цифр 0 і 1.
|
Для перекладу з мови високого рівня у машинну мову доступні два типи програм:
-
Компілятор
-
Інтерпретатор
| Компілятор перекладає весь початковий код на машинну мову за один раз, потім машинний код виконується. |
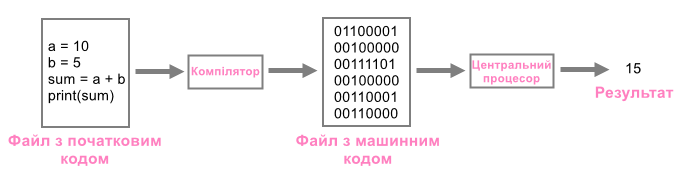
| Інтерпретатор перекладає програму з мови високого рівня у машинну мову рядок за рядком, виконуючи кожен з них. |
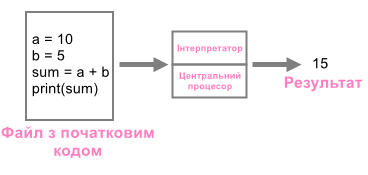
Інтерпретатор Python починає свою роботу у верхній частині файла, перекладає перший рядок на машинну мову, а потім виконує його. Цей процес повторюється до кінця файла.
|
2.3. Завантаження Python
Версії інтерпретатора Python для різних операційних систем доступні для безкоштовного завантаження за адресою https://www.python.org/downloads .
Як завантажити і налаштувати роботу Python читайте у Додатку A: Завантаження і встановлення Python.
2.4. Середовище програмування для Python
Для написання програм використовують текстові редактори або інтегровані середовища розробки, які включають в себе різні інструменти для роботи з кодом: засіб для написання коду (текстовий редактор), інтерактивний інтерпретатор, відлагоджувач тощо.
Для налаштування деяких вищезгаданих середовищ програмування зверніться до Додатку B: Налаштування середовища програмування.
Для написання програм мовою Python можна використовувати онлайн-середовище repl.it .
|
2.5. Запуск Python: інтерактивний інтерпретатор
У режимі інтерактивного інтерпретатора команди вводяться у термінальному вікні (консольне вікно, вікно командного рядка) одна за одною і по натисненні клавіші Enter відразу виконуються з відображенням результату виконання.
Щоб відкрити вікно терміналу:
-
натисніть сполучення клавіш Win+R на клавіатурі, введіть команду
cmd, натисніть OK (для користувачівWindows); -
натиcніть сполучення клавіш Ctrl+Alt+T (для користувачів
Linux Ubuntu).
У термінальному вікні, що з’явилося, введіть команду (у випадку використання Windows):
pythonабо (у випадку використання Linux Ubuntu можна вказати версію Python, наприклад, 3.9):
python3.9Якщо на екрані з’явиться запрошення >>> до введення команд, значить система виявила встановлену версію Python:
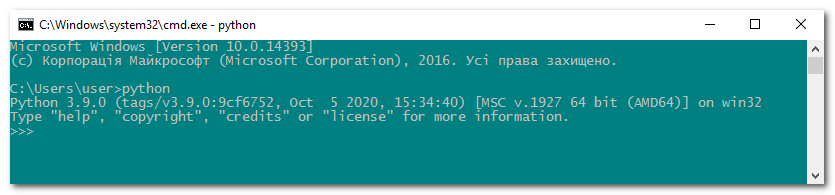
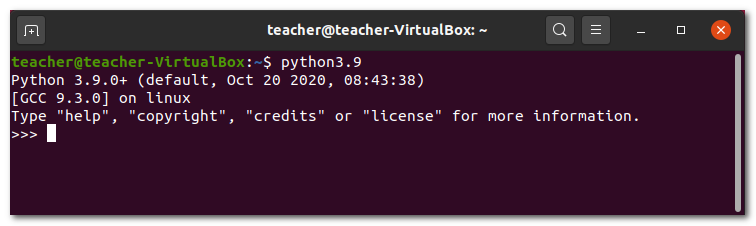
Введіть в інтерактивному режимі інтерпретатора наступний рядок
print('Hello, Python!')натисніть Enter і переконайтеся в тому, що на екрані з’явилось повідомлення Hello, Python!:
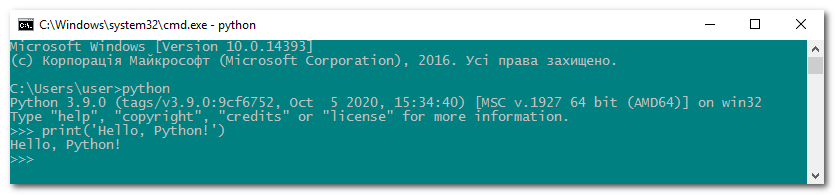
Функція print() входить у стандартну бібілотеку Python. Вона виводить інформацію, вказану в дужках, на екран або записує у файл.
|
Щоб вийти з режиму інтерактивного інтерпретатора Python, натисніть Ctrl+Z і Enter у Windows, Ctrl+D у Linux Ubuntu або виконайте команду exit() .
|
2.6. Робота з файлами Python
Програми, написані на мові Python, зберігають у вигляді текстових файлів з розширенням .py. В текстовому редакторі створіть новий файл і введіть у нього рядок:
print("Hello, Python!")Збережіть файл з іменем hello.py у каталог python_work, який, наприклад, знаходиться на стільниці вашої операційної системи.
| Переконайтеся, що ви зберегли файл як звичайний текст! |
Такі файли з кодом програми можна запускати у термінальному вікні.
2.6.1. Запуск програм в терміналі Windows
Відкрийте термінальне вікно (вікно командного рядка): натисніть сполучення клавіш Win+R на клавіатурі, введіть команду cmd, натисніть OK і виконайте команди:
C:\Users>User> cd Desktop (1)
C:\Users>User\Desktop> cd python_work (2)
C:\Users>User\Desktop\python_work> dir (3)
hello.py (4)
C:\Users>User\Desktop\python_work> python hello.py (5)
Hello, Python! (6)
Назва User в записі - це ім’я користувача в системі.
|
-
Переходимо у каталог
Desktop(Стільниця) з використанням командиcd. -
Переходимо у каталог
python_workз використанням командиcd. -
Читаємо вміст каталогу
python_workз використанням командиdir. -
Відображення вмісту (присутній єдиний файл
hello.py). -
Запускаємо на виконання файл
hello.py(ввестиpythonта ім’я файла). -
Відображення результату у вікні терміналу.
Для переходу на рівень вгору у дереві каталогів використовують інструкцію cd .. . Для переходу на інший диск використовують команду, що складається з назви диска і вертикальної двокрапки, наприклад, d: .
|
Щоб закрити вікно терміналу, введіть команду exit і натисніть Enter .
|
2.6.2. Запуск програм в терміналі Linux Ubuntu
Відкрийте вікно терміналу, натиснувши сполучення клавіш Ctrl+Alt+T, і виконайте команди:
teacher@teacher-VirtualBox:~$ pwd (1)
/home/teacher
teacher@teacher-VirtualBox:~$ ls (2)
Відео Завантаження Зображення Стільниця
Документи Загальнодоступні Музика Шаблони
teacher@teacher-VirtualBox:~$ cd Стільниця (3)
teacher@teacher-VirtualBox:~/Стільниця$
teacher@teacher-VirtualBox:~/Стільниця$ ls (4)
python_work
teacher@teacher-VirtualBox:~/Стільниця$ cd python_work (5)
teacher@teacher-VirtualBox:~/Стільниця/python_work$ ls (6)
hello.py
teacher@teacher-VirtualBox:~/Стільниця/python_work$ python3.9 hello.py (7)
Hello, World! (8)
teacher@teacher-VirtualBox:~/Стільниця/python_work$ cd .. (9)
teacher@teacher-VirtualBox:~/Стільниця$ cd ~ (10)
teacher@teacher-VirtualBox:~$-
Дізнаємося поточне розташування з використанням команди
pwd(після запуску терміналу поточний каталог - домашній каталог користувача). -
Читаємо вміст поточного каталогу
teacherз використанням командиls. -
Переходимо у каталог
Стільницяз використанням командиcd. -
Читаємо вміст каталогу
Стільниця(всередині каталогpython_work). -
Переходимо у каталог
python_workз використанням командиcd. -
Читаємо вміст каталогу
python_work(всередині файлhello.py). -
Запускаємо на виконання файл
hello.py(ввести назву інтерпретатора разом із версієюpython3.9та ім’я файла). -
Відображення результату у вікні терміналу.
-
Переходимо на рівень вгору в дереві каталогів з використанням інструкції
cd ... -
Відразу переходимо у домашній каталог користувача з використанням інструкції
cd ˜.
Назва teacher@teacher-VirtualBox у записі - це ім’я користувача в системі і назва комп’ютера, розділені символом @.
|
Щоб закрити вікно терміналу, введіть команду exit і натисніть Enter .
|
2.7. Повідомлення про помилку
В процесі написання і виконання програм можуть з’являтися різноманітні помилки. У таких випадках інтерпретатор Python сам сигналізує про помилку.
Наприклад, коли ми введемо в режимі інтерактивного інтерпретатора інструкцію '19' + 81, з’явиться таке повідомлення:
>>> '19' + 81
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
TypeError: can only concatenate str (not "int") to strВведена інструкція некоректна для Python, тому він вказав назву помилки і номер рядка, в якому вона виникла, зупинивши виконання програми.
У Python, у разі появи помилки генерується виняток, який повідомляє про зміст помилки. В даному випадку, згенерований виняток TypeError повідомляє про несумісність типів під час додавання числа і рядка, іншими словами, рядок можна об’єднувати лише з рядком.
|
Якщо помилка зрозуміла для нас, її виправляють. В іншому випадку, щоб дізнатися, що означає повідомлення про помилку, можна здійснити пошук в мережі Інтернет за назвою помилки.
Основні помилки, що можуть виникнути при написанні програм на Python і шляхи їх виправлення можна переглянути у Додатку D: Код не працює: типові помилки.
|
2.8. Коментарі
Коментарі надзвичайно корисні в будь-якій мові програмування. У міру зростання обсягу і складності коду в програмі слід додавати коментарі, які описують загальний підхід до розв’язуваної задачі. Коментарі - це, свого роду, нотатки, написані на зрозумілій мові.
У мові Python ознакою коментаря є символ #. Інтерпретатор Python ігнорує всі символи в коді після # до кінця рядка. Наприклад:
>>> # Привіт, світ!
... print("Hello, world!")
Hello, world!2.9. Продовження рядків
Будь-яка програма стає більш зрозумілою, якщо її рядки короткі. Рекомендована (але не обов’язкова) максимальна довжина рядка не повинна перевищувати 80 символів. Якщо ви не можете висловити свою думку в рамках 80 символів, скористайтеся символом продовження рядка (\).
Просто помістіть \ в кінець рядка, а Python буде діяти так, ніби це все той самий рядок. Наприклад:
>>> alphabet = 'abcdefg' + \
... 'hijklmnop' + \
... 'qrstuv' + \
... 'wxyz'
>>> alphabet
'abcdefghijklmnopqrstuvwxyz'
>>> 1 + 2 + \
... 3
62.10. Стиль Python
Кожна мова програмування має свій стиль і Python не є винятком. Розробники мови є прихильниками певної філософії програмування, яку називають «The Zen of Python» («Дзен Пайтона»). Її текст можна отримати у інтерпретаторі Python за допомогою команди:
import thisУ більшості мов програмування використовуються спеціальні символи (наприклад, фігурні дужки {}) або ключові слова (наприклад, begin і end) для того, щоб розбити код на частини. У цих мовах хорошим тоном є використання відступів при написанні коду, щоб зробити програму зручною для читання як для себе, так і для інших.
На відміну від багатьох інших мов, Python обов’язково вимагає, щоб блоки коду забезпечувалися відступами.
У Python для побудови структури програми використовуються відступи від лівого краю, які створюються за допомогою пропусків (пробілів).
|
Типова структура програми може мати такий вигляд (крапками позначені пропуски):
n = int(input())
out = []
for i in range(n):
....k = 0
....while k < i + 1:
........out.append(i+1)
........k += 1
....if len(out) > n:
........break
out = out[0:n]
for i in out:
....print(i, end = " ")Окрім того, для Python визначені рекомендації по стилю написання коду PEP8 .
Використовуйте 4 пропуски на рівні відступів.
|
2.11. Завдання
2.11.1. Контрольні запитання
-
Хто є розробником мови
Python? Звідки походить назва мови програмуванняPython? -
Для яких цілей використовується
Python? -
Як перейти в режим інтерактивного інтерпретатора?
-
Яке розширення мають файли із програмами, написаними на мові
Python? -
Як запустити програму, що міститься у файлі, на виконання у термінальному вікні?
-
У яких випадках, під час виконання програми, може з’явитися повідомлення
Traceback (most recent call last)? -
Який символ використовується у мові
Pythonдля позначення коментарів?
2.11.2. Вправи
-
Встановіть
Python 3. Зверніться до Додатку А: Завантаження і встановлення Python. -
Встановіть середовище програмування. Зверніться до Додатку B: Налаштування середовища програмування.
-
Запустіть інтерактивний інтерпретатор
Python 3і використайте його як калькулятор. Наприклад, обчисліть19 * 81. Запишіть цей добуток і натисніть Enter, щоб побачити результат.Pythonповинен вивести1539. -
Введіть число
43і натисніть клавішу Enter. Чи з’явилось це число в наступному рядку? -
Введіть
print(43)і натисніть клавішу Enter. Чи з’явилось знову це число в наступному рядку? -
В інтерактивному інтерпретаторі
Pythonвведіть'Python' + 3. Знайдіть інформацію в мережі Інтернет про помилку, що виникла, за її назвою. -
Перегляньте принципи
Python, ввівши в термінальму сеансі командуimport this. Знайдіть переклад тексту філософіїPythonна сторінці .
3. Прості типи даних
При виконанні, програма обробляє дані різного типу (числові, текстові дані тощо). Тип даних задає як множину можливих значень даних, так і визначає операції, які можуть бути над ними виконані.
Кожне з даних характеризується розміром виділеної пам’яті для зберігання, ім’ям (ідентифікатором), типом і значенням.
Імена дозволяють ідентифікувати дані, тобто відрізняти їх між собою. Тип обирають для кожної величини, яка використовується для подання реальних об’єктів.
Мови програмування мають в своєму арсеналі деякі прості (вбудовані) типи даних. Вони використовуються як базові блоки для програм та складних (спеціалізованих) типів даних.
У Python вбудовані такі прості типи даних:
-
Булевий (має значення
TrueіFalse). -
Цілі числа (наприклад,
81,1000). -
Числа з рухомою крапкою (наприклад,
3.14159,2.5e8,4000.0). -
Рядки (послідовності текстових символів, наприклад
Hello, Python!).
Для розділення цілої і дробової частини у дійсних числах в Python використовується символ крапки.
|
Кожен тип має специфічні правила використання і вони по-різному обробляються комп’ютером.
3.1. Об’єкти та змінні
В Python усе - булеві значення, цілі числа, числа з рухомою крапкою, рядки, складні структури даних, функції - реалізовано як об’єкти.
Про об’єкти у Python та деякі особливості інтерпретатора Python читайте на цій сторінці .
|
Мови програмування також дозволяють визначати змінні. Ви можете визначити їх для використання у своїй програмі.
В Python для присвоювання змінній певного значення використовується символ =.
У математиці символ = означає «дорівнює». У багатьох мовах програмування, включаючи Python, цей символ використовується для позначення «присвоювання».
|
У наступному фрагменті програми ціле число 12 присвоюється змінній з ім’ям a, потім на екран виводиться значення, пов’язане в поточний момент з цією змінною:
>>> a = 12
>>> a
12Дуже розповсюджене твердження, що змінна - це контейнер для зберігання значень. Така аналогія справедлива для багатьох мов програмування (наприклад, C).
З іншого боку, змінні в Python схожі не на контейнери, а на ярлики чи стікери-наклейки, які прикріплюються до об’єктів із простору імен інтерпретатора Python.
До одного об’єкта може прикріплюватися будь-яка кількість стікерів (змінних), і при зміні цього об’єкта, значення, на які посилаються усі ці змінні, також змінюються.
Розглянемо простий фрагмент програми на Python, щоб зрозуміти, що це означає:
>>> a = [5, 6, 7] (1)
>>> b = a (2)
>>> c = b (3)-
Змінна
aмістить список із трьох числових значень. -
Присвоюємо змінній
bзначенняa. -
Присвоюємо змінній
cзначенняb.
А тепер змінимо перше значення (з 5 на 100) у списку, який зберігається у змінній b:
>>> a = [5, 6, 7]
>>> b = a
>>> c = b
>>> b[0] = 100Виведемо значення усіх змінних на екран:
>>> a = [5, 6, 7]
>>> b = a
>>> c = b
>>> b[0] = 100
>>> print(a, b, c)
[100, 6, 7] [100, 6, 7] [100, 6, 7]Якщо вести мову про змінні як контейнери, то як зміна вмісту одного контейнера є причиною до одночасної зміни вмісту двох інших?
Але якщо розуміти, що змінні - це всього-навсього стікери-наклейки (ярлики), які прикріплені до об’єктів, то зміна вмісту об’єкта, до якого відносяться усі три стікери, просто відображається в усіх трьох змінних.
В Python змінні - це просто імена. Присвоювання не копіює значення, воно прикріплює ім’я до об’єкта, який містить дані. Ім’я - це посилання на якийсь об’єкт, а не сам об’єкт. Ім’я можна розглядати як стікер-наклейку.
|

За допомогою інтерактивного інтерпретатора виконайте наступні кроки:
-
Як і раніше, надайте значення
12зміннійa. Це створить об’єкт-«скриньку», який міститиме цілочисельне значення12. -
Виведіть на екран значення
a. -
Присвойте
aзміннійb, змусившиbприкріпитися до об’єкту-«скриньки», який містить значення12. -
Виведіть значення
b.
>>> a = 12
>>> a
12
>>> b = a
>>> b
12Давайте перевіримо, чи посилаються змінні a і b на один і той же цілочисельний об’єкт зі значенням 12 за допомогою функції id().
Функція id() повертає індентифікатор об’єкта (адрес об’єкта в пам’яті комп’ютера).
|
>>> id(a)
1367960944
>>> id(b)
1367960944Як видно з результатів, при зв’язуванні змінної з існуючою, обидві змінні вказують на один об’єкт. Змінна при цьому не копіюється!
Що зберігатиметься у змінній b, якщо записати наступні дві інструкції?
>>> b = 'Goodbye!'
>>> b = 'Hello!'
>>> b
'Hello!'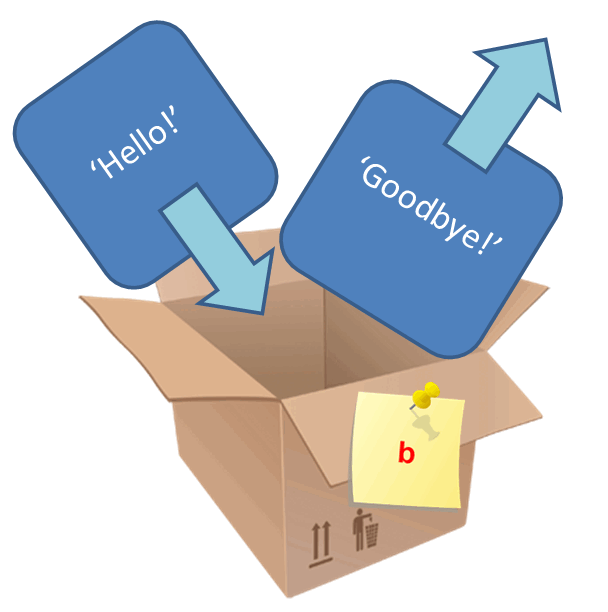
Тепер змінна b вказує на новий об’єкт, оскільки стікер-наклейку (змінну) ми переклеїти з одного об’єкта на інший (ідентифікатори змінилися):
>>> b = 'Goodbye!'
>>> id(b)
2371957227888
>>> b = 'Hello!'
>>> id(b)
2371957221112
>>> b
'Hello!Ідентифікатори використовуються для перевірки тотожності оператором is, тобто він перевіряє, чи вказують дві змінні на один і той же об’єкт:
>>> c = 10
>>> d = c
>>> c is d
True
>>> id(c)
1367960880
>>> id(d)
1367960880
>>> d = 15
>>> c is d
False
>>> id(d)
1367961040Отже, змінні дозволяють призначати об’єктам імена, щоб до них можна було звертатися з программного коду.
Змінним Python можуть присвоюватися будь-які об’єкти, тоді як в C і багатьох інших мовах змінна може зберігати значення тільки того типу, з яким вона була оголошена.
Для змінної тип неважливий у Python, типом володіє об’єкт, а не змінна.
|
Нижче наведено коректний код Python:
>>> s = 'Python'
>>> s
'Python'
>>> s = 3
>>> s
3Змінна s спочатку посилається на рядковий об’єкт зі значенням Python, а потім на об’єкт цілого числа 3.
Змінна може бути заново пов’язана з будь-яким типом. Якщо з об’єктом не пов’язана жодна змінна, ви фактично кажете Python знищити об’єкт при першій можливості, щоб звільнити займану ним пам’ять (в програмуванні це називається збиранням сміття).
Довільне присвоєння одному імені змінної різних типів даних ускладнює розуміння коду, що може збити з пантелику тих, хто буде читати код в майбутньому. Початківці-розробники Python нерідко допускають одну і ту ж помилку: вони заново використовують одну змінну в своєму коді, вважаючи, що вони тим самим економлять пам’ять. Як ми бачимо, це не так. Самі змінні пам’яті майже не займають - вона витрачається для зберігання об’єкта.
|
В Python, якщо ви хочете дізнатися тип якогось об’єкта (змінної або значення), слід використовувати стандартну (вбудовану) функцію type().
Список поширених стандартних функцій Python можна переглянути у таблиці Додаток C: Стандартні функції Python.
|
Спробуємо зробити це для різних значень (81, 99.99, ruby) і змінної (a):
>>> type(a)
<Class 'int'>
>>> type(81)
<Class 'int'>
>>> type(99.99)
<Class 'float'>
>>> type('ruby')
<Class 'str'>Як бачимо з результатів, типи даних є також об’єктами.
Клас - це визначення об’єкта. В Python значення термінів «клас» і «тип» приблизно однакові.
|
Необхідно дотримуватись певних вимог використання імен змінних. Імена змінних можуть містити тільки такі символи:
-
літери в нижньому регістрі (
a-z) -
літери у верхньому регістрі (
A-Z) -
цифри (
0-9) -
нижнє підкреслення (
_)
Імена не можуть починатися з цифри.
Python особливо обробляє імена, які починаються із символа нижнього підкреслення.
|
Коректними є такі імена:
a
a5
a_b_c_81
abc
_3aНаступні імена є некоректними:
2
2a
2_Не слід використовувати наступні слова для імен змінних, оскільки вони є зарезервованими словами Python (ці слова і деякі знаки пунктуації використовуються у синтаксисі мови Python):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Усі зарезервовані слова мови програмування Python можна переглянути у таблиці Додаток C: Зарезервовані слова Python.
|
3.2. Числа
Числа дуже часто застосовуються у програмуванні (ведення рахунку у грі, представлення даних на діаграмі, зберігання інформації у веб-застосунках тощо). Числа використовуються у виразах (наприклад, 2 + 3), у яких виконують обчислення за допомогою математичних операторів (наприклад, +) над операндами (наприклад, 2, 3).
| Оператор | Опис | Приклад | Результат |
|---|---|---|---|
|
Додавання |
|
|
|
Віднімання |
|
|
|
Множення |
|
|
|
Ділення |
|
|
|
Цілочисельне ділення |
|
|
|
Остача від ділення |
|
|
|
Піднесення до степеня |
|
|
В Python числові дані поділяються на кілька категорій за способом їх використання.
3.2.1. Цілі числа
Будь-яка послідовність цифр в Python вважається цілим числом:
Не потрібно ставити на початку числа 0, бо це викличе помилку некоректний символ.
|
>>> 10
10
>>> 05
File "<stdin>", line 1
05
^
SyntaxError: invalid tokenПослідовність цифр вказує на ціле число. Якщо ви поставите знак + перед цифрами, число залишиться незмінним:
>>> 132
132
>>> +132
132Щоб вказати на від’ємне число, поставте перед цифрами знак -:
>>> -321
-321За допомогою Python можна виконувати арифметичні дії як зі звичайним калькулятором:
>>> 25 + 9
34
>>> 145 - 37
108
>>> 8 + 3 - 2 + 1 - 106
-96
>>> 6 * 7
42Операції ділення існує два види. За допомогою оператора / виконується ділення з рухомою крапкою (десяткове ділення). Навіть, якщо ви ділите ціле число на ціле число, оператор / дасть результат з рухомою крапкою:
>>> 9 / 5
1.8Цілочисельне ділення за допомогою оператора // дає цілочисельну відповідь, відкидаючи залишок:
>>> 9 // 5
1Ділення на нуль з допомогою будь-якого оператора викличе помилку:
>>> 6 / 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> 8 // 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: integer division or modulo by zeroВикористаємо в обчисленнях змінні та змінимо їх значення:
>>> a = 42
>>> a = a - 2
>>> a
40
У мові Python, вираз, який стоїть справа від знака присвоювання =, обчислюється в першу чергу, запам’ятовується результат обчислення і тільки потім результат обчислення присвоюється змінній, яка стоїть з лівої сторони.
|
Арифметичні оператори можуть використовуватися разом із оператором присвоювання, розміщуючи їх перед символом присвоювання:
>>> a = 95
>>> a -= 3 (1)
>>> a
92
>>> a += 8 (2)
>>> a
100
>>> a *= 2 (3)
>>> a
200
>>> a /= 3 (4)
>>> a
66.66666666666667-
Аналогічно виразу
a = a - 3. -
Аналогічно виразу
a = a + 8. -
Аналогічно виразу
a = a * 2. -
Аналогічно виразу
a = a / 3.
За допомогою символу %, коли він знаходиться між двома числами, обчислюється остача від ділення першого числа на друге:
>>> 23 % 6
53.2.2. Перетворення типів: функція int()
Для того, щоб змінити інші типи даних на цілочисельний тип, слід використовувати функцію int().
Функція int() зберігає цілу частину числа і відкидає будь-який залишок.
|
Найпростіший тип даних в Python - булеві змінні, значеннями цього типу можуть бути тільки True або False. При перетворенні в цілі числа вони набувають значень 1 і 0:
>>> int(True)
1
>>> int(False)
0Перетворення числа з рухомою крапкою в ціле число просто відсікає все, що знаходиться після десяткової крапки:
>>> int(98.6)
98
>>> int(1.5e4)
15000Розглянемо приклад перетворення текстового рядка, який містить тільки цифри або цифри і знаки + і -:
>>> int('99')
99
>>> int('-23')
-23
>>> int('+12')
12Якщо ви спробуєте перетворити щось не подібне на число, згенерується помилка:
>>> int('22 abc')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '22 abc'Функції int() можна передати необов’язковий другий аргумент з основою системи числення, яка повинна використовуватися при інтерпретації вхідного рядка. Проаналізуємо такий код:
>>> int('123.456') (1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '123.456'
>>> int('100', 8) (2)
64
>>> int('10011', 2) (3)
19
>>> int('fa', 16) (4)
250
>>> int('123', 3) (5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 3: '123'
>>> int('12', 3) (6)
5-
Перетворення числового рядка
'123.456'у ціле число є неможливим, виникнення помилкиValueError, оскільки числовий рядок містить крапку. -
Інтерпретація числового рядка
'100'у вісімковій системі числення і перетворення в десяткове число64. -
Інтерпретація числового рядка
'10011'у двійковій системі числення і перетворення в десяткове число19. -
Інтерпретація рядка
'fa'у шістнадцятковій системі числення і перетворення в десяткове число250. -
Інтерпретація числового рядка
'123'у трійковій системі числення є неможливим, виникнення помилкиValueError, оскільки цифра3відсутня у трійковій системі числення. -
Інтерпретація числового рядка
'12'у трійковій системі числення і перетворення в десяткове число5.
3.2.3. Пріоритет операторів
Для ознайомлення з таблицею пріоритетів операторів Python перейдіть на сайт з документацією .
Пріоритет операторів Python можна також переглянути у таблиці Додаток C: Пріоритет операторів.
|
Для встановлення пріоритетів виконання операторів можна також скористатися дужками:
>>> 7 * (3 + 4)
493.2.4. Числа з рухомою крапкою
В Python числа, що мають дробову частину, називаються дійсними (або «числами з рухомою крапкою»). Для чисел з рухомою крапкою використовуються відомі оператори: +, -, *, /, //, **, %.
3.2.5. Перетворення типів: функція float()
Для того щоб перетворити інші типи в тип float (так називають дійсні числа в Python), cлід використовувати функцію float().
Функція float() перетворює значення інших типів у значення з рухомою крапкою.
|
Булеві значення обробляються як невеликі числа:
>>> float(True)
1.0
>>> float(False)
0.0Перетворення значення типу int в тип float:
>>> float(98)
98.0Ви також можете перетворювати рядки, що містять символи, які є коректним числами (цілими або з рухомою крапкою):
>>> float('99')
99.0
>>> float('98.6')
98.6
>>> float('-1.5')
-1.5
>>> float('1.0e4')
10000.03.2.6. Математичні функції
Python надає стандартні функції для роботи з числовими даними: abs(), pow(), round().
Розглянемо як ці функції працюють:
>>> abs(-34) (1)
34
>>> abs(-34.56) (2)
34.56
>>> pow(2, 3) (3)
8
>>> pow(-4.5, 2) (4)
20.25
>>> round(10.6) (5)
11
>>> round(3.5) (6)
4
>>> round(8.5) (7)
8
>>> round(2.665, 2) (8)
2.67
>>> round(2.675, 2) (9)
2.67-
Повертає абсолютне значення від’ємного цілого числа.
-
Повертає абсолютне значення від’ємного дробового числа.
-
Піднесення додатного цілого числа до степеня
3. -
Піднесення від’ємного дробового числа до степеня
2. -
Якщо не вказано другого аргумента, округлює число до найближчого цілого числа (число
11ближче знаходиться). -
Якщо не вказано другого аргумента, округлює число до найближчого цілого числа. Але, якщо два кратні числа однаково рівновіддалені, округлення робиться в напрямку парного вибору (округлення до
4, оскільки4парне). -
Якщо не вказано другого аргумента, округлює число до найближчого цілого числа. Але, якщо два кратні числа однаково рівновіддалені, округлення робиться в напрямку парного вибору (округлення до
8, оскільки8парне). -
Повертає число з рухомою крапкою, округлене до вказаного числа цифр після десяткової крапки.
-
Обидва числа мають однакове округлення
2.67, хоча число2.675повинно було б бути округлене до2.68. Це не є помилкою. Це особливість представлення десяткових дробів уPython, яка пов’язана з точністю обчислення.
3.3. Рядки
Вважають, що програмісти добре знаються в математиці, тому що працюють з числами. Насправді, більшість програмістів працюють з текстовими рядками набагато частіше, ніж з числами.
Завдяки підтримці стандарту Unicode Python 3 може містити символи будь-якої мови світу, а також багато інших символів. Необхідність роботи із стандартом Unicode була однією з причин зміни Python 2.
|
Текстові рядки у Python 3 є рядками формату Unicode.
|
3.3.1. Створення рядків і функція print()
Будь-яка послідовність символів, укладена в лапки, в Python вважається рядком, при цьому рядки можуть бути укладені як в одинарні, так і в подвійні лапки:
>>> 'This is a string.'
'This is a string.'
>>> "This is also a string."
'This is also a string.'Навіщо мати два види лапок? Основна ідея полягає в тому, що ви можете створювати рядки, що містять лапки або апостроф. Тобто, усередині одинарних лапок можна розташувати подвійні і навпаки:
>>> 'I told my friend, "Python is my favorite language!"'
'I told my friend, "Python is my favorite language!"'
>>> "The language 'Python' is named after Monty Python, not the snake."
"The language 'Python' is named after Monty Python, not the snake."
>>> "One of Python's strengths is its diverse and supportive community."
"One of Python's strengths is its diverse and supportive community."Можна також використовувати три одинарні (''') або три подвійні лапки ("""):
>>> '''Yes'''
'Yes'
>>> """No"""
'No'Потрійні лапки не дуже корисні для таких коротких рядків. Вони, зазвичай, використовуються для того, щоб створити багаторядкові рядки, на зразок рядків вірша:
>>> """In the age of high technology
... Without programs you can not do,
... Programmers daily
... It makes life easier for us!"""Кожен рядок вірша вводився в інтерактивний інтерпретатор до тих пір, поки ми не ввели останні потрійні лапки і не перейшли до наступного рядка.
Усередині потрійних лапок символи переходу на новий рядок (\n) і пропуски зберігаються.
|
Якби ви спробували створити вірш за допомогою одинарних лапок, Python згенерував би помилку, коли б ви перейшли до наступного рядка:
>>> 'In the age of high technology
File "<stdin>", line 1
'In the age of high technology
^
SyntaxError: EOL while scanning string literalІснує різниця між результатом виведення на екран за допомогою інтерактивного інтерпретатора (на зразок рядків вірша)
>>> """In the age of high technology
... Without programs you can not do,
... Programmers daily
... It makes life easier for us!"""
'In the age of high technology\nWithout programs you can not do,\nProgrammers daily\nIt makes life easier for us!'та функції print():
>>> print('Python', 'is', 'my', 'favorite', 'language!')
Python is my favorite language!Із попереднього прикладу видно, що функція print() виводить на екран вміст, що записаний у лапках (але без них), додаючи пропуск між кожним виведеним елементом, а також символ переходу на новий рядок (\n) у кінці.
Функція print() має необов’язкові параметри end і sep, за допомогою яких можна вказати відповідно текст, який повинен бути в кінці виведення функції, і текст, який повинен бути розділювачем усередині вмісту функції.
|
Щоб змінити розділювач (за замовчуванням, це пропуск) між елементами, які виводить функція print(), треба використати її необов’язковий параметр sep і вказати розділювач:
>>> print('Python', 'is', 'my', 'favorite', 'language!', sep=',')
Python,is,my,favorite,language!Поглянемо на використання необов’язкового параметра end функції print(). Для прикладу, запустимо наступну програму, яка збережена у окремому файлі з певним ім’ям:
print('Hello')
print('World')Результат виведення буде таким:
Hello
WorldРядки відображаються на екрані на окремих рядках виведення, оскільки функція print() автоматично додає символи нового рядка \n в кінець рядка, який їй передається. За необхідністю, замість символа нового рядка \n можна використовувати інший рядок, вказаний з допомогою параметра end.
Наприклад для програми:
print('Hello', end='')
print('World')виведення буде таким:
HelloWorldВ даному випадку текст виводиться в один рядок, тому що відсутній символ нового рядка \n після рядка 'Hello'. Замість символа нового рядка \n виводиться порожній рядок ''. Цей прийом буде в нагоді в тих випадках, коли необхідно відмінити використання символа нового рядка \n, який автоматично додається в кінці кожного виведення за допомогою функції print().
Згаданий вище, порожній рядок можна утворити за допомогою різних лапок:
>>> ''
''
>>> ""
''
>>> """"""
''
>>> ''''''
''Необхідність створення порожніх рядків виникає, наприклад, при утворенні рядків з інших рядків:
>>> score = 55
>>> base = ''
>>> base += 'checking account: '
>>> base += str(score)
>>> base
'checking account: 55'3.3.2. Стиль форматування: функція format(), f-рядки
Розглянемо, як розміщувати різноманітні значення всередині рядків, застосовуючи різні формати. Цю можливість можна використовувати для створення певного зовнішнього вигляду при виведенні інформації.
Визначимо кілька змінних: цілочисельну n, число з рухомою крапкою f і рядок s:
>>> n = 25
>>> f = 9.03
>>> s = 'search string'За допомогою функції format() можна певним чином розмістити ці значення в одному рядку у тому порядку, як вони вказані для функції:
>>> '{} {} {}'.format(n, f, s)
'25 9.03 search string'Порядок виведення значень в рядку можна вказувати у фігурних дужках таким чином (нумерація починається з нуля):
>>> '{2} {0} {1}'.format(n, f, s)
'search string 25 9.03'У поданих прикладах значення виводяться на екран з форматуванням за замовчуванням. Python дозволяє вказувати специфікатори типу після символу : для форматування. Для прикладу:
>>> '{0:d} {1:f} {2:s}'.format(n, f, s)
'25 7.030000 search string'| Позначення | Тип |
|---|---|
|
Рядок |
|
Ціле число в десятковій системі числення |
|
Число з рухомою крапкою у десятковій системі числення |
Якщо потрібно вивести число з рухомою крапкою з точністю, наприклад, до трьох знаків, можна використати запис .3 перед ім’ям специфікатора f:
>>> '{0:d} {1:.3f} {2:s}'.format(n, f, s)
'25 9.030 search string'Функцією format() підтримуються і інші можливості (мінімальна довжина поля, максимальна ширина символів, зміщення і т. д.). Ось кілька прикладів:
Мінімальна довжина поля становить 10 для кожного значення, вирівнювання по правому краю (за замовчуванням):
>>> '{0:10d} {1:10f} {2:10s}'.format(n, f, s)
' 25 9.030000 search string'Мінімальна довжина поля становить 20 для кожного значення, вирівнювання по правому краю:
>>> '{0:>20d} {1:>20f} {2:>20s}'.format(n, f, s)
' 25 9.030000 search string'Мінімальна довжина поля становить 15 для кожного значення, вирівнювання по лівому краю:
>>> '{0:<15d} {1:<15f} {2:<15s}'.format(n, f, s)
'25 9.030000 search string 'Мінімальна довжина поля становить 10 для кожного значення, вирівнювання по центру:
>>> '{0:^10d} {1:^10f} {2:^10s}'.format(n, f, s)
' 25 9.030000 search string'Якщо ви хочете заповнити поле виведення чимось, окрім пропусків, розмістіть цей символ (у прикладі це символ =) відразу після двокрапки, але перед символами вирівнювання або специфікатором ширини:
>>> '{0:=^21s}'.format('My web-page')
'=====My web-page====='3.3.3. Перетворення типів: функція str()
Ви можете перетворювати інші типи даних Python в рядки за допомогою функції str():
>>> str(98.6)
'98.6'
>>> str(25)
'25'
>>> str(1.0e4)
'10000.0'
>>> str(True)
'True'3.3.4. Керуючі символи
Деякі послідовності символів Python особливим чином інтерпретує при роботі з рядками: \n позначає символ нового рядка, а \t - символ табуляції.
| Послідовності символів, що починаються зі зворотного слеша і використовуються для подання інших символів, називаються керуючими послідовностями або екранованими послідовностями. |
Екрановані послідовності, зазвичай, використовуються для включення у рядки спеціальних символів, що не мають стандартного односимвольного друкованого представлення.
Найбільш поширена послідовність \n, яка означає перехід на новий рядок. З її допомогою можна створити багаторядкові рядки з однорядкових:
>>> print('Languages:\nPython\nC\nRuby')
Languages:
Python
C
RubyЧасто зустрічається послідовність \t (табуляція), яка використовується для вирівнювання тексту, завдяки відступам:
>>> print('\tasciidoctor')
asciidoctor
>>> print('ascii\tdoctor')
ascii doctorПослідовності \' або \" використовуються, щоб помістити в рядок апостроф (одинарні лапки) або подвійні лапки, які оточені таким ж лапками:
>>> print("The language \"Python\" is named after Monty Python, not the snake.")
The language "Python" is named after Monty Python, not the snake.
>>> print('One of Python\'s strengths is its diverse and supportive community.')
One of Python's strengths is its diverse and supportive community.А якщо потрібно ввести зворотний слеш (\), перед ним треба поставити ще один:
>>> print('This inverse slash \\')
This inverse slash \| Послідовність | Представлений символ |
|---|---|
|
Одинарна лапка |
|
Подвійна лапка |
|
Зворотний слеш |
|
Звуковий сигнал |
|
Backspace |
|
Новий рядок |
|
Повернення курсора (не одне й теж, що |
|
Табуляція |
|
Вертикальна табуляція |
3.3.5. Конкатенація рядків
В Python за допомогою оператора + можна об’єднати рядки або рядкові змінні. Уявіть, що ім’я та прізвище зберігаються в різних змінних і ви хочете об’єднати їх для виведення повного імені:
>>> first_name = "Ada"
>>> last_name = "Lovelace"
>>> full_name = first_name + " " + last_name
>>> print(full_name)
Ada LovelaceТакий спосіб об’єднання рядків називається конкатенацією.
При конкатенації рядків Python не додає пропуски. Їх потрібно явно додавати.
|
Часто об’єкти, які не є рядками, використовується всередині рядків. Припустимо, ви хочете привітати свого товариша з днем народження. Ви написали для цього наступний код і запустили його на виконання:
>>> age = 23
>>> message = "Happy " + age + "rd Birthday!"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't convert 'int' object to str implicitlyВиникла помилка невідповідність типу. При такому використанні цілих чисел в рядках необхідно явно вказати, що ціле число повинне використовуватися як рядок із символів. Для цього змінна передається функції str(), яка перетворює нерядкові значення в рядкові:
>>> age = 23
>>> message = "Happy " + str(age) + "rd Birthday!"
>>> print(message)
Happy 23rd Birthday!3.3.6. Дублювання рядків
Оператор * (зірочка) можна використовувати для того, щоб продублювати рядок. Спробуйте ввести в інтерактивний інтерпретатор наступні рядки і проаналізувати результат:
>>> start = 'Na' * 4 + '\n'
>>> middle = 'Hey ' * 3 + '\n'
>>> end = 'Goodbye.'
>>> print(start + start + middle + end)
NaNaNaNa
NaNaNaNa
Hey Hey Hey
Goodbye.3.3.7. Доступ до елемента рядка за індексом
Для того, щоб отримати один символ рядка, задайте індекс (місцезнаходження) цього символа у рядку всередині квадратних дужок після імені рядка:
>>> letters = 'abcdefghijklmnopqrstuvwxyz'
>>> letters[0]
'a'
>>> letters[6]
'g'
>>> letters[-1]
'z'
>>> letters[36]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range| Індекси мають значення в діапазоні від 0 до довжина рядка - 1. |
3.3.8. Зрізи: функція slice[start: end: step]
З рядка можна «витягти» не лише один символ, але й підрядок (частину рядка) за допомогою функції slice. У квадратних дужках запису цієї функції вказується:
-
індекс початку підрядка
start -
індекс кінця підрядка
end -
розміру кроку
step
Деякими з цих параметрів можна знехтувати. У підрядок будуть включені символи, розташовані починаючи з символа, на який вказує індекс start, і закінчуватися символом, на який вказує індекс end. Наприклад, дано рядок, що містить англійські букви в нижньому регістрі:
>>> letters = 'abcdefghijklmnopqrstuvwxyz'
>>> letters[:] (1)
'abcdefghijklmnopqrstuvwxyz'
>>> letters[20:] (2)
'uvwxyz'
>>> letters[12:15] (3)
'mno'
>>> letters[-5:] (4)
'vwxyz'
>>> letters[18:-3] (5)
'stuvw'
>>> letters[-6:-2] (6)
'uvwx'
>>> letters[::7] (7)
'ahov'
>>> letters[4:20:3] (8)
'ehknqt'
>>> letters[19::4] (9)
'tx'
>>> letters[:21:5] (10)
'afkpu'
>>> letters[::-1] (11)
'zyxwvutsrqponmlkjihgfedcba'
>>> letters[60:70] (12)
''-
Отримати послідовність символів від початку і до кінця.
-
Отримати послідовність символів від
20-го символа і до кінця. -
Отримати послідовність символів від
12-го символа по15-й (15-й символ не включається). -
Отримати послідовність останніх
5символів. -
Отримати послідовність символів від
18-го символа і до3-го з кінця (3-й символ з кінця не включається). -
Отримати послідовність символів від
6-го символа з кінця і до2-го символа з кінця (2-й символ з кінця не включається). -
Отримати кожний
7-й символ з початку і до кінця. -
Отримати кожний
3-й символ від4-го символа з початку і до20-го символа (20-й символ не включається). -
Отримати кожний
4-й символ починаючи від19-го символа і до кінця. -
Отримати кожний
5-й символ починаючи з початку і до21-го символа (21-й символ не включається). -
Перевернути рядок з кінця на початок.
-
Вказування неправильних початкового і кінцевого індексів дає порожній рядок.
3.3.9. Довжина рядка: функція len()
Функція len() підраховує символи в рядку:
>>> letters = 'abcdefghijklmnopqrstuvwxyz'
>>> len(letters)
26
>>> empty = ""
>>> len(empty)
0
Функцію len() можна використовувати і для інших типів послідовностей.
|
3.3.10. Розділення рядка: функція split()
Функція split() розбиває рядок на окремі рядки і розміщує їх у списку.
|
Використовуючи цю функцію, необхідно вказати символ-розділювач (у нашому прикладі ,):
>>> dolist = 'pass algorithm, write a program, test program'
>>> dolist.split(',')
['pass algorithm', ' write a program', ' test program']Якщо ви не вкажете символ-розділювач, функція split() буде використовувати будь-яку послідовність пропусків, а також символи нового рядка і табуляцію:
>>> dolist.split()
['pass', 'algorithm,', 'write', 'a', 'program,', 'test', 'program']
Для виклику функції split(), навіть без аргументів, все одно потрібно додавати круглі дужки - саме так Python дізнається, що викликається функція.
|
3.3.11. Об’єднання рядків: функція join()
Функція join() є протилежністю функції split().
Функція join() об’єднує список рядків в один рядок.
|
Виклик функції виглядає трохи заплутано, оскільки спочатку ви вказуєте рядок, який об’єднує інші, а потім - список рядків для об’єднання: рядок.join(список рядків). В наступному прикладі об’єднаємо кілька імен в список, розділений комами і пропусками:
>>> crypto_list = ['Jumanji: Welcome to the Jungle', 'The Lost City of Z', 'Justice League']
>>> crypto_string = ', '.join(crypto_list)
>>> print('Browse films:', crypto_string)
Browse films: Jumanji: Welcome to the Jungle, The Lost City of Z, Justice League3.3.12. Регістр і вирівнювання
Розглянемо ще кілька прикладів використання вбудованих у Python функцій для роботи з рядками. Створимо рядкову змінну з таким вмістом:
>>> setup = 'beetles buzzing over cherries...'Видалимо символи . з обох кінців рядка за допомогою функції strip():
Функції rstrip() і lstrip() видаляють пропуски, а також символи нового рядка і табуляцію відповідно в кінці і на початку рядка.
|
>>> setup.strip('.')
'beetles buzzing over cherries'
>>> setup
'beetles buzzing over cherries...'
Оскільки рядки незмінні, рядок setup не змінюється. Відбувається все так: отримують значення змінної setup, виконують над цим значенням деякі дії, а потім повертають результат як новий рядок.
|
Напишемо всі слова з великої літери за допомогою функції title():
>>> setup.title()
'Beetles Buzzing Over Cherries...'Напишемо перше слово з великої літери, а всі інші символи - малими літерами за допомогою функції capitalize():
>>> setup.capitalize()
'Beetles buzzing over cherries...'Напишемо всі слова великими літерами за допомогою функції upper():
>>> setup.upper()
'BEETLES BUZZING OVER CHERRIES...'Напишемо всі слова малими літерами за допомогою функції lower():
>>> setup.lower()
'beetles buzzing over cherries...'Змінимо регістр літер за допомогою функції swapcase():
>>> setup = 'Beetles buzzing over Cherries...'
>>> setup.swapcase()
'bEETLES BUZZING OVER cHERRIES...'Для вирівнювання рядків використовуються кількість місць для рядка і наступні функції: center(), ljust(), rjust().
Вирівнювання рядка по центру на проміжку із 40 місць:
>>> setup.center(40)
' beetles buzzing over cherries... 'Вирівнювання рядка за лівим краєм на проміжку із 40 місць:
>>> setup.ljust(40)
'beetles buzzing over cherries... 'Вирівнювання рядка за правим краєм на проміжку із 40 місць:
>>> setup.rjust(40)
' beetles buzzing over cherries...'3.3.13. Заміна символів: функція replace()
Ви можете використовувати функцію replace() для того, щоб замінити один підрядок на інший.
Для цього треба передати у цю функцію «старий підрядок» (який треба замінити), «новий підрядок» (яким треба замінити) і кількість входжень старого підрядка:
рядок.replace(старий рядок, новий підрядок, кількість замін)
Якщо не записувати останній аргумент (кількість замін), буде проведена заміна усіх входжень. Наприклад:
>>> language = 'I told my friend, "Python is my favorite language! I love to program in Python!"'
>>> language.replace('Python', 'Ruby')
'I told my friend, "Ruby is my favorite language! I love to program in Ruby!"'Зробимо заміну символа ! на !!! для одного і двох входжень відповідно:
>>> language.replace('!', '!!!', 1)
'I told my friend, "Python is my favorite language!!! I love to program in Python!"'
>>> language.replace('!', '!!!', 2)
'I told my friend, "Python is my favorite language!!! I love to program in Python!!!"'
Поширені методи рядків (функції для роботи з текстовими рядками) у Python можна переглянути у таблиці Додаток C: Методи: рядкові величини.
|
3.4. Введення даних з клавіатури
Для виконання ряду програм, зазвичай, потрібна деяка інформація, яку повинен ввести користувач. Простий приклад: припустимо, користувач хоче дізнатися, чи достатній його вік для голосування. Програма повинна отримати від користувача значення - його вік; коли у програми з’являться дані, вона може порівняти їх з віком, що дає право на голосування, і повідомити результат.
Давайте дізнаємось, як отримати від користувача вхідні дані, щоб програма могла працювати з ними.
3.4.1. Функція input()
Для отримання вхідних даних у програмах використовується функція input().
|
Функція input() призупиняє виконання програми і чекає, поки користувач введе деякий текст і натисне Enter.
Кожен раз, коли у вашій програмі використовується функція input(), ви повинні включати зрозумілу підказку-текст (наприклад, "Please enter your name: "), яка точно повідомить користувачеві, яку інформацію від нього хочуть отримати.
Наприклад, для даного фрагменту коду додайте пробіл в кінці підказки (після двокрапки), щоб відокремити підказку від даних, що вводяться користувачем, і чітко показати, де повинен вводитися текст:
>>> name = input("Please enter your name: ")
Please enter your name: Alex
>>> print("Hello, " + name + "!")
Hello, Alex!При використанні функції input() Python інтерпретує всі дані, введенні користувачем, як рядок. У наступному сеансі інтерпретатора програма запитує у користувача вік:
>>> age = input("How old are you? ")
How old are you? 25
>>> age
'25'Користувач вводить число 25, але, коли ми запитуємо у Python значення age, виводиться '25' - введене число в рядковому форматі. Лапки, в яких знаходяться дані, вказують на те, що Python інтерпретує введення як рядок.
Спроба використовувати введені дані як число викликає помилку:
>>> age >= 18
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: str() >= int()Коли ви намагаєтеся порівняти введені дані з числом, Python видає помилку, тому що не може порівняти рядок з числом.
Проблему можна вирішити за допомогою функції int(), яка інтерпретує рядок як ціле числове значення.
Функція int() перетворює рядкове представлення числа в ціле число.
|
>>> age = input("How old are you? ")
How old are you? 25
>>> age = int(age)
>>> age >= 18
TrueУ цьому прикладі введене число 25 інтерпретується як рядок, але потім він перетвориться в числове представлення викликом int(). Тепер Python може перевірити умову: порівняти змінну age (яка тепер містить ціле числове значення 25) з 18.
Якщо необхідно отримати число з рухомою крапкою із введеного рядка, використовують функцію float().
Функція float() перетворює рядкове представлення числа в число з рухомою крапкою.
|
>>> value = float(input('Enter a number: '))
Enter a number: 45.5
>>> value
45.5В даному випадку було використаний синтаксис, що поєднує послідовне виконання двох функцій input() і float(): спочатку відбулося введення значення, далі інтерпретація значення як рядка, а потім перетворення рядка у число з рухомою крапкою.
3.5. Завдання
3.5.1. Контрольні запитання
-
Які з наведених нижче елементів є операторами, а які - значеннями?
*
'Hello'
-45.7
-
/
5
+-
Що із наведеного нижче є змінною, а що - рядком?
letter
'letter'-
Що буде містити змінна
resultпісля виконання наступних інструкцій?
result = 20
result += 5-
Якими будуть результати (у місці
...) обчислення двох наступних виразів?
>>> 'snowflake' + 'snowflakesnowflake'
...
>>> 'snowflake' * 3
...-
Чому виникає помилка при спробі обчислення поданого нижче виразу? Як виправити цю помилку?
print('I got' + 12 + 'points')-
Які будуть результати обчислення таких виразів:
"I'd like to travel to Shanghai"[0:21]
"I'd like to travel to Shanghai"[:21]
"I'd like to travel to Shanghai"[22:]
"I'd like to travel to Shanghai"[12:18]
"I'd like to travel to Shanghai".upper()
"I'd like to travel to Shanghai".upper().lower()
"I'd like to travel to Shanghai".split()
'>>'.join("I'd like to travel to Shanghai".split())3.5.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Скільки секунд в годині? Використайте інтерактивний інтерпретатор як калькулятор і помножте кількість секунд у хвилині (
60) на кількість хвилин у годині (теж60). -
Присвойте результат обчислення попереднього завдання (кількість секунд в годині) змінній, яка називається
seconds_per_hour. -
Скільки секунд у добі? Використайте змінну
seconds_per_hour. -
Знову порахуйте кількість секунд у добі, але на цей раз збережіть результат у змінній
seconds_per_day. -
Розділіть значення змінної
seconds_per_dayна значення змінноїseconds_per_hour. Використайте ділення з рухомою крапкою (/). -
Розділіть значення змінної
seconds_per_dayна значення змінноїseconds_per_hour. Використайте цілочисельне ділення (//). Чи збігається результат з відповіддю на попередню вправу, якщо не враховувати символи.0в кінці? -
Напишіть операції додавання, віднімання, множення і ділення, результатом яких є число
12. Ви повинні написати чотири рядки коду, які виглядають приблизно так:print(5 + 7). Результатом повинні бути чотири рядки, у кожному з яких виводиться число12. -
Збережіть своє улюблене число у змінній, а потім за допомогою змінної створіть повідомлення для виведення цього числа. Виведіть це повідомлення.
-
Збережіть ім’я користувача у змінній і виведіть його у нижньому регістрі, у верхньому регістрі і зі зміною регістру літер.
-
Змінна
poemмістить фрагмент тексту віршаContra spem speroЛесі Українки :
>>> poem = '''Yes, I'll smile, indeed, through tears and weeping
... Sing my songs where evil holds its sway,
... Hopeless, a steadfast hope forever keeping,
... I shall live! You thoughts of grief, away!'''Використовуючи офіційну документацію , відшукайте функції для роботи з рядками, які дозволяють отримати вказані нижче відповіді на кожне із запитань. У пропущених місцях (...) впишіть ці функції і перевірте результат їхнього виконання в інтерактивному інтерпретаторі.
Отримати перші 16 символів (їх індекси лежать у діапазоні від 0 до 15).
>>> ...
"Yes, I'll smile"Скільки символів містить цей вірш? (Пропуски і символи нового рядка враховуються.)
>>> ...
178Чи починається вірш з буквосполучення Yes?
>>> ...
TrueВірш закінчується словосполученням I shall live!?
>>> ...
FalseЗнайти індекс першого входження символа коми ,.
>>> word = ','
>>> ...
3Знайти індекс останнього входження символа коми ,.
>>> ...
171Скільки разів зустрічається символ коми ,?
>>> ...
7Всі символи вірша є літерами або цифрами?
>>> ...
False
В разі виникненя труднощів у пошуку відповідних функцій для роботи з рядками, скористайтеся відомими назвами функцій: len(), startswith(), endswith(), find(), rfind(), count(), isalnum().
|
3.5.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Збережіть будь-яке повідомлення у змінній і виведіть це повідомлення. Потім замініть значення змінної іншим повідомленням і виведіть нове повідомлення. Програму збережіть у файлі, ім’я якої підпорядковується стандартним правилам
Pythonпо використанню малих літер і символів підкреслення - наприклад,simple_messages.py. -
Збережіть ім’я користувача у змінній і виведіть повідомлення, призначене для конкретної людини. Повідомлення повинно бути, наприклад, таким:
"Hello, Sasha, would you like to learn some Python today?". -
Знайдіть відому цитату, яка вам подобається. Збережіть ім’я автора вислову у змінній
famous_person. Cкладіть повідомлення і збережіть його у новій змінній з ім’ямmessage. Виведіть своє повідомлення. Результат повинен виглядати приблизно так (включаючи лапки):Albert Einstein once said, "A person who never made a mistake never tried anything new.". -
Збережіть ім’я користувача у змінній і додайте на початку і у кінці імені кілька пропусків. Простежте за тим, щоб кожна керуюча послідовність (
\tі\n) зустрічалася принаймні один раз. Виведіть ім’я, щоб було видно пропуски на початку і у кінці рядка. Потім виведіть його знову з використанням кожної з функцій видалення пропусків:lstrip(),rstrip()іstrip(). -
Використайте функцію
print()для виведення повної домашньої адреси. У першому рядку виведіть власне ім’я та прізвище. У кожному наступному рядку виведіть окремі елементи адреси (країна, індекс, назва населеного пункту, вулиця, номер будинку тощо). -
Виконайте переведення одиниць вимірювання відстаней. Значення відстані вказано у метрах. У кожному новому рядку програма виводить значення відстані, представлене у: дюймах, футах, милях, ярдах тощо. Числові дані на екрані мають бути у відформатованому вигляді: два знаки після десяткової крапки. Використайте функцію
format(). Потрібні значення одиниць вимірювання знайдіть у мережі Інтернет. -
Обчисліть тривалість якоїсь події. Припустимо, учнівські канікули тривали кілька днів. На екран треба вивести у відформатованому вигляді (вирівнювання за лівим краєм, ширина поля:
10знаків) загальну тривалість цієї події у годинах, хвилинах, секундах. -
Виконайте перетворення значення температури у градусах Цельсія (
C) для інших температурних шкал: Фаренгейта (F) і Кельвіна (K). Програма повинна відображати еквівалентну температуру у градусах Фаренгейта (F = 32 + 9/5 * C). Програма повинна відображати еквівалентну температуру у градусах Кельвіна (K = C + 273,15). Результати потрібно вивести на екран у відформатованому вигляді: з використанням двох знаків після десяткової крапки, мінімальною довжиною поля (15), вирівнюванням по центру. Зверніть увагу, у дійсних числах для розділення дробової і цілої частин використовують крапку. -
Виконайте розкладання чотирицифрового цілого числа і виведіть на екран суму цифр у числі. Наприклад, якщо обрали число
6259, то програма повинна вивести на екран повідомлення:6 + 2 + 5 + 9 = 22. Використайте функціюformat()для відображення результату абоf-рядки. -
За координатами широти і довготи двох точок на Землі у градусах визначте відстань між ними у кілометрах. Нехай (
x1,y1) і (x2,y2) є кординатами широти і довготи (у градусах) двох точок на земній поверхні. Відстань між цими точками у кілометрах обчислюється так:6371.032 × arccos(sin(x1) × sin(x2) + cos(x1) × cos(x2) × cos(y1 - y2)). Значення6371,032- це середній радіус Землі у кілометрах. Тригонометричні функціїPythonпрацюють з радіанами. Як результат, необхідно перетворити значення координат із градусів у радіани перед обчисленням відстані за формулою. Модульmathмістить функцію з ім’ямradians(), яка переводить градуси у радіани. Переведення можна зробити і за формулою, на зразокx1 = x1 × pi/180, деpi- число Пі. Знайдіть відстань між двома містами Пекін (39.9075000, 116.3972300) і Київ (50.4546600, 30.5238000) і виведіть значення на екран. Значення відстані повинне відображатися у відформатованому вигляді: з використанням трьох знаків після десяткової крапки, мінімальною довжиною поля (10), вирівнюванням за правим краєм. На даному сайті знайдіть значення координат у десяткових градусах ще для кількох пар міст на вибір і визначте відстань у кілометрах між ними. Перевірте правильність визначення відстаней між містами, використовуючи один із сервісів вищезгаданого сайту. -
Змініть код програм із пунктів
6-9таким чином, щоб дані у програми могли вводитись користувачем із клавіатури. Для модифікації коду використовуйте функціюinput(). -
Виберіть дві програми з написаних вами і додайте у кожну хоча б один коментар. Якщо ви не знаєте, що написати у коментарях, додайте своє ім’я і поточну дату на початку коду. Потім додайте один коментар з описом того, що робить програма.
4. Списки і кортежі
Списки дозволяють зберігати в одному місці взаємопов’язані дані, скільки б їх не було - кілька елементів або кілька мільйонів елементів. Робота зі списками відноситься до числа найбільш видатних можливостей Python.
У список можна додати нові елементи, а також видалити або перезаписати існуючі. Одне і те ж значення може зустрічатися в списку кілька разів.
Що таке список? Список можна створити для зберігання букв алфавіту, цифр від 0 до 9 або рядків, наприклад, імен всіх членів вашої родини. У списку можна зберігати будь-яку інформацію, причому дані в списку навіть не зобов’язані бути якось пов’язані один з одним. Так як список, зазвичай, містить більше одного елемента, рекомендується надавати спискам імена у множині: letters, digits, names і т. д.
Поширені методи списків (функції для роботи із списками) у Python можна переглянути у таблиці Додаток C: Методи: списки.
|
4.1. Створення списків
У мові Python список позначається квадратними дужками [], а елементи списку розділяються комами. Наприклад, так створюється список з назвами моделей автомобілів:
>>> cars = ['Alfa Romeo', 'Volvo', 'Lamborghini', 'BMW', 'Toyota']
>>> print(cars)
['Alfa Romeo', 'Volvo', 'Lamborghini', 'BMW', 'Toyota']Інші приклади списків:
>>> empty_list = [] (1)
>>> weekdays = ['Monday', 'Friday', 'Wednesday', 'Thursday', 'Friday'] (2)
>>> animals = ['camels', 'bats', 'elephants', 'dolphins', 'bears'] (3)
>>> first_names = ['Mira', 'John', 'Terry', 'John', 'Michael'] (4)
>>> another_empty_list = list() (5)
>>> another_empty_list
[]-
Створення порожнього списку з ім’ям
empty_list. -
Створення списку днів тижня з ім’ям
weekdays. -
Створення списку тварин з ім’ям
animals. -
Створення списку імен з назвою
first_names. -
Створення порожнього списку
another_empty_listза допомогою функціїlist().
Списки у Python можна порівняти із масивами у інших мовах програмування.
|
Якщо присвоїти один список більш ніж одній змінній, то зміни у списку в одному місці спричинять за собою його зміни в інших, як показано далі:
>>> a = [1, 2, 3]
>>> a
[1, 2, 3]
>>> b = a
>>> b
[1, 2, 3]
>>> a[0] = 'surprise'
>>> a
['surprise', 2, 3]
>>> b
['surprise', 2, 3]
>>> b[0] = 'I hate surprises'
>>> b
['I hate surprises', 2, 3]
>>> a
['I hate surprises', 2, 3]Значення списку можна скопіювати в незалежний новий список за допомогою одного з наступних способів:
-
функції
copy() -
функції
list() -
розділенням списку за допомогою
[:]
Наприклад, оригінальний список буде присвоєний змінній a, а інші списки - b, c, d - будуть копіями списку a:
>>> a = [1, 2, 3]
>>> b = a.copy()
>>> c = list(a)
>>> d = a[:]b, c, d - це нові об’єкти, що мають свої значення, які не пов’язані з оригінальним списком елементів [1, 2, 3], на який посилається змінна a. Зміни в a не впливають на копії b, c, d:
>>> a[0] = 'lists store any information, not just integer numbers'
>>> a
['lists store any information, not just integer numbers', 2, 3]
>>> b
[1, 2, 3]
>>> c
[1, 2, 3]
>>> d
[1, 2, 3]
>>>
При створенні копій списку, використовуючи функції copy() і list() або конструкції [:], зміни в оригінальному списку не впливають на зміни у списках-копіях; списки-копії є вже новими об’єктами.
|
4.2. Довжина списку
Функція len() повертає кількість елементів списку.
|
Для прикладу, визначимо кількість елементів у поданому списку з назвами планет:
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> len(planets)
54.3. Перетворення типів: функція list()
Функція list() перетворює інші типи даних у список.
|
У наступному прикладі рядок перетворюється у список, що складається з односимвольних рядків:
>>> list('sun')
['s', 'u', 'n']Щоб перетворити рядок у список можна також скористатися функцією split(), вказавши рядок-розділювач:
>>> mybirthday = '3/4/1981'
>>> mybirthday.split('/')
['3', '4', '1981']
Функція split() перетворює рядок у список елементів, розділених іншим рядком-розділювачем.
|
Якщо в рядку міститься кілька входжень рядка-розділювача поспіль, то в якості елемента списку ви отримаєте порожній рядок:
>>> result = 'a|b||c|d|||e'
>>> result.split('|')
['a', 'b', '', 'c', 'd', '', '', 'e']
Для перетворення списка у рядок, використовується функція join().
|
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> ', '.join(planets)
'Mercury, Jupiter, Earth, Mars, Venus'4.4. Доступ до елементів списку
Списки є впорядкованими наборами даних, тому для доступу до будь-якого елементу списку слід повідомити Python позицію (індекс) потрібного елемента.
Індекси приймають тільки цілочисельні значення. Щоб звернутися до елементу у списку, вкажіть ім’я списку, за яким слідує індекс елемента в квадратних дужках.
Як і для рядків, зі списку можна отримати конкретне значення, вказавши його індекс (якщо вказати позицію, яка знаходиться перед списком або після нього, буде згенеровано помилку):
>>> cars = ['Alfa Romeo', 'Volvo', 'Lamborghini', 'BMW', 'Toyota']
>>> print(cars[1])
Volvo
>>> print(cars[4])
Toyota
>>> print(cars[0])
Alfa Romeo
>>> print(cars[-1])
Toyota
>>> print(cars[-2])
BMW
>>> print(cars[5])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
Якщо необхідно дізнатися індекс елемента у списку за його значенням, використовується функція index().
|
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> planets.index('Earth')
24.5. Списки списків
Списки можуть містити елементи різних типів, включаючи інші списки. Створимо три списки і помістимо їх в четвертий список:
>>> text_editors = ['Atom', 'Sublime Text']
>>> programming_language = ['Python', 'C', 'JavaScript']
>>> programmers = ['Guido van Rossum', 'Dennis Ritchie', 'Brendan Eich']
>>> all_info = [text_editors, 'code', programming_language, programmers]
>>> all_info
[['Atom', 'Sublime Text'], 'code', ['Python', 'C', 'JavaScript'], ['Guido van Rossum', 'Dennis Ritchie', 'Brendan Eich']]
>>>Поглянемо на перший і третій елементи новоствореного списку all_info - вони є списками:
>>> all_info[0]
['Atom', 'Sublime Text']
>>> all_info[2]
['Python', 'C', 'JavaScript']Щоб отримати із списку all_info, наприклад, перший елемент списку programmers, вказується 2 індекса: [3] - вказує на четвертий елемент списку all_info, а [0] - вказує на перший елемент внутрішнього списку programmers:
>>> all_info[3][0]
'Guido van Rossum'4.6. Зміна елементів списку
На відміну від рядків список можна змінювати:
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> planets[2] = 'Saturn'
>>> planets
['Mercury', 'Jupiter', 'Saturn', 'Mars', 'Venus']4.7. Розділення і зворотний порядок елементів списку
Використовуючи розділення (зріз) списку, можна витягти зі списку підпослідовність, що також буде списком:
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> planets[0:3]
['Mercury', 'Jupiter', 'Earth']
>>> planets[::2]
['Mercury', 'Earth', 'Venus']
>>> planets[::-3]
['Venus', 'Jupiter']
>>> planets[::-1] # розміщення елементів списку у зворотному порядку
['Venus', 'Mars', 'Earth', 'Jupiter', 'Mercury']4.8. Додавання елемента у список
Традиційний спосіб додавання елементів у список - виклик функції append(), щоб додати елемент в кінець списку:
>>> planets.append('Uranus')
>>> planets
['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus', 'Uranus']
Функція append() додає елементи лише в кінець списку. Коли потрібно додати елемент у конкретну позицію, використовуйте функцію insert().
|
Якщо вказати позицію 0, елемент буде додано в початок списку. Якщо позиція знаходиться за межами списку, елемент буде додано в кінець списку, як і у випадку з функцією append(), тому вам не потрібно турбуватися про те, що Python згенерує помилку:
>>> planets.insert(3, 'Neptune')
>>> planets
['Mercury', 'Jupiter', 'Earth', 'Neptune', 'Mars', 'Venus', 'Uranus']
>>> planets.insert(10, 'Unknown planet')
>>> planets
['Mercury', 'Jupiter', 'Earth', 'Neptune', 'Mars', 'Venus', 'Uranus', 'Unknown planet']4.9. Об’єднання спиcків
Для об’єднання одного списку з іншим використовують функцію extend().
|
>>> planets = ['Earth', 'Mars']
>>> satellites = ['Moon', 'Deimos', 'Phobos']
>>> planets.extend(satellites)
>>> planets
['Earth', 'Mars', 'Moon', 'Deimos', 'Phobos']Можна також використовувати операцію += для об’єднання списків:
>>> planets = ['Earth', 'Mars']
>>> satellites = ['Moon', 'Deimos', 'Phobos']
>>> planets += satellites
>>> planets
['Earth', 'Mars', 'Moon', 'Deimos', 'Phobos']Якщо використовувати функцію append(), список satellites був би доданий як один елемент списку, замість того, щоб об’єднати його елементи зі списком planets:
>>> planets = ['Earth', 'Mars']
>>> satellites = ['Moon', 'Deimos', 'Phobos']
>>> planets.append(satellites)
>>> planets
['Earth', 'Mars', ['Moon', 'Deimos', 'Phobos']]Це ще раз демонструє, що список може містити елементи різних типів.
4.10. Видалення елементів зі списку
Для видалення елементів зі списку користуються функцією del().
|
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> del planets[-1]
>>> planets
['Mercury', 'Jupiter', 'Earth', 'Mars']| Коли видаляється заданий елемент, всі інші елементи, які йдуть слідом за ним, зміщуються вліво, щоб зайняти місце видаленого елемента, а довжина списку зменшується на одиницю. |
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> planets[3]
'Mars'
>>> del planets[3]
>>> planets
['Mercury', 'Jupiter', 'Earth', 'Venus']
>>> planets[3]
'Venus'
>>>
Зі списку можна видалити елемент не лише за індексом, а за значенням, використовуючи функцію remove().
|
Це той випадок, коли не відомо у якій позиції знаходиться елемент, але відоме його значення:
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> planets.remove('Jupiter')
>>> planets
['Mercury', 'Earth', 'Mars', 'Venus']
Можна видалити елемент зі списку і, водночас, отримати його за допомогою функції pop().
|
Якщо викликати цю функцію і вказати деякий зсув, вона поверне елемент, що знаходиться в заданій позиції; якщо аргумент не вказано, буде використано значення -1, як у наступному прикладі:
>>> planets = ['Mercury', 'Jupiter', 'Earth', 'Mars', 'Venus']
>>> planets.pop()
'Venus'
>>> planets
['Mercury', 'Jupiter', 'Earth', 'Mars']
>>> planets.pop(1)
'Jupiter'
>>> planets
['Mercury', 'Earth', 'Mars']4.11. Чи є елемент у списку?
В Python наявність елемента у списку перевіряється за допомогою оператора in:
>>> countries = ['England', 'France', 'Italy', 'Ukraine', 'Poland']
>>> 'Poland' in countries
True
>>> 'Hungary' in countries
FalseДля перевірки на відсутність елемента у списку користуються поєднанням операторів not in:
>>> countries = ['England', 'France', 'Italy', 'Ukraine', 'Poland']
>>> 'Ukraine' not in countries # 'Ukraine' немає у списку countries? Хибність, такий елемент є у списку
False
>>> 'Portugal' not in countries # 'Portugal' немає у списку countries? Істина, такого елемента у списку немає
True4.12. Кількість значень у списку
Щоб визначити, скільки разів якесь значення зустрічається у списку, використовується функція count().
|
>>> fruits = ['blueberry', 'grape', 'orange', 'plum', 'pear', 'blueberry', 'pear', 'melon', 'pear']
>>> fruits.count('grape')
1
>>> fruits.count('peach')
0
>>> fruits.count('pear')
3
>>> fruits.count('blueberry')
24.13. Сортування списків
Для зміни порядку розташування елементів списку за їхнім значенням у Python є дві функції:
-
sort()- сортує сам список (змінює його) -
sorted()- повертає відсортовану копію списку (без зміни оригінального списку)
| Якщо елементи списку є числами, вони за замовчуванням сортуються за зростанням. Якщо вони є рядками, то сортуються в алфавітному порядку. |
Для даного списку:
>>> clothes = ['shirt', 'hat', 'jeans', 'trainers']
>>> sorted_clothes = sorted(clothes)
>>> sorted_clothes
['hat', 'jeans', 'shirt', 'trainers']
>>> clothes
['shirt', 'hat', 'jeans', 'trainers']sorted_clothes - це копія списку clothes, її створення не змінило оригінальний список clothes. А використання функції sort() змінює сам список clothes:
>>> clothes.sort()
>>> clothes
['hat', 'jeans', 'shirt', 'trainers']В даних прикладах усі елементи списку одного типу (рядки).
Інколи можна змішувати типи - наприклад, цілі числа і числа з рухомою крапкою, оскільки в рамках сортування вони конвертуються автоматично:
>>> numbers = [5, 3, 7.0, 4]
>>> numbers.sort()
>>> numbers
[3, 4, 5, 7.0]А от сортування списку, що містить як числа, так і рядки, викличе помилку:
>>> numbers = [3, 1, 'start', 2]
>>> numbers.sort()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'str' and 'int'
При використанні функцій sort() і sorted() вимагається, щоб усі елементи списку мали сумісні типи.
|
За замовчуванням, список сортується за зростанням, але додавши аргумент зі значенням reverse=True, список відсортується за спаданням:
>>> numbers = [5, 3, 7.0, 4]
>>> numbers.sort(reverse=True)
>>> numbers
[7.0, 5, 4, 3]4.14. Список у зворотному порядку
Щоб переставити елементи списку у зворотному порядку, використовується функція reverse().
|
>>> cars = ['bmw', 'audi', 'toyota', 'subaru']
>>> cars
['bmw', 'audi', 'toyota', 'subaru']
>>> cars.reverse()
>>> cars
['subaru', 'toyota', 'audi', 'bmw']4.15. Створення числових списків
Необхідність зберігання наборів чисел виникає у програмах по багатьом причинам. Наприклад, в комп’ютерній грі можуть зберігатися координати персонажів на екрані, таблиці рекордів, ведення рахунку тощо. У програмах обчислювального характеру завжди працюють з наборами чисел: температура, відстань, чисельність населення тощо.
Списки ідеально підходять для зберігання наборів чисел, а Python надає спеціальні засоби для ефективної роботи з числовими списками, навіть якщо список містить мільйони елементів.
Для спрощення побудови числових послідовностей використовують функцію range():
>>> numbers = list(range(1,6))
>>> numbers
[1, 2, 3, 4, 5]
Функція range() дозволяє генерувати цілочисельні послідовності у заданому діапазоні.
|
Наприклад, для побудови списку парних чисел від 1 до 10 використовується такий код:
>>> even_numbers = list(range(2,11,2))
>>> even_numbers
[2, 4, 6, 8, 10]Деякі вбудовані функції Python призначені для роботи з числовими списками. Наприклад, можна легко дізнатися мінімум, максимум і суму елементів числового списку:
>>> digits = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
>>> min(digits)
0
>>> max(digits)
9
>>> sum(digits)
454.16. Кортежі
Кортежі, як і списки, є послідовностями будь-яких елементів.
На відміну від списків кортежі є незмінними. Це означає, що не можна додати, видалити або змінити елементи кортежу після того, як він створений (наприклад, не можна знищити елементи кортежу помилково).
Для створення порожнього кортежу використовується оператор ():
>>> empty_tuple = ()
>>> empty_tuple
()Щоб створити кортеж, що містить один елемент, ставте після елемента кому. Ось так виглядає варіант для кортежів з одним елементом:
>>> сurrency_units = 'pound',
>>> сurrency_units
('pound',)При відображенні кортежу Python виводить на екран дужки.
Якщо у кортежі більше одного елемента, ставте кому після кожного з них, крім останнього:
>>> сurrency_units = 'pound', 'dollar', 'euro'
>>> сurrency_units
('pound', 'dollar', 'euro')Кортежі дозволяють присвоїти значення для кількох змінних за один раз:
>>> сurrency_units = 'pound', 'dollar', 'euro'
>>> p, d, e = сurrency_units
>>> p
'pound'
>>> d
'dollar'
>>> e
'euro'Ви можете використовувати кортежі, щоб обмінюватися значеннями за допомогою одного виразу, без застосування тимчасової змінної:
>>> network_name = 'netis'
>>> password = 'pass12345'
>>> network_name, password = password, network_name
>>> network_name
'pass12345'
>>> password
'netis'Функція перетворення tuple() створює кортежі з інших об’єктів:
>>> сurrency_units = ['pound', 'dollar', 'euro']
>>> tuple(сurrency_units)
('pound', 'dollar', 'euro')4.17. Завдання
4.17.1. Контрольні запитання
-
Що означають дужки
[]? -
У змінній
lettersміститься список['a', 'b', 'c', 'd']. Яке значення виразуletters[int('3' * 2) // 11]? -
У змінній
lettersміститься список['a', 'b', 'c', 'd']. Яке значення виразуletters[-1]? -
У змінній
lettersміститься список['a', 'b', 'c', 'd']. Яке значення виразуletters[:2]? -
У змінній
lettersміститься список[2, 4, 6, 8, 10]. Як присвоїти значення'zero'в якості третього елемента даного списку? -
У змінній
meteringміститься список[3.14, 'inch', 2.54, 'inch', True]. Яке значення виразуmetering.index('inch')? -
Як буде виглядати список, який зберігається у змінній
metering = [3.14, 'inch', 2.54, 'inch', True], після виконання командиmetering.append(99)? -
Як буде виглядати список, який зберігається у змінній
metering = [3.14, 'inch', 2.54, 'inch', True], після виконання командиmetering.remove('inch')? -
В чому різниця між функціями
append()таinsert(), передбаченими для списків? -
Назвіть способи видалення значень із списку.
-
Назвіть декілька спільних (відмінних) ознак для рядків і списків.
-
Змінні, які «зберігають» список, насправді, не зберігають в собі безпосередньо сам список. Що тоді вони містять?
-
Чим кортежі відрізняються від списків?
-
Як створити кортеж, який міститиме єдине значення у вигляді цілого числа
24? -
Як перетворити список в кортеж?
4.17.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Збережіть імена кількох своїх друзів у списку з ім’ям
names. Виведіть ім’я кожного друга, звернувшись до кожного елементу списку (по одному разу). -
Cтворіть список з типами транспортих засобів. Використайте список для виведення твердження, на зразок: «Я хотів би купити велосипед.».
-
Створіть список
years_list, що містить рік, в який ви народилися, і кожен наступний рік аж до вашого п’ятого дня народження. Наприклад, якщо ви народилися в 1995 році, список буде виглядати так:years_list = [1995, 1996, 1997, 1998, 1999, 2000]. Виведіть на екран, у якому із років, що міститься у спискуyears_list, вам виповнилося3роки? Пам’ятайте, у перший рік вам було0років. Додайте у кінець списку ще один рік і виведіть список на екран. У якому із років, перерахованих у спискуyears_list, вам було найбільше років? -
Створіть список
things, що містить три елементи:'wallet','mirror','umbrella'. Виведіть на екран той елемент у спискуthings, який має відношення до дощу, написавши його з великої літери, а потім виведіть список. Переведіть «дощовий» елемент спискуthingsу верхній регістр цілком і виведіть список. Видаліть річ, яка захищає від дощу, зі спискуthings, а потім виведіть список на екран. -
Створіть список, який називається
languagesі містить елементи'Georgian','Estonian'і'Ukrainian'. Напишіть останній елемент спискуlanguagesз малої літери, потім «переверніть» його і напишіть з великої літери. -
Збережіть кілька понять, пов’язаних з комп’ютерами та Інтернетом, у кортежі і у списку. Назвіть відповідно їх
hardware(кортеж) іsoftware(список). Виведіть усі назви по черзі. Спробуйте замінити один з елементів у списку і у кортежі, і зробіть висновок щодо можливості зміни елементів для цих двох типів.
4.17.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Збережіть назви мов світу (
Ukrainian,French,Bulgarian,Norwegian,Latvianабо інші) у списку. Простежте за тим, щоб елементи у списку не зберігались в алфавітному порядку. Застосуйте функціїsorted(),reverse(),sort()до списку. Виведіть список на екран до і після використання кожної із функцій. -
На вхід програми подається один рядок з цілими числами. Числа розділені пропусками. Необхідно вивести суму цих чисел. Наприклад, якщо був введений рядок чисел
2 -1 9 6, то результатом роботи програми буде їх сума16. -
Дано список з такими елементами:
cities = ['Budapest', 'Rome', 'Istanbul', 'Sydney', 'Kyiv', 'Hong Kong']. Сформуйте з елементів списку повідомлення, у якому перед останнім елементом буде вставлено словоand. Наприклад, у нашому випадку, повідомлення буде таким:Budapest, Rome, Istanbul, Sydney, Kyiv and Hong Kong. Програма має працювати з будь-якими списками, довжина яких є6. -
Необхідно зчитати рядок з
5цифр, розділених пропусками, і зберегти кожну цифру у список. Створіть копію списку із впорядкованими елементами у зворотному порядку. Виведіть число, яке утворюється об’єднанням елементів нового списку. -
Поміркуйте над тим, яку інформацію можна було б зберігати у списку. Наприклад, створіть список професій, видів спорту, членів родини, назви океанів тощо, а потім викличте кожну функцію для роботи зі списками, яка була згадана у цьому розділі, хоча б один раз.
-
Виконайте візуалізацію структури коду програми. Використайте у візуалізації структури елементи кортежу
keywords = ('for', 'if', 'else', 'in', ':'). У процесі виведення структури коду на екран, враховуйте відступи рядків від лівого краю, у розрахунку один відступ -4пропуски. Вигляд структури коду має бути таким:
for each token in the postfix expression :
if the token is a number :
print('Convert it to an integer and add it to the end of values')
else
print('Append the result to the end of values')5. Словники і множини
Словники - структури даних, призначені для об’єднання взаємозалежної інформації.
Словники дозволяють моделювати різноманітні реальні об’єкти. Наприклад, можна створити словник, який описує об’єкт «людина», і зберегти у ньому скільки завгодно інформації про цю людину. Це може бути ім’я, вік, місце проживання, професія і будь-які інші атрибути.
Часто у словниках зберігаються будь-які два види інформації, здатні утворити пари: список слів і їх значень, список країн та їх столиць, список днів тижня і значення температур тощо.
Для кожного значення словника вказується пов’язаний з ним унікальний ключ. Таким ключем в основному служить рядок, але ключ може бути об’єктом одного з незмінних типів: булевим значенням, цілим числом, числом з рухомою крапкою, кортежем тощо.
Мета словника - забезпечити швидкий пошук по ключу для отримання значення, пов’язаного з цим ключем.
Словники можна змінювати. Це означає, що можна додати, видалити і змінити елементи, які мають вигляд «ключ: значення». Якщо ключ визначений, змінити його не можна.
Прикладом послідовностей «ключ: значення» є послідовності виду:
-
Кремній: 28, Карбон: 12
-
Перемог: 12, Поразок: 7, Нічиїх: 3
Перший елемент кожної послідовності застосовується як ключ, а другий - як значення.
В інших мовах програмування словники можуть називатися асоціативними масивами, хешами або хеш-таблицею. В Python словник має назву dict.
|
Поширені методи словників (функції для роботи із словниками) у Python можна переглянути у таблиці Додаток C: Методи: словники.
|
5.1. Створення словника
Найпростішим словником є порожній словник, що не містить ні ключів, ні значень, і створюється за допомогою оператора {}:
>>> empty_dict = {}
>>> empty_dict
{}Щоб створити словник зі значеннями, потрібно помістити у фігурні дужки {} пари «ключ: значення», розділені комами:
>>> mydog = {'name': 'Australian Shepherd', 'training': '5', 'intelligence': 5, 'type': 'Companion'}
>>> mydog
{'intelligence': 5, 'training': '5', 'name': 'Australian Shepherd', 'type': 'Companion'}5.2. Перетворення типів: функція dict()
Функція dict() використовується для перетворення послідовностей з двох значень у словник.
|
Якщо передати функції dict() об’єкт couple (список, який містить списки, що складаються з двох елементів), то вона поверне словник:
>>> couple = [ ['a', 'b'], ['c', 'd'], ['e', 'f'] ]
>>> dict(couple)
{'e': 'f', 'c': 'd', 'a': 'b'}У даному прикладі також повертається словник, коли функція dict() отримує список пар кортежів:
>>> info = dict([('name', 'Alex'), ('age', 38)])
>>> info
{'name': 'Alex', 'age': 38}5.3. Додавання і зміна елементів словника
Додати елемент в словник досить легко. Потрібно просто звернутися до елементу за його ключем і присвоїти йому значення.
Якщо ключ вже існує у словнику, поточне значення буде замінено новим. Якщо ключ новий, то він і вказане значення будуть додані в словник.
Створимо словник, що містить імена розробників популярних мов програмування, використовуючи назви мов в якості ключів, а імена та прізвища розробників - як значення:
>>> languages_programmers = {
... 'JavaSript': 'Brendan Eich',
... 'Python': 'Guido van Rossum',
... 'Ruby': 'Yukihiro Matsumoto',
... 'PHP': 'Rasmus Lerdorf',
... 'Scala': 'Martin Odersky'
... }
>>> languages_programmers
{'Python': 'Guido van Rossum', 'Scala': 'Martin Odersky', 'Ruby': 'Yukihiro Matsumoto', 'PHP': 'Rasmus Lerdorf', 'JavaSript': 'Brendan Eich'}Додамо у словник інформацію про ще одного видатного вченого-інформатика (розробника мови C):
>>> languages_programmers['C'] = 'Dennis MacAlistair Ritchie'
>>> languages_programmers
{'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'PHP': 'Rasmus Lerdorf', 'Ruby': 'Yukihiro Matsumoto', 'C': 'Dennis MacAlistair Ritchie'}Ім’я розробника доданого останнього значення занадто довге (складається з трьох слів). Виправимо це:
>>> languages_programmers['C'] = 'Dennis Ritchie'
>>> languages_programmers
{'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'PHP': 'Rasmus Lerdorf', 'Ruby': 'Yukihiro Matsumoto', 'C': 'Dennis Ritchie'}Використовуючи один і той же ключ ('C'), ми замінили початкове значення 'Dennis MacAlistair Ritchie' на 'Dennis Ritchie'.
| Ключі у словнику повинні бути унікальними. Перед створенням словника, поміркуйте, які значення можуть бути ключами. |
Якщо ви застосовуєте ключ більш ніж один раз, зараховується лише останнє значення:
>>> languages_programmers = {
... 'JavaSript': 'Brendan Eich',
... 'Python': 'Guido van Rossum',
... 'C': 'Dennis MacAlistair Ritchie',
... 'Ruby': 'Yukihiro Matsumoto',
... 'PHP': 'Rasmus Lerdorf',
... 'Scala': 'Martin Odersky',
... 'C': 'Dennis Ritchie'
... }
>>> languages_programmers
{'PHP': 'Rasmus Lerdorf', 'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'C': 'Dennis Ritchie', 'Ruby': 'Yukihiro Matsumoto'}5.4. Об’єднання словників
Використовуючи функцію update(), можна скопіювати ключі і значення з одного словника в інший.
|
Визначимо словник languages_programmers, що містить імена відомих розробників мов програмування:
>>> languages_programmers = {
... 'JavaSript': 'Brendan Eich',
... 'Python': 'Guido van Rossum',
... 'Ruby': 'Yukihiro Matsumoto',
... 'PHP': 'Rasmus Lerdorf',
... 'Scala': 'Martin Odersky',
... 'C': 'Dennis Ritchie'
... }
>>> languages_programmers
{'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'PHP': 'Rasmus Lerdorf', 'Ruby': 'Yukihiro Matsumoto', 'C': 'Dennis Ritchie'}Крім того, у нас є інший словник others, що містить імена інших розробників:
>>> others = {'C++': 'Bjarne Stroustrup', 'Swift': 'Chris Lattner'}Додамо розробників словника others у основний словник languages_programmers:
>>> languages_programmers.update(others)
>>> languages_programmers
{'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'PHP': 'Rasmus Lerdorf', 'Ruby': 'Yukihiro Matsumoto', 'Swift': 'Chris Lattner', 'C': 'Dennis Ritchie', 'C++': 'Bjarne Stroustrup'}Що станеться, якщо в другому словнику будуть знаходитися такі ж ключі, що і в першому? «Переможе» значення з другого словника:
>>> first = {'a': 10, 'b': 20}
>>> second = {'b': 'other'}
>>> first.update(second)
>>> first
{'a': 10, 'b': 'other'}5.5. Видалення елементів із словника
Скасуємо додавання у словник розробників останніх двох елементів, звернувшись до словника за ключами:
>>> del languages_programmers['Swift']
>>> languages_programmers
{'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'PHP': 'Rasmus Lerdorf', 'Ruby': 'Yukihiro Matsumoto', 'C': 'Dennis Ritchie', 'C++': 'Bjarne Stroustrup'}
>>> del languages_programmers['C++']
>>> languages_programmers
{'Scala': 'Martin Odersky', 'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'PHP': 'Rasmus Lerdorf', 'Ruby': 'Yukihiro Matsumoto', 'C': 'Dennis Ritchie'}
Щоб видалити усі ключі і значення зі словника, слід скористатися функцією clear() або просто присвоїти порожній словник заданому імені.
|
Перший спосіб повного очищення словника:
>>> languages_programmers.clear()
>>> languages_programmers
{}Другий спосіб повного очищення словника:
>>> languages_programmers = {}
>>> languages_programmers
{}5.6. Чи є ключ у словнику?
Якщо ви хочете дізнатися, чи міститься в словнику якийсь ключ, використовуйте ключевое слово in.
Знову визначимо словник languages_programmers, але на цей раз з меншою кількістю елементів:
>>> languages_programmers = {'JavaSript': 'Brendan Eich', 'Python': 'Guido van Rossum', 'Ruby': 'Yukihiro Matsumoto'}
>>> 'Ruby' in languages_programmers
True
>>> 'Scala' in languages_programmers
False5.7. Значення із словника
Щоб отримати певне значення зі словника, ви вказуєте словник і ключ для цього значення:
>>> languages_programmers['Ruby']
'Yukihiro Matsumoto'Якщо ключа у словнику немає, буде згенеровано помилку:
>>> languages_programmers['PHP']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'PHP'
Щоб уникати помилок при роботі із словником, спочатку треба перевірити чи є ключ у словнику або скористатися функцією get().
|
Ви вказуєте словник, ключ і опціональне значення. Якщо ключ існує, ви отримаєте пов’язане з ним значення:
>>> languages_programmers.get('Ruby')
'Yukihiro Matsumoto'Якщо такого ключа немає, отримують опціональне значення, якщо воно було визначено:
>>> languages_programmers.get('PHP', 'PHP not in dictionary.')
'PHP not in dictionary.'У іншому випадку буде повернуто об’єкт None (інтерактивний інтерпретатор нічого не виведе):
>>> languages_programmers.get('PHP')
>>>5.8. Ключі і значення словника
Щоб отримати всі ключі словника можна використати функцію keys().
|
Для наступних прикладів використаємо інший словник:
>>> light_signals = {'green': 'go', 'yellow': 'get ready', 'red': 'stop'}
>>> light_signals.keys()
dict_keys(['yellow', 'red', 'green'])
В Python 3 функція keys() повертає не список ключів, а dict_keys() - ітеративне представлення ключів.
|
Ітеративне представлення ключів зручно для великих словників, окільки не вимагає часу і пам’яті для створення і збереження списку з цими ключами. Але, найчастіше, нам потрібен саме список. Тому в Python 3 треба викликати функцію list(), щоб перетворити dict_keys у список.
Отримання усіх ключів словника у вигляді списку з використанням функції list():
>>> list(light_signals.keys())
['yellow', 'red', 'green']
В Python 3 функція list() використовується для перетворення результатів роботи функцій values() і items() у звичайні списки.
|
Щоб отримати всі значення словника, необхідно використовувати функцію values().
|
>>> list(light_signals.values())
['get ready', 'stop', 'go']
Щоб отримати усі пари «ключ: значення» зі словника, необхідно використати функцію items().
|
>>> list(light_signals.items())
[('yellow', 'get ready'), ('red', 'stop'), ('green', 'go')]Як видно із результату, кожна пара «ключ: значення» повернулася у вигляді кортежу.
5.9. Обробка відсутніх ключів словника: функція setdefault()
Спроба отримати доступ до елемента словника за допомогою неіснуючого ключа викликає помилку.
Функція setdefault() створює елемент словника з ключем, якщо заданий ключ у словнику відсутній.
|
periodic_table = {'Hydrogen': 1, 'Helium': 2} (1)
print(periodic_table) (2)
carbon = periodic_table.setdefault('Ferrum', 26) (3)
print(periodic_table) (4)
print(carbon) (5)-
Визначання словника.
-
Виведення значення ключів і їх значень на екран.
-
Використання функції
setdefault(): якщо ключа ще немає в словнику (ключ'Ferrum'у словнику відсутній), у словник буде доданий даний ключ з новим значенням26. -
Виведення результату додавання пари «ключ: значення».
-
Виведення значення
26, що було додано у словник за ключем'Ferrum'.
У результаті виведення буде таким:
{'Hydrogen': 1, 'Helium': 2}
{'Hydrogen': 1, 'Helium': 2, 'Ferrum': 26}
26Якщо ми намагаємося присвоїти інше значення за замовчуванням вже існуючому ключу
periodic_table = {'Hydrogen': 1, 'Helium': 2}
helium = periodic_table.setdefault('Helium', 101)
print(periodic_table)
print(helium)буде повернуто оригінальне значення і у словнику зміни не відбудуться:
{'Hydrogen': 1, 'Helium': 2}
25.10. Множини
Множина схожа на словник, у якого відсутні значення, тобто має тільки ключі.
Щоб створити множину, слід використовувати функцію set() або розмістити у фігурних дужках одне або кілька значень, розділених комами.
|
Для прикладу:
>>> empty_set = set()
>>> empty_set
set()
>>> numbers = {0, 1, 4, 5, 7, 9}
>>> numbers
{0, 1, 4, 5, 7, 9}Ви можете створити множину за допомогою функції set() зі списку, рядка, кортежу або словника, втративши всі значення, що повторюються. Для прикладу, поглянемо на рядок, який містить більш ніж одне входження деяких букв:
>>> set('office')
{'e', 'c', 'o', 'f', 'i'}
Множина містить тільки одне входження літери f, незважаючи на те, що у слові office є два входження цієї літери.
|
Для перевірки приналежності множині використовується операція in:
>>> numbers = {0, 1, 4, 5, 7, 9}
>>> 5 in numbers
True
>>> 30 in numbers
FalseМножини Python підтримують класичні операції теорії множин, такі як об’єднання (|), перетин (&), різницю (-) і виключаюче АБО (ˆ).
Виконаємо деякі операції над множинами і зробимо пояснення:
>>> x = {0, 1, 4, 5, 7, 9} (1)
>>> y = {1, 2, 3, 6, 7, 8, 9} (2)
>>> x
{0, 1, 4, 5, 7, 9}
>>> y
{1, 2, 3, 6, 7, 8, 9}
>>> x.add(100) (3)
>>> x
{0, 1, 4, 5, 100, 7, 9}
>>> x.remove(100) (4)
>>> x
{0, 1, 4, 5, 7, 9}
>>> x | y (5)
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> x & y (6)
{1, 9, 7}
>>> x - y (7)
{0, 4, 5}
>>> y - x (8)
{8, 2, 3, 6}
>>> x ^ y (9)
{0, 2, 3, 4, 5, 6, 8}-
Створення множини
x = {0, 1, 4, 5, 7, 9}. -
Створення множини
y = {1, 2, 3, 6, 7, 8, 9}. -
Додавання до множини
xелемента100за допомогою функціїadd. -
Видалення із множини
xелемента100за допомогою функціїremove. -
Оператор
|об’єднує дві множини і повертає нову множину з унікальними значеннями. -
Оператор
&повертає нову множину із значеннями, які повторюються в обох множинах. -
Оператор
-повертає множину із елементами, які є унікальними лише для першої множиниx. -
Оператор
-повертає множину із елементами, які є унікальними лише для другої множиниy. -
Оператор
ˆповертає множину елементів обох множинxіyбез спільних елементів.
5.11. Складені структури даних
Різні типи даних (булеві значення, числа і рядки, списки, кортежі, множини і словники) можна об’єднувани у власні структури, більші і складніші. Для прикладу, візьмемо три різні списки:
>>> dairy_products = ['butter', 'cheese', 'yoghurt']
>>> vegetables = ['potatoes', 'broccoli', 'carrot', 'cucumber', 'onion']
>>> light_snacks = ['biscuits', 'chocolate', 'nuts']Ми можемо створити кортеж, який містить в якості елементів кожен з цих списків:
>>> tuple_of_lists = dairy_products, vegetables, light_snacks
>>> tuple_of_lists
(['butter', 'cheese', 'yoghurt'], ['potatoes', 'broccoli', 'carrot', 'cucumber', 'onion'], ['biscuits', 'chocolate', 'nuts'])Можемо також створити список, який містить три списки:
>>> list_of_lists = [dairy_products, vegetables, light_snacks]
>>> list_of_lists
[['butter', 'cheese', 'yoghurt'], ['potatoes', 'broccoli', 'carrot', 'cucumber', 'onion'], ['biscuits', 'chocolate', 'nuts']]Нарешті, створимо словник зі списків. У цьому прикладі використаємо назви групи продуктів в якості ключів, а список самих продуктів - як значення:
>>> dict_of_lists = {'Dairy': dairy_products, 'Vegetables': vegetables, 'Snacks': light_snacks}
>>> dict_of_lists
{'Snacks': ['biscuits', 'chocolate', 'nuts'], 'Vegetables': ['potatoes', 'broccoli', 'carrot', 'cucumber', 'onion'], 'Dairy': ['butter', 'cheese', 'yoghurt']}| Ключі словника повинні бути незмінними, тому список, словник чи множина не можуть бути ключем для іншого словника. Але кортеж може бути ключем. |
Наприклад, ви можете створити словник понять різних видів спорту, у якому ключами виступають кортежі:
>>> sports_equipment = {
... ('1500 metres', 'high jump', 'shot put'): 'Athletics',
... ('goalkeeper', 'foul', 'corner'): 'Football',
... ('handlebars', 'wheels', 'bicycle pump'): 'Cycling'
... }
>>> sports_equipment
{('1500 metres', 'high jump', 'shot put'): 'Athletics', ('handlebars', 'wheels', 'bicycle pump'): 'Cycling', ('goalkeeper', 'foul', 'corner'): 'Football'}5.12. Завдання
5.12.1. Контрольні запитання
-
Як виглядає код для порожнього словника?
-
Як виглядає елемент словника з ключем
keyі значенням81? -
Опишіть основні відмінності між словником і списком.
-
У змінній
resultзберігається словник. Яка різниця між такими виразами:'battery' in resulti'battery' in result.keys()? -
У змінній
resultзберігається словник. Яка різниця між такими виразами:'battery' in resulti'battery' in result.values()? -
Що буде відображено на місці
...при спробі отримання доступу до елементів, використовуючи такий код:
>>> room = {'bookcase': 1, 'armchair': 3, 'table': 1, 'clock': True}
>>> room['armchair']
...
>>> room['mirror']
...
>>> room['clock']
...
>>> room['table']
...
>>> room.get('blinds', 'Blinds are missing.')
...5.12.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Використайте словник для збереження інформації про видатну особистість (вченого, письменника, винахідника тощо). Збережіть ім’я, прізвище, століття, в якому народилась ця людина, і одне з досягнень. Словник повинен містити ключі з такими іменами, як
first_name,last_name,centuryіprogress. Виведіть кожен фрагмент інформації, що зберігається у словнику. -
Створіть словник для зберігання цифр. Візьміть п’ять імен (назви цифр) і використайте їх як ключі словника. Для кожного ключа надайте значення відповідної цифри. Виведіть по черзі назву цифри і її значення для усіх елементів словника.
-
У французько-англійському словнику
f2eмістяться такі слова:blanc / white,rose / pink,violet / purpleіargent / silver. Опишіть цей словник. Створіть і виведіть на екран множину французьких слів з ключів словника. -
Створіть множину із списку:
['boat', 'bus', 'plane', 'train']. -
Створіть множину із кортежу:
('cyclist', 'driver', 'pedestrian'). -
Створіть множину із словника:
{'breakfast': 'coffee', 'lunch': 'milk', 'dinner': 'tea'}.
5.12.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Словники
Pythonможуть використовуватися для моделювання «справжнього» словника (назвемо його глосарієм). Оберіть кілька термінів з програмування (або із іншої області), які ви знаєте на цей момент. Використайте ці слова як ключі глосарію, а їх визначення - як значення. Виведіть кожне слово і його визначення у спеціально відформатованому вигляді. Наприклад, ви можете вивести слово, потім двокрапка і визначення; або ж слово в одному рядку, а його визначення - з відступом в наступному рядку. Використовуйте символ нового рядка (\n) для вставки порожніх рядків між парами «слово: визначення» і символ табуляції для встановлення відступів (\t) у вихідних даних. -
Cтворіть словник з трьома річками і регіонами, територією яких вони протікають. Одна з можливих пар «ключ: значення» -
'Amazon': 'South America'. Додайте ще дві пари «річка: регіон» у словник. Виведіть повідомлення із назвами річки і регіону - наприклад,«The Amazon runs through South America.»для усіх елементів словника, враховуючи те, що у повідомлення у відповідні місця підставляються назви річок і територій. -
Створіть словник з чотирма назвами мов програмування (ключі) та іменами розробників цих мов (значення). Виведіть по черзі для усіх елементів словника повідомлення типу
My favorite programming language is Python. It was created by Guido van Rossum.. Видаліть, на ваш вибір, одну пару «мова: розробник» із словника. Виведіть словник на екран. -
Створіть англо-німецький словник, який називається
e2g, і виведіть його на екран. Слова для словника:stork / storch,hawk / falke,woodpecker / spechtіowl / eule. Виведіть німецький варіант словаowl. Додайте у словник, на ваш вибір, ще два слова та їхній переклад. Виведіть окремо: словник; ключі і значення словника у вигляді списків. -
Створіть кілька словників, імена яких - це клички домашніх тварин. У кожному словнику збережіть інформацію про вид домашнього улюбленця та ім’я власника. Збережіть словники в списку з ім’ям
pets. Виведіть кілька повідомлень типуAlex is the owner of a pet - a dog.. -
Виведіть представлення букви, яку вводить користувач, у символах азбуки Морзе . Фрагмент словника має такий вигляд:
morse = {'A': '.-', 'B': '-...', 'C': '-.-.', 'D': '-..', 'E': '.', 'F': '..-.', ...}. Передбачте у програмі обробку малих і великих букв. -
Створіть багаторівневий словник
subjectsнавчальних предметів. Використайте наступні рядки для ключів верхнього рівня:'science','humanities'і'public'. Зробіть так, щоб ключ'science'був ім’ям іншого словника, який має ключі'physics','computer science'і'biology'. Зробіть так, щоб ключ'physics'посилався на список рядків зі значеннями'nuclear physics','optics'і'thermodynamics'. Решта ключів повинні посилатися на порожні словники. Виведіть на екран ключіsubjects['science']і значенняsubjects['science']['physics']. -
Створіть словник з ім’ям
cities. Використайте назви трьох міст в якості ключів словника. Створіть словник з інформацією про кожне місто: включіть в нього країну, в якій розташоване місто, приблизну чисельність населення і один цікавий факт про місто. Ключі словника кожного міста повинні називатисяcountry,populationіfact. Виведіть назву кожного міста і всю збережену інформацію про нього. -
Із словника
teamsнеобхідно вивести на екран статистику кількох команд Національної баскетбольної асоціаціїNBA. Створіть словникteams, дотримуючись наступних правил. Назви команд - це ключі словника. Значення у словнику - це список, на зразок: [Всього ігор, Перемог, Нічиїх, Поразок, Всього очок]. Значення списку - це цілі числа, які обираються довільно. При виведенні даних, прослідкуйте, щоб формат виведення був таким:NEW YORK KNICKS 22 7 6 9 45. Інформація про кожну команду має міститися в окремому рядку. Зверніть увагу на те, що дані у словнику є невпорядкованими. -
Ви створюєте пригодницьку гру і використовуєте для зберігання предметів гравця словник, у якому ключі - це назви предметів, значення - кількість одиниць кожної із речей. Наприклад, словник може виглядати так:
things = {'key': 3, 'mace': 1, 'gold coin': 24, 'lantern': 1, 'stone': 10}. Виведіть повідомлення про усі речі гравця у такому вигляді:
Equipment:
3 key
1 mace
24 stone
1 lantern
10 gold coin
Total number of things: 396. Структури коду
Програма - це всього лише серія інструкцій. Виходячи з того, як оцінюються вирази, програма може вирішити пропустити інструкції, повторити їх або вибрати одну з декількох для запуску. Тобто, у програмі часто доводиться перевіряти умови і приймати рішення в залежності від цих умов.
Розгляньте блок-схему прийняття рішень, яка визначає порядок дій, які повинні виконуватися в залежності від того, чи йде дощ:
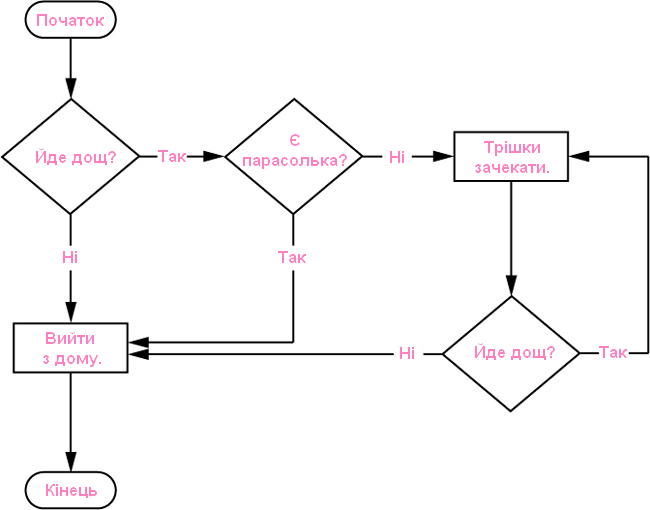
| На блок-схемах, зазвичай, показують декілька можливих маршрутів від початку і до кінця перебігу якогось процесу або явища, ходу розв’язування задачі тощо. |
Блок-схеми використовують і для побудови структури коду комп’ютерної програми. Блоки умов, в яких відбувається розгалуження програми, позначаються на блок-схемах ромбами, блоки з діями - прямокутниками. Кінцевий і початковий блоки програми представляються округленими прямокутниками.
6.1. Створення і перевірка умов
Для створення і перевірки умов використовують булеві значення, оператори порівнювання і булеві оператори.
6.1.1. Булеві значення
В той час, як цілі, дійсні і рядкові типи даних можуть мати необмежену кількість значень, булевий (логічний) тип даних може прйимати лише два значення: True (істина) і False (хибність).
| Булевий тип даних отримав свою назву на честь англійського математика, засновника математичної логіки Джорджа Буля. |
>>> one = True
>>> one
True
>>> two = false
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'false' is not defined
>>> two = False
>>> two
False
При використанні у коді Python, булеві значення True і False записуються без лапок і їх назви починаються з великих літер T і F, тоді як інша частина слова пишеться маленькими буквами.
|
6.1.2. Оператори порівнювання
Оператори порівнювання порівнюють два значення між собою і повертають результат у вигляді булевого значення: істину або хибність.
| Оператор | Назва |
|---|---|
|
Дорівнює |
|
Не дорівнює |
|
Менше ніж |
|
Більше ніж |
|
Менше або дорівнює |
|
Більше або дорівнює |
Для демонстрації роботи операторів порівнювання, використаємо наступний приклад, у якому присвоємо змінній a цілочисельне значення 10:
>>> a = 10
>>> a == 5
False
>>> a == 10
True
>>> 4 < a
True
>>> a > 12
False
>>> 'breeze' == 'breeze'
True
>>> 'breeze' == 'Breeze'
False
>>> 'fine' != 'rain'
True
>>> 16 == 16.0
True
>>> 16 == '16'
False
>>> 45 >= 11
True
Будьте уважними, для перевірки на рівність використовуються два знакм «дорівнює» (==); пам’ятайте, що один знак «дорівнює» (=) застосовується для присвоювання змінній значення.
|
6.1.3. Булеві оператори
Якщо вам потрібно виконати кілька порівнянь одночасно, використовуйте булеві (логічні) оператори and, or і not, щоб визначити підсумковий результат. Булеві оператори мають більш низький пріоритет, ніж фрагменти коду, які вони порівнюють. Це означає, що спочатку вираховується результат фрагментів, а потім вони порівнюються.
Булеві оператори and і or завжди працюють з двома булевими значеннями (або виразами), тому їх називають бінарними.
|
Для представлення усім можливих результатів роботи булевих операторів and і or використовують таблиці істинності.
| Вираз | Результат |
|---|---|
|
|
|
|
|
|
|
|
| Вираз | Результат |
|---|---|
|
|
|
|
|
|
|
|
Булевий оператор not змінює булеве значення на протилежне.
Булевий оператори not завжди діє на одне булеве значення (або вираз), тому його називають унарним.
|
| Вираз | Результат |
|---|---|
|
|
|
|
Щоб побачити як працюють булеві оператори and, or і not, виконайте в інтерпретаторі наступні приклади:
>>> True and True
True
>>> True and False
False
>>> True or False
True
>>> not True
False
>>> not False
True
Таблиці істинності Python представлені у Додаток C: Таблиці істинності.
|
6.1.4. Поєднання булевих значень, операторів порівнювання, булевих операторів
Виконайте в інтерпретаторі Python наступні приклади:
>>> (7 < 10) and (6 < 9)
True
>>> (3 < 5) and (16 < 8)
False
>>> (3 == 6) or (32 == 32)
True
>>> 2 + 2 == 4 and not 2 + 2 == 5 and 2 * 2 == 2 + 2
TrueСпочатку обчислюється лівий вираз, а потім - правий. Коли обидва результати стають відомими, обчислюється кінцевий результат всього виразу загалом, який буде у вигляді єдиного булевого значення.
Як і для математичних операторів, для булевих операторів визначений порядок їхнього виконання. Після того, як будуть виконані всі математичні оператори і оператори порівнювання, першими виконуються оператори not, потім - оператори and і тільки після цього - оператори or.
6.2. Вказівка розгалуження
До цього моменту, в багатьох випадках для ознайомлення з типами даних використовувався інтерактивний інтерпетатор. У наступних прикладах увага буде приділятися структурі коду Python. Тому приклади коду необхідно записувати в окремих файлах, створених у вибраному середовищі програмування.
|
Будь-який булевий вираз може розглядатися як умова, обчислення якої завжди дає булеве значення True (істина) або False (хибність). В залежності, яке значення отримує умова, програма може виконувати або пропускати фрагменти коду - блоки коду, тобто має місце розгалуження.
| Ознакою блоку коду є збільшення відступу від лівого краю. Блоки можуть містити інші блоки. Ознакою кінця блоку слугує зменшення відступу до нуля або до величини відступу зовнішнього блоку. |
Для більшого розуміння про відступи і блоки коду, розглянемо наступну програму (створіть новий файл у вибраному вами середовищі програмування і збережіть файл з певним ім’ям):
name = 'Mary'
password = 'hurricane'
if name == 'Mary':
....print('Hello, Mary.') (1)
....if password == 'swordfish':
........print('Access granted.') (2)
....else:
........print('Wrong password.') (3)
else:
....print('User not registered.') (4)| Відступи явно позначені крапками для наочності. В реальних умовах відступи створюють за допомогою клавіші Пропуск. |
-
Перший блок коду: починається рядком
print('Hello, Mary.)і містить усі наступні рядки коду до другого оператораelse(не включаючи його). -
Другий блок коду: знаходиться у першому блоці коду, містить лише один рядок коду
print('Access granted.')і відноситься до другого оператораif. -
Третій блок коду: складається тільки із одного рядка
print('Wrong password.')і відноситься до першого оператораelse. -
Четвертий блок коду: складається із єдиного рядка
print('User not registered.')і відноситься до другого оператораelse.
6.2.1. Що істина, а що хибність?
Як визначається істина або хибність, якщо елемент в умові, який ми перевіряємо, не є булевим? Наприклад, до False (хибність) прирівнюються наступні значення:
-
булева змінна
False -
значення
None -
ціле число
0 -
число з рухомою крапкою
0.0 -
порожній рядок
'' -
порожній список
[] -
порожній кортеж
() -
порожній словник
{} -
порожня множина
set()
Всі інші значення прирівнюються до True (істина).
6.2.2. Команда if
Завдяки команді if перевіряється поточний стан програми та вибираються подальші дії в залежності від результатів перевірки. Синтаксис команди if такий:
if умова: блок коду
| Така форма розгалуження у програмуванні називається неповною. |
Якщо результат обчислення умови є істинним (True), блок коду виконується. Коли ж результат обчислення умови є хибним (False), то блок коду не буде виконуватися.
Звичайною мовою роботу команди if можна описати таким чином: «Якщо умова істинна, то виконати даний блок коду».
В Python інструкція if включає такі елементи:
-
ключове слово
if -
умова (вираз, обчислення якого дає одне з двох значень:
TrueабоFalse) -
двокрапка
-
блок коду з відступом, який починається в наступному рядку
Припустимо, у нас є код, що перевіряє співпадіння з певним ім’ям, наприклад, з ім’ям Mary:
if name == 'Mary':
print('Hello, Mary.')Якщо вважати, що змінній name попередньо було присвоєне значення Mary, то після виконання цього фрагмента коду, отримаємо на екрані повідомлення:
print('Hello, Mary.')У протилежному випадку, якщо змінна name матиме інше значення, блок коду команди if, що складається з однієї інструкції print('Hello, Mary.'), не буде виконаний і жодного повідомлення на екрані не з’явиться.
Блок-схема для даного фрагмента коду буде такою:
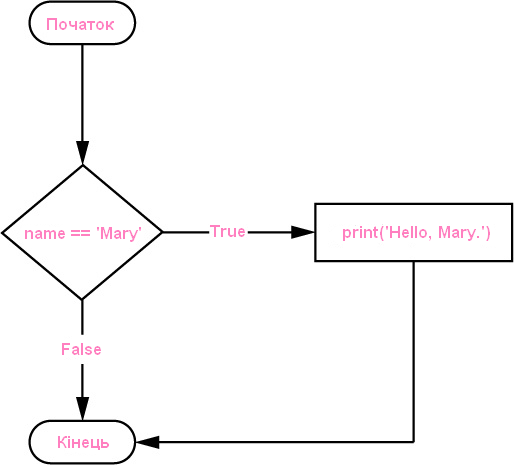
6.2.3. Команда else
За блоком коду команди if може слідувати необов’язкова команда else вже із власним блоком коду, який виконується лише в тому випадку, якщо умова if є хибною. Синтаксис цієї конструкції такий:
if умова: блок коду, коли умова істинна else: блок коду, коли умова хибна
| Така форма розгалуження у програмуванні називається повною. |
Звичайною мовою конструкція if/else може бути прочитана так: «Якщо умова істинна, то виконати даний блок коду. В протилежному випадку виконати наступний блок коду».
В Python команда else не має умови і завжди складається з таких елементів:
-
ключове слово
else -
двокрапка
-
блок коду з відступом, що починається на наступному рядку
Повертаючись до прикладу з ім’ям Mary, розглянемо код, що містить інструкцію else, яка виводить інше повідомлення, якщо змінній name було попередньо надано значення не Mary, а, наприклад, Jack:
if name == 'Mary':
print('Hello, Mary.')
else:
print('Hello, stranger.')Результатом виконання у даному випадку буде повідомлення із блоку коду команди else, що складається з однієї інструкції print('Hello, stranger.'):
Hello, stranger.Блок-схема для цього випадку:
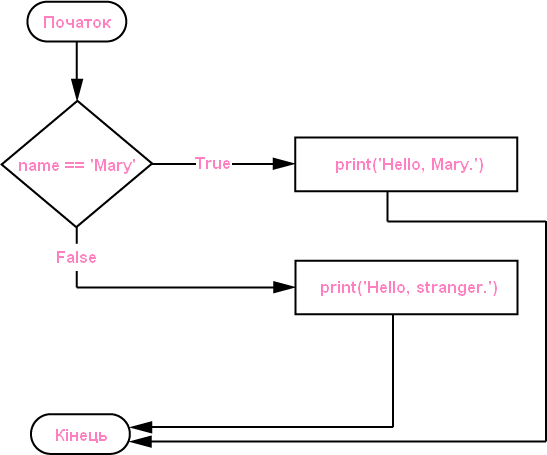
6.2.4. Команда elif
Для перевірки більше однієї умови використовують команду elif (скорочення від else if). Записується ця команда тільки після інструкцій if або після іншої команди elif. Дана команда дозволяє вказувати додаткові умови для перевірки. Синтаксис використання інструкції elif такий:
if умова1: блок коду, коли умова1 істинна elif умова2: блок коду, коли умова2 істинна elif умова3: блок коду, коли умова3 істинна ...
В Python команда elif завжди складається з таких елементів:
-
ключове слово
elif -
умова (вираз, обчислення якого дає одне з двох значень:
TrueабоFalse) -
двокрапка
-
блок коду з відступом, що починається на наступному рядку
У випадку ланцюжка команд elif, як тільки з’ясовується, що одна з умов істинна, всі інші блоки elif автоматично пропускаються. Тобто, буде виконаний або тільки один блок коду, або жоден з них.
|
6.2.5. Конструкція if/elif/else
В разі потреби услід за останньою інcтрукцією elif можна помістити команду else. В цьому випадку гарантується, що буде виконаний хоча б один (і тільки один) блок коду:
if умова1: блок коду, коли умова1 істинна elif умова2: блок коду, коли умова2 істинна elif умова3: блок коду, коли умова3 істинна else: блок коду, коли усі умови хибні
Якщо умови у всіх інcтрукціях if і elif будуть хибними, то виконається блок коду інструкції else.
|
Звичайною мовою конструкція if/elif/else може бути прочитана так: «Якщо перша умова істинна, то виконати даний блок коду. Якщо друга умова істинна, виконати даний блок коду. В протилежному випадку виконати даний блок коду».
Використаємо інcтрукції if, elif і else у нашому прикладі з перевіркою імені:
if name == 'Alice':
print('Hi, Alice.')
elif age < 12:
print('You are not Alice, kiddo.')
else:
print('You are neither Alice nor a little kid.')Якщо вхідні дані вважати такими: name = 'Alex', age = 36, то результатом виконання буде повідомлення:
You are neither Alice nor a little kid.Блок-схема для даного прикладу:
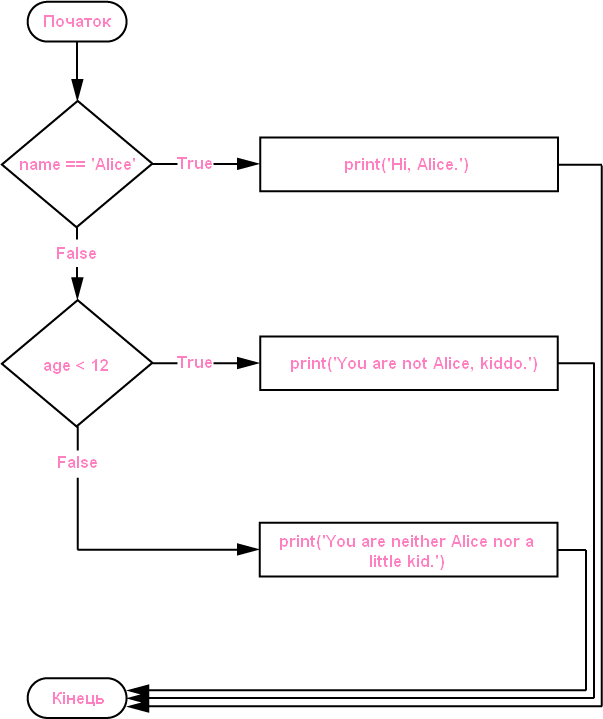
Перевірку умов можна вкладати одна в одну, відокремлюючи відступами, як показано на прикладі:
furry = True
small = True
if furry:
if small:
print("It's a cat.")
else:
print("It's a bear!")
else:
if small:
print("It's a lizard!")
else:
print("It's a human. Or a hairless bear.")Результатом виконання цього фрагмента програми буде повідомлення:
It's a cat.6.2.6. Конструкція match/case
У коді Python іноді необхідно перевіряти не лише значення, але й тип даних. Це призводить до того, що виникає велика кількість гілок if/elif/else.
Щоб уникнути подібних ускладнень, у Python з’явився інструмент pattern matching (зіставлення шаблонів) під назвою match/case.
Конструкцію match/case було додано у версії Python 3.10.
|
На відміну від традиційного ланцюжка if/elif/else, який може стати громіздким зі складними умовами, конструкція match/case більш лаконічно і читабельніше реалізовує багатоваріантну перевірку умов і є не лише засобом для порівняння якоїсь змінної зі значеннями.
match/case дозволяє зіставити значення виразу з низкою шаблонів і виконати відповідний блок коду для відповідного шаблону.
Синтаксис використання match/case такий:
match expression:
case pattern1:
# код для pattern1
case pattern2:
# код для pattern2
case _:
# типовий код за умови жодного збігу
Розглянемо складові конструкції match/case:
-
expression- значення (вираз), яке перевіряється; -
case pattern- шаблон (pattern), який порівнюється зі значенням (виразом); -
_- використовується як універсальний шаблон, що відповідає будь-якому значенню (виразу).
Наприклад, для коду
command = "start"
match command:
case "start":
print("Starting...")
case "stop":
print("Stopping...")
case "pause":
print("Pausing...")
case _:
print("Unknown command")результатом буде:
Starting...В одному шаблоні можна поєднати кілька виразів за допомогою оператора | (або):
day = "Sunday"
match day:
case "Monday" | "Tuesday" | "Wednesday" | "Thursday" | "Friday":
print("Weekday")
case "Saturday" | "Sunday":
print("Weekend")
case _:
print("There is no such day")У цьому разі зіставлення відбуватиметься з будь-яким значенням, представленим у відповідному шаблоні:
Weekend
Оператор or (або) в Python використовується для перевірки істинності виразів. Оператор | (або) не є стандартним оператором для порівнянь чи логічних операцій, а використовується у контексті шаблонів як оператор для комбінування кількох можливих значень або шаблонів одночасно в конструкції match/case.
|
Для більшого контролю процесу зіставлення, після слова case можна записати додаткову перевірку в межах відповідного шаблону. Наприклад:
number = 43
match number:
case n if n < 0:
print("loss")
case n if n > 0:
print("win")
case _:
print("equally")Результат виконання коду:
winНапишемо функцію, яка буде повертати типи даних значень, переданих у функцію, використовуючи конструкцію match/case:
def describe_value(value):
match value:
case bool(): (1)
return f"This is a boolean: {value}."
case int(): (2)
return f"This is an integer: {value}."
case str():
return f"This is a string: {value}."
case list():
return f"This is a list: {value}."
case _:
return f"Unknown type: {value}."
print(describe_value("Hello"))
print(describe_value(43))
print(describe_value(True))
print(describe_value(["Python", 3]))
print(describe_value(None))| 1 | Перевіряємо, чи значення є булевим. |
| 2 | Булеві значення не потраплять сюди, оскільки вони перевіряються раніше. |
Результати викликів функції describe_value() для різних значень:
This is a string: Hello.
This is an integer: 43.
This is a boolean: True.
This is a list: ['Python', 3].
Unknown type: None.За допомогою match/case можна зіставляти окремі елементи структури даних або навіть загалом структуру даних. Наприклад, при зіставлення списку з шаблоном
data = [1, 2]
match data:
case []:
print(f"Empty list: {data}")
case [x]:
print(f"List with one element: {x}")
case [x, y]:
print(f"List with two elements: {x}, {y}")
case [x, *rest]:
print(f"First element: {x}, the rest: {rest}")
case _:
print(f"This is not a list: {data}")можна звертатися до окремих елементів списку:
List with two elements: 1, 2Аналогічно match/case можна використовувати зі словниками
point = {"x": 3, "y": 5}
match point:
case {"x": x, "y": y}:
print(f"Coordinates: x={x}, y={y}")
case {"x": x}:
print(f"Coordinate x: {x}")
case _:
print("Unknown format")перевіряючи певні ключі та значення:
Coordinates: x=3, y=5Однією з особливостей match/case є можливість порівнювати з екземплярами класів. Наприклад:
class Point: (1)
def __init__(self, x, y):
self.x = x
self.y = y
p = Point(1, 3) (2)
match p:
case Point(x=1, y=y): (3)
print(f"Point in coordinates x=1, y={y}")
case Point(x=x, y=0): (4)
print(f"Point in coordinates x={x}, y=0")
case _: (5)
print("Unknown point")Результат виконання коду:
Point on the axis x=1, y=3Давайте детальніше розглянемо поведінку match/case у наведеному прикладі.
| 1 | Опис класу Point. |
| 2 | Створення екземпляру p класу Point. |
| 3 | З результату в консолі бачимо, що саме цей шаблон спрацював завдяки тому, що переданий у шаблон об’єкт p є екземпляром класу Point і його атрибут x дорівнює 1. При цьому атрибут y може мати будь-яке значення, яке й буде призначене змінній y. |
| 4 | Ця гілка спрацює тоді, коли значення атрибута y обов’язково дорівнюватиме 0, а значення x буде будь-яким, але не дорівнюватиме 1, наприклад для p = Point(4, 0). |
| 5 | Ця гілка спрацює тоді, коли одночасно значення атрибута x не дорівнюватиме 1, а значення y не дорівнюватиме 0, наприклад для p = Point(2, 5). |
У кінцевому підсумку механізм match/case є гнучким інструментом для перевірки типів та умов, особливо коли потрібно виконати кілька перевірок для різних типів даних або складних структур.
6.3. Вказівка повторення
Перевірки за допомогою if, elif і else виконуються послідовно. Іноді потрібно виконати якісь операції більше ніж один раз. Для цього потрібен цикл .
6.3.1. Команда while
Одним із варіантів циклу у Python є while. Синтаксис використання циклу while такий:
while умова: блок коду, коли умова істинна
В Python команда while завжди складається з таких елементів:
-
ключове слово
while -
умова (вираз, обчислення якого дає одне з двох значень:
TrueабоFalse) -
двокрапка
-
блок коду з відступом, що починається на наступному рядку
Команда while має схожу структуру з командою if, але веде себе по іншому.
По досягненні кінця блоку коду команди if, керування виконанням програми передається наступній команді, а при досягненні кінця блоку коду команди while, керування передається на початок циклу для перевірки умови. Якщо умова істинна - програма продовжує виконувати той самий блок коду, інакше - відбувається вихід з циклу і виконується блок коду, що міститься після конструкції циклу.
У циклі while умова завжди перевіряється на початку кожної ітерації - кожен раз, коли виконується цикл. Ітерація - один крок виконання циклу.
|
Спробуйте запустити наступний приклад коду:
count = 1
while count <= 5:
print(count)
count += 1Це простий цикл виводить на екран значення від 1 до 5:
1
2
3
4
5Як працює цикл while у цьому прикладі?
-
Спочатку ми присвоюємо значення
1зміннійcount. -
Цикл
whileпорівнює значення змінноїcount(зараз воно дорівнює1) з числом5і продовжує роботу, якщо значенняcountменше або дорівнює5(умова циклу є істинною) або у протилежному випадку цикл завершується (умова циклу є хибною). -
Всередині циклу (ця частина називається тілом циклу) виводиться значення змінної
count. -
Потім збільшується значення змінної
countна1за допомогою виразуcount += 1. -
Pythonповертається до початку циклу і знову порівнює значення змінноїcountз числом5. -
Значення змінної
countтепер дорівнює2, тому тіло циклуwhileвиконується знову і зміннаcountзбільшується до3. -
Виконання продовжується до тих пір, поки значення змінної
countне буде збільшено з5до6в тілі циклу. -
Під час чергового повернення на початок циклу перевірка
count <= 5поверне значенняFalseі циклwhileзакінчується. -
Pythonперейде до виконання наступних рядків коду.
Блок-схема використання циклу while у даному прикладі така (вважати, що перед виконанням циклу було виконано присвоєння count = 1):
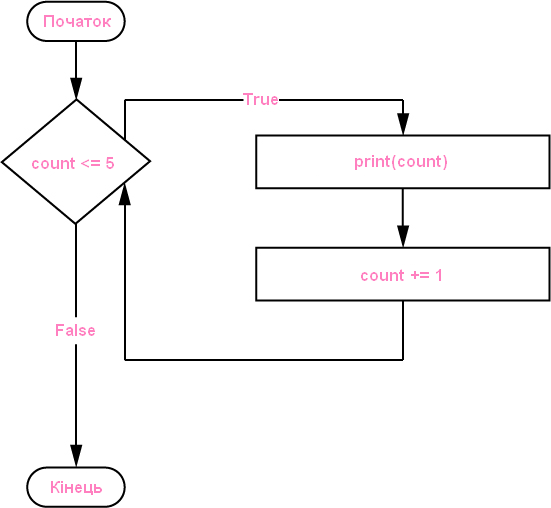
6.3.2. Переривання циклу, break
Якщо необхідно, щоб цикл виконувався до тих пір, поки щось не станеться, але точно невідомо, коли ця подія трапиться, можна скористатися нескінченним циклом, що містить оператор break. Якщо програма у процесі виконання досягає команди break, то виконання циклу відразу припиняється.
Розглянемо програму, у якій користувачем вводиться рядок з клавітури за допомогою функції input(), а потім цей рядок виводиться на екран із представленням першої літери у верхньому регістрі. Цикл переривається, коли буде введено рядок, що містить тільки букву q.
Введіть наступний код у середовищі програмування, збережіть файл з певним ім’ям і виконайте:
stuff = ''
while True:
print("String to capitalize [type q to quit]: ")
stuff = input()
if stuff == "q":
break
print(stuff.capitalize())
print('Thank you!')
Рядок while True: створює нескінченний цикл - умова такого циклу завжди істинна (True). Програма завжди буде виконувати команди циклу і вийде з нього тільки у тому випадку, якщо виконається інструкція break. Нескінченний цикл, вийти з якого неможливо, - розповсюджена помилка.
|
Результат виконання і блок-схема, для випадку використання команди break, будуть такими:
String to capitalize [type q to quit]:
test
Test
String to capitalize [type q to quit]:
hey, it works!
Hey, it works!
String to capitalize [type q to quit]:
q
Thank you!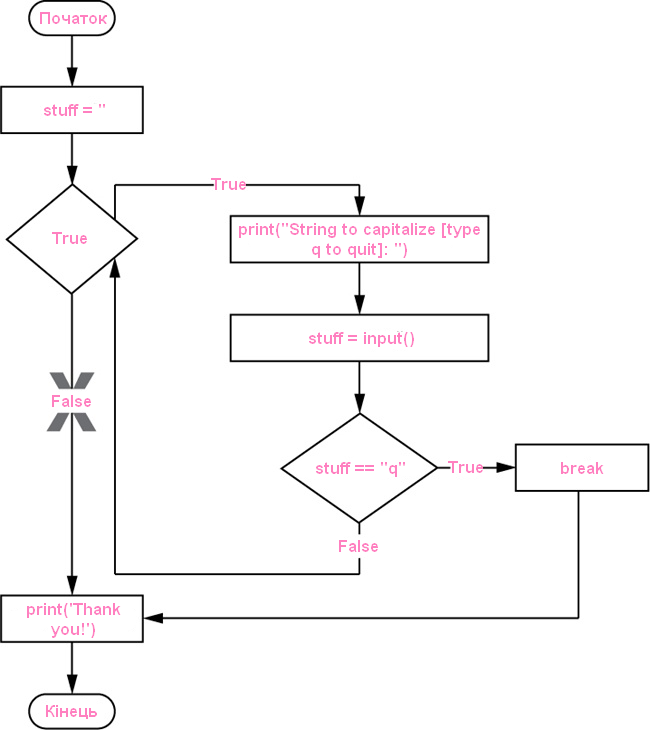
| Перекреслений шлях виконання програми на блок-схемі логічно ніколи не може бути реалізований, оскільки умова циклу завжди істинна. |
6.3.3. Нескінченний цикл і вихід з нього
Щоб перевірити на практиці, як працює нескінченний цикл, запишіть і збережіть у файлі з певним ім’ям код, поданий нижче:
| Якщо ваша програма потрапила в нескінченний цикл, натисніть сполучення клавіш Ctrl+C, в результаті чого програма припинить своє виконання. |
while True:
print('Hello, world!')Дана програма в процесі виконання без зупинки буде повторювати виведення повідомлення Hello, world!, оскільки умова циклу while завжди істинна (True).
Щоб попередити зациклювання програми, проаналізуйте, як обробляється значення, що повинно привести до виходу з циклу. Перевірте, щоб виконання хоча б однієї частини програми могло б привести до того, щоб умова циклу стала дорівнювати False або була б виконана команда break. Наприклад, якщо у коді:
count = 1
while count <= 5:
print(count)
count += 1пропустити рядок count += 1
count = 1
while count <= 5:
print(count)то цикл стане нескінченним:
1
1
1
...6.3.4. Продовження циклу, continue
Іноді потрібно не переривати весь цикл, а лише пропустити, по певній причині, одну ітерацію. Для цих речей використовується оператор continue.
Коли програма у процесі виконання досягає інструкції continue, відразу ж керування програмою передається на початок циклу, де умова перевіряється знову (це ж саме відбувається і при звичайному досягненні програмою кінця циклу).
Напишемо і збережемо у файлі з певною назвою програму, яка запитує ім’я і пароль для входу:
name = ''
while True:
print('Who are you?')
name = input()
if name != 'Joe':
continue
print('Hello, Joe. What is the password? (It is a fish.)')
password = input()
if password == 'swordfish':
break
print('Access granted.')Якщо користувач вводить будь-яке ім’я, окрім Joe, інструкція continue вказує програмі перейти на початок циклу. Після повторної перевірки умови програма завжди входить в тіло циклу, оскільки умова завжди істинна (True).
У випадку проходження існтрукції if, запитується пароль і, якщо користувач, вводить пароль swordfish, то виконується інcтрукція break, програма перериває цикл і виводить на екран повідомлення Access granted.. В протилежному випадку управління виконанням програми передається в кінець циклу while і відразу повертається на його початок.
Результи виконання програми для різних значень, що вводив користувач, і відповідна блок-схема:
Who are you?
Alice
Who are you?
Jack
Who are you?
Joe
Hello, Joe. What is the password? (It is a fish.)
shark
Who are you?
Joe
Hello, Joe. What is the password? (It is a fish.)
swordfish
Access granted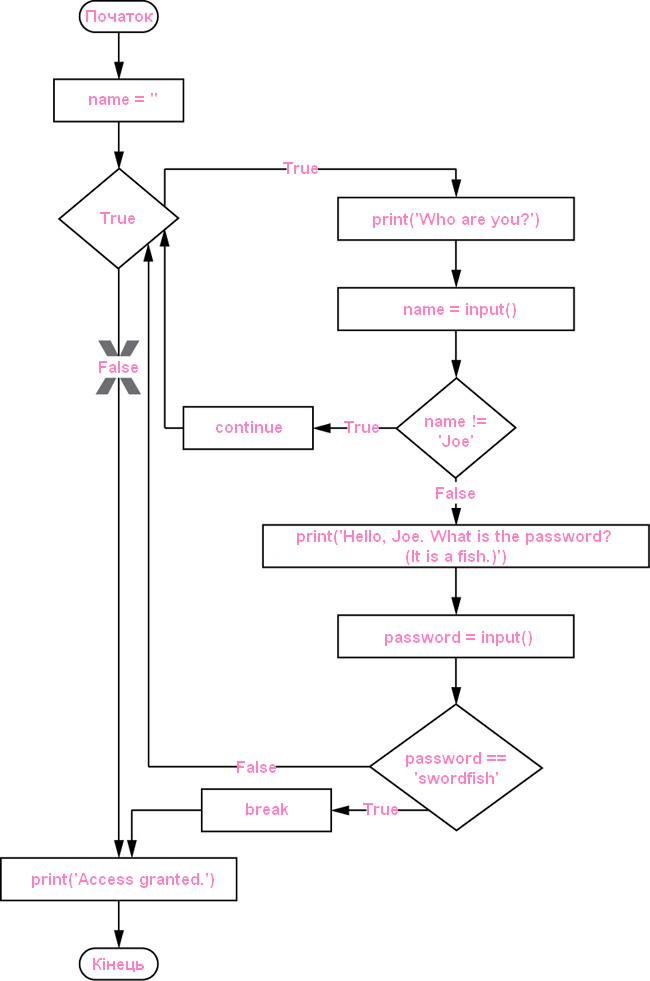
Програма не запитає пароль до тих пір, поки користувач не підтвердить, що його ім’я Joe. Якщо буде введено неправильний пароль, програма знову запитає про ім’я, а після введення правильного пароля програма завершить своє виконання.
6.3.5. Цикл for
Цикл while продовжує виконуватися доти, доки умова залишається істинною. Якщо необхідно виконати блок коду лише визначену (відому) кількість разів, то використовують цикл for і функцію range(). Синтаксис використання цього циклу і цієї функції записується так:
for змінна in range(): блок коду
В Python команда for завжди складається з таких елементів:
-
ключове слово
for -
ім’я змінної
-
ключове слово
in -
виклик функції
range(), в яку можна передати до трьох цілих чисел, розділених комами -
двокрапка
-
блок коду з відступом, що починається на наступному рядку
Щоб перевірити на практиці, як працює цикл for, створіть нову програму у файлі та збережіть з певним ім’ям:
print('My name is')
for i in range(5):
print('Anakin Skywalker (' + str(i) + ')')Блок коду циклу for виконується 5 разів. На першій ітерації (при першому виконанні) значення змінної i встановлюється рівним 0. Виклик функцій print() в тілі циклу виводить повідомлення Anakin Skywalker (0).
Коли цикл закінчує ітерацію, виконавши увесь блок коду, управління передається на початок циклу, де інструкція for збільшує значення змінної i на 1.
Саме тому, виклик функції range(5) забезпечує п’ятикратне виконання блоку коду циклу, встановлюючи для i послідовно значення 0, 1, 2, 3 і 4.
Ціле значення 5, вказане у дужках функції range() в цей ряд не входить.
|
Коли запустити дану програму, вона виведе п’ять рядків тексту, кожен з яких буде закінчуватись поточним значенням змінної i, після цього цикл закінчить свою роботу:
My name is
Anakin Skywalker (0)
Anakin Skywalker (1)
Anakin Skywalker (2)
Anakin Skywalker (3)
Anakin Skywalker (4)Блок-схема роботи даної програми така:
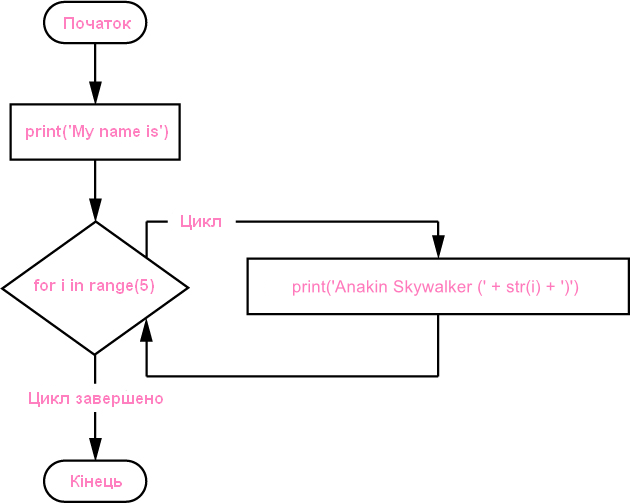
Команди break і continue використовуються у циклі for по аналогії, як і у випадку з циклом while.
|
Окрім того, все те, що робить цикл for, можна зробити і за допомогою циклу while. Перепишіть попередню програму, але вже з використанням циклу while і переконайтеся у таких самих результатах, як і у випадку використання циклу for:
print('My name is')
i = 0
while i < 5:
print('Anakin Skywalker (' + str(i) + ')')
i = i + 1 # i += 16.3.6. Функція range()
У функцію range() можна передавати аргументи - значення трьох цілих чисел, розділених комами.
Перше число визначає, з якого значення починає змінюватися змінна циклу for, друге число - значення, до якого може змінюватися змінна циклу for (число не входить у діапазон). Для прикладу, виконавши такий код:
for i in range(12, 16):
print(i)отримаємо результати:
12
13
14
15Також функцію range() можна викликати і з трьома аргументами. Перші два - визначають початок і кінець діапазону зміни значень змінної циклу for, а третій задає крок цієї зміни. Наприклад, виконавши такий код:
for i in range(1, 10, 2):
print(i)отримаємо результати:
1
3
5
7
9Функцію range() можна викликати також, задавши від’ємний крок. У такому випадку значення змінної циклу for буде змінюватися від більших значень до менших. Виконання циклу for з використанням виклику range(3, -4, -1):
for i in range(3, -4, -1):
print(i)дає такий результат:
3
2
1
0
-1
-2
-36.3.7. Цикл for і послідовності
Цикл for дозволяє проходити по різним структурам даних, які є послідовностями.
Використання циклу for для проходження по елементам списку:
birds = ['pigeon', 'crow', 'owl', 'eagle']
for bird in birds:
print(bird)Результат:
pigeon
crow
owl
eagleСписки, на зразок birds, є прикладом ітеративних об’єктів у Python поряд з рядками, кортежами, словниками.
| Прохід (ітерація) по кортежу або списку повертає один елемент за раз. |
Ітерація по рядку повертає один символ за раз, як показано на цьому прикладі:
word = 'crab'
for letter in word:
print(letter)Результат:
c
r
a
b
Ітерація по словнику у циклі (або з використанням функції keys()) повертає ключі словника.
|
В наступному прикладі ключі словника є назвами сфер діяльності людини, а значення словника - назвами професій:
professions = {'business': 'economist', 'tv': 'newsreader', 'it': 'web developer', 'education': 'teacher'}
for key in professions: # або for key in professions.keys():
print(key)Результат:
business
education
tv
it
Щоб виконувати ітерацію по значенням словника, а не за ключами, необхідно використовувати функцію values().
|
professions = {'business': 'economist', 'tv': 'newsreader', 'it': 'web developer', 'education': 'teacher'}
for value in professions.values():
print(value)Результат:
teacher
newsreader
web developer
economist
Для отримання як ключа, так і значення із словника, ви можете використовувати функцію items(). Результатом буде кортеж із парами «ключ: значення».
|
professions = {'business': 'economist', 'tv': 'newsreader', 'it': 'web developer', 'education': 'teacher'}
for item in professions.items():
print(item)Результат:
('business', 'economist')
('education', 'teacher')
('it', 'web developer')
('tv', 'newsreader')Значення елементів кортежу можна отримати окремо на кожній ітерації. Для кожного кортежу, який повертає функція items(), надайте перше значення (ключ) змінній key, а друге (значення) - змінній value:
professions = {'business': 'economist', 'tv': 'newsreader', 'it': 'web developer', 'education': 'teacher'}
for key, value in professions.items():
print('Category', key, 'has a profession', value)Результат:
Category business has a profession economist
Category education has a profession teacher
Category it has a profession web developer
Category tv has a profession newsreaderСловник завжди підтримує зв’язок між ключем і пов’язаним з ним значенням, але порядок отримання елементів із словника непередбачуваний (до версії Python 3.6).
Один із способів отримання елементів у певному порядку заснований на сортуванні ключів, що повертаються циклом for. Для отримання впорядкованої копії ключів можна скористатися функцією sorted():
favorite_languages = {'john': 'Python', 'catherine': 'C', 'mary': 'Ruby', 'alex': 'Python'}
for name in sorted(favorite_languages.keys()):
print(name.title() + ", thank you for taking the poll.")Така конструкція видає список всіх ключів словника, але впорядкувує їх перед тим, як перебирати елементи.
У результаті на екрані відображаються перераховані всі користувачі, що брали участь в опитуванні, щодо улюблених мов програмування, а їх імена впорядковані за алфавітом:
Alex, thank you for taking the poll.
Catherine, thank you for taking the poll.
John, thank you for taking the poll.
Mary, thank you for taking the poll.6.3.8. Функція enumerate()
У таких мовах, як C, перебір в послідовності ведеться не за елементами послідовності, а за індексами.
Використовуючи індекси, ви можете отримувати елементи із зазначеними індексами. Нижче показаний один з варіантів вирішення цього завдання з використанням вбудованих функцій Python range() і len():
popular_sites = ['Google.com', 'Youtube.com', 'Facebook.com', 'Baidu.com', 'Wikipedia.org', 'Yahoo.com' ,'Amazon.com']
for index in range(len(popular_sites)):
print(index, popular_sites[index])Результат:
0 Google.com
1 Youtube.com
2 Facebook.com
3 Baidu.com
4 Wikipedia.org
5 Yahoo.com
6 Amazon.comЗазвичай, у Python перебір в послідовності виконується для отримання доступу до елементів послідовності, а не до індексів.
Проте, в окремих випадках індекс теж буває потрібен. Python надає вбудовану функцію enumerate(), з використанням якої комбінація функцій range() і len() буде зайвою.
Функція enumerate() повертає кортеж (індекс, елемент) для кожного елемента в послідовності:
popular_sites = ['Google.com', 'Youtube.com', 'Facebook.com', 'Baidu.com', 'Wikipedia.org', 'Yahoo.com' ,'Amazon.com']
for index, value in enumerate(popular_sites, 1):
print(index, value)У прикладі вище, у функції enumerate() був використаний необов’язковий аргумент із значенням 1, який вказує з якого числа починати нумерацію елементів (за замовчуванням лічильник починається з 0):
1 Google.com
2 Youtube.com
3 Facebook.com
4 Baidu.com
5 Wikipedia.org
6 Yahoo.com
7 Amazon.com6.3.9. Функція zip()
Функція zip() використовується для паралельної ітерації по декільком послідовностям одночасно.
|
days = ['Monday', 'Tuesday', 'Wednesday']
fruits = ['coconut', 'lemon', 'mango']
drinks = ['coffee', 'tea', 'fruit juice']
desserts = ['marmalade', 'ice cream', 'pie', 'pudding']
for day, fruit, drink, dessert in zip(days, fruits, drinks, desserts):
print(day, ": drink", drink, "eat", fruit, "enjoy", dessert)Результат:
Monday : drink coffee eat coconut enjoy marmalade
Tuesday : drink tea eat lemon enjoy ice cream
Wednesday : drink fruit juice eat mango enjoy pieФункція zip() припиняє свою роботу, у випадку використання найкоротшої послідовністі. Один зі списків (desserts) виявився довшим за інші, тому ніхто не отримає pudding, поки ми не збільшимо інші списки.
Функцію zip() можна використати, щоб пройти по декільком послідовностям і створити кортежі з елементів із однаковими індексами.
|
Створимо два кортежі з відповідних один одному англійських і французьких слів:
english = 'Monday', 'Tuesday', 'Wednesday'
french = 'Lundi', 'Mardi', 'Mercredi'Використаємо функцію zip(), щоб об’єднати ці кортежі в пару. Значення, що повертається функцією zip(), саме по собі не є списком або кортежем, але його можна перетворити у будь-яку з цих послідовностей, наприклад, у список, з використанням функції list():
print(list(zip(english, french)))Результат:
[('Monday', 'Lundi'), ('Tuesday', 'Mardi'), ('Wednesday', 'Mercredi')]Якщо передати результат роботи функції zip() безпосередньо функції dict() - у нас готовий невеликий англо-французький словник:
print(dict(zip(english, french)))Результат:
{'Wednesday': 'Mercredi', 'Monday': 'Lundi', 'Tuesday': 'Mardi'}6.3.10. Функція map()
Дуже часто виникає необхідність перетворити тип послідовності чи змінити тип елементів послідовності. Наприклад, перетворити список числових рядків у список цілих чисел, або перетворити сам список у кортеж чи множину з набором тим самих значень тощо.
Поглянемо, як це відбувається на практиці. Для наших цілей створимо список my_str_list = ['1', '2', '3', '4'], що містить числові рядки. Перетворимо поданий список у список цілих чисел за допомогою такого коду:
result = []
for item in my_str_list:
result.append(int(item))
print(result)Результат буде таким, як і очікували:
[1, 2, 3, 4]Спробуємо перетворити сам тип послідовності, залишивши той самий набір елементів. Для прикладу, перетворимо початковий список my_str_list у кортеж:
result = tuple()
for item in my_str_list:
result += (item,)
print(result)Результат виконання буде наступним:
('1', '2', '3', '4')Ще один приклад ілюструє перетворення не лише типу послідовності, але й зміну типу елементів в ній:
result = set()
for item in my_str_list:
result.add(float(item))
print(result)У даному випадку відбулося перетворення списку числових рядків у множину дійсних чисел:
{1.0, 2.0, 3.0, 4.0}Усі вищенаведені дії можна виконати з написанням коротшого коду, який, у багатьох випадках, буде виконуватися швидше. У цьому нам допоможе функція map().
Функція map() застосовує вказану функцію (наприклад, int(), float(), str() тощо) до кожного елемента з послідовності (списка, кортежа, множини тощо). Отриманий результат можна перетворити в list(), tuple(), set() тощо.
|
Знову повернемося до практики, використавши список my_str_list = ['1', '2', '3', '4'], що містить числові рядки, і проаналізуємо код нижче в інтерпретаторі Python:
>>> my_str_list = ['1', '2', '3', '4'] (1)
>>> my_str_list
['1', '2', '3', '4']
>>> my_int_list = list(map(int, my_str_list)) (2)
>>> my_int_list
[1, 2, 3, 4]
>>> my_float_list = list(map(float, my_str_list)) (3)
>>> my_float_list
[1.0, 2.0, 3.0, 4.0]
>>> my_new_str_list = list(map(str, my_float_list)) (4)
>>> my_new_str_list
['1.0', '2.0', '3.0', '4.0']
>>> my_tuple = tuple(map(int, my_str_list)) (5)
>>> my_tuple
(1, 2, 3, 4)
>>> my_set = set(map(float, my_str_list)) (6)
>>> my_set
{1.0, 2.0, 3.0, 4.0}
>>> my_newer_str_list = list(map(str, my_tuple)) (7)
>>> print(my_newer_str_list)
['1', '2', '3', '4']-
Створення списку
my_str_listз числовими рядками. -
Використання функції
map(): функціяint()застосовується до кожного елемента списку числових рядківmy_str_listдля перетворення елементів на цілі числа, з яких утворюється списокmy_int_listцілих чисел. -
Використання функції
map(): функціяfloat()застосовується до кожного елемента списку числових рядківmy_str_listдля перетворення елементів на дійсні числа, з яких утворюється списокmy_float_listдійсних чисел. -
Використання функції
map(): функціяstr()застосовується до кожного елемента списку дійcних чиселmy_float_listдля перетворення елементів на рядки, з яких утворюється списокmy_new_str_listз рядками дійсних чисел. -
Використання функції
map(): функціяint()застосовується до кожного елемента списку числових рядківmy_str_listдля перетворення елементів на цілі числа, з яких утворюється кортежmy_tupleз цілими числами. -
Використання функції
map(): функціяfloat()застосовується до кожного елемента списку числових рядківmy_str_listдля перетворення елементів на дійсні числа, з яких утворюється множинаmy_setз дійсними числами. -
Використання функції
map(): функціяstr()застосовується до кожного елемента кортежу з цілих чиселmy_tupleдля перетворення елементів на числові рядки, з яких утворюється списокmy_newer_str_listз числовими рядками.
6.4. Включення (скорочення синтаксису)
Включення дозволяють об’єднувати цикли і умовні перевірки, не використовуючи при цьому громіздкий синтаксис. Це одна з характерних особливостей мови Python. Якщо ви застосовуєте включення, то можна сказати, що вже непогано знаєте Python.
6.4.1. Включення для списків
Наприклад, для створення числового списку можна використати код, вказаний нижче:
number_list = []
for number in range(1, 6):
number_list.append(number)
print(number_list)У результаті отримаємо такий список:
[1, 2, 3, 4, 5]Але більш характерно для Python є створення списку за допомогою включення списку. Проста форма такого включення виглядає так:
[вираз for елемент in ітеративний елемент]
Приклад утворення списку цілих чисел через включення списку:
number_list = [number for number in range(1,6)]
print(number_list)Як видно з прикладу, включення списку переміщує цикл в квадратні дужки. У результаті отримуємо той самий список, що і у попередньому випадку:
[1, 2, 3, 4, 5]В даному випадку перша змінна number (вона є виразом) формує значення для списку number_list. Друга змінна number є частиною циклу for. Щоб показати, що перша змінна number є виразом, спробуємо такий варіант:
number_list = [number-1 for number in range(1,6)]
print(number_list)У результаті отримаємо список із значеннями меншими на 1:
[0, 1, 2, 3, 4]Включення списку може містити умовний вираз, який виглядає приблизно так:
[вираз for елемент in ітеративний елемент if умова]
Для прикладу, створимо нове включення, яке створює список, що складається тільки з непарних чисел, розташованих в діапазоні від 1 до 5.
Використовуйте умови number % 2 == 1 або number % 2 == 0 для відбору, відповідно, непарних або парних чисел.
|
a_list = [number for number in range(1, 6) if number % 2 == 1]
print(a_list)У результаті однієї з умов отримуємо список непарних чисел:
[1, 3, 5]Включення списку з умовою виглядає більш компактно, ніж код, записаний традиційним способом (хоча результати виконання однакові):
a_list = []
for number in range(1, 6):
if number % 2 == 1:
a_list.append(number)
print(a_list)6.4.2. Включення для словників
Для словників також можна створити включення. Найпростіша його форма виглядає так:
{ключ: значення for вираз in ітеративний елемент}
Як і у випадку із включеннями списку, до включення словників також входять перевірки if і оператори for:
word = 'Antarctica'
letter_counts = {letter: word.count(letter) for letter in word}
print(letter_counts)У циклі, проходячи по кожній із літер у рядку Antarctica, обчислюється скільки разів з’являється поточна буква. Команда word.count(letter) викликається кілька разів (на це витрачається додатковий час), так як літери c, a і t зустрічаються по два рази. Але на вміст словника це не впливає, адже коли проходимо букви c, a або t другий раз, то існуючий запис у словнику замінюється на поточне значення:
{'i': 1, 'c': 2, 'a': 2, 'n': 1, 'r': 1, 'A': 1, 't': 2}Наступний спосіб розв’язування задачі більш характерний для Python (використовується функція set(), яка свторює множину лише з унікальних літер слова):
word = 'Antarctica'
letter_counts = {letter: word.count(letter) for letter in set(word)}
print(letter_counts)Ключі словника розміщені в іншому порядку, ніж у попередньому прикладі, але вміст словника той самий:
{'a': 2, 'r': 1, 'i': 1, 'c': 2, 't': 2, 'A': 1, 'n': 1}Розв’язування попередньої задачі традиційним способом буде таким:
word = 'Antarctica'
letter_counts = {}
for letter in set(word):
letter_counts[letter] = word.count(letter)
print(letter_counts)6.5. Генератори
У Python генератор - це об’єкт, який призначений для створення послідовності. За допомогою генераторів можна проходити (ітерувати) по великим послідовностям без необхідності створення і збереження всієї послідовності у пам’ять відразу.
Генератори часто стають джерелом даних для ітераторів.
У поданому нижче прикладі використовується генератор - функція range(), яка генерує послідовність цілих чисел і обчислюється сума чисел від 1 до 50 включно за допомогою функції sum():
>>> sum(range(1,51))
12756.6. Функції
Функції - це іменовані блоки коду, призначені для вирішення однієї конкретної задачі.
Якщо задача повинна розв’язуватися багаторазово у програмі, не потрібно заново вводити увесь необхідний код; викликається функція, призначена для розв’язування задачі, і цей виклик наказує Python виконати код, що міститься всередині функції.
| Функція - це міні-програма у межах основної програми. |
6.6.1. Визначення і виклик функцій
Python надає у використання вбудовані функції, на зразок, len(), print(), input() тощо. Але можна створювати і власні функції.
Використання функцій спрощує читання, написання, налагодження й тестування коду.
Основи налагодження й тестування коду, написаного мовою Python, розглядаються у Додаток E: Налагодження і тестування коду.
|
Функція може приймати будь-яку кількість будь-яких вхідних параметрів і повертати результат у вигляді будь-яких об’єктів (списків, кортежів тощо).
Головною перевагою функцій є можливість повторного використання коду.
Функцію можна:
-
визначити
-
викликати
Для визначення функції, необхідно написати def, ім’я функції, вхідні параметри у круглих дужках, двокрапку, після якої з відступом йде блок коду:
def назва_функції(вхідні параметри): блок коду
| Імена функцій дотримуються таких же правил, що і імена змінних: імена повинні починатися з букви або знака підкреслення і містити тільки букви, цифри або знак підкреслення. |
Cтворимо окремий файл з певним ім’я у вибраному середовищі програмування для наступних прикладів.
Визначимо функцію без вхідних параметрів, яка виводить повідомлення на екран:
def birthday_card():
print('Happy birthday!')Для виклику функції необхідно написати її ім’я і круглі дужки: birthday_card(). Коли викликається функція birthday_card(), Python виконує код всередині функції - виводить повідомлення
Happy birthday!на екран і повертає назад керування основній програмі.
Напишемо ще одну функцію без параметрів, яка повертає значення True і викличемо цю функцію в команді if для перевірки значення, яке повертає функція:
# визначення функції
def hungry():
return True
# виклик функції та перевірка умови
if hungry():
print('Eat oat flakes!')
else:
print('Drink water.')Така комбінація функції з перевіркою умови виведе повідомлення Eat oat flakes!.
Тепер визначимо функцію echo(), яка має один параметр anything. Дана функція використовує оператор return, щоб відправити результат виконання у зовнішню основну програму (звідки викликається функція):
# визначення функції
def echo(anything):
return anything
Викличемо функцію echo(), передавши їй рядок 'I enjoy travelling!', і надрукуємо результат на екрані:
print(echo('I enjoy travelling!'))
Функція print() використовується для друкування на екрані значення, яке повернула функція оператором return.
|
Отримаємо такий результат:
I enjoy travelling!| Значення, які передаються у функцію при виклику, називаються аргументами. Коли викликається функція з аргументами, значення цих аргументів копіюються у відповідні параметри всередині функції. |
В нашому прикладі функції echo() передавалось одне значення - рядок 'I enjoy travelling!'. Це значення копіювалось всередині функції echo() у параметр anything, а потім поверталось у зовнішню програму, звідки викликалась функція.
Визначимо ще одну функцію, яка повертає повідомлення, в залежності від обраного кольору:
def like(interest):
if interest == 'yoga':
return "I quite like " + interest + "."
elif interest == "football":
return "Yes, I play " + interest + "."
elif interest == 'guitar':
return "Yes, I play the " + interest + "."
else:
return "I'm interested in " + interest + "."
story = like('photography')
print(story)
story = like('yoga')
print(story)
story = like('football')
print(story)
story = like('guitar')
print(story)Функція like() виконає такі дії:
-
параметру функції
interestприсвоїть значення'photography'('yoga','football','guitar') -
пройде по ланцюжку
if-elif-else -
поверне рядок з повідомленням
-
присвоїть повернений рядок змінній
story
А результатом виконання команд print(story) будуть такі повідомлення:
I'm interested in photography.
I quite like yoga.
Yes, I play football.
Yes, I play the guitar.6.6.2. Значення None
Для прикладу, визначимо функцію, яка не має параметрів:
def do_nothing():
pass
pass - оператор-заглушка, рівноцінний відсутності операції.
|
В даній ситуації pass вказує Python, що функція нічого не робить. Викличемо дану функцію:
do_nothing()Функція do_nothing() відпрацює, але нічого не виведе на екран.
Викличемо цю ж функцію з використанням функції print():
print(do_nothing())У результаті отримаємо значення:
None
Якщо функція не використовує оператор return явно, вона повертає результат None.
|
None - це константа, що представляє відсутність значення, тобто означає нічого або порожнє місце. Значення None не є булевим значенням False.
|
Напишемо невелику функцію, яка виводить перевірку на рівність None:
def is_none(thing):
if thing is None:
print("It's None")
elif thing:
print("It's True")
else:
print("It's False")і виконаємо кілька перевірок:
is_none(None) # It's None
is_none(True) # It's True
is_none(False) # It's False
is_none(0) # It's False
is_none(0.0) # It's False
is_none(()) # It's False
is_none([]) # It's False
is_none({}) # It's False
is_none(set()) # It's False6.6.3. Позиційні та іменовані аргументи
Коли ми визначаємо функцію, то можемо вказати кілька параметрів, а при виклику функції можемо передати їй кілька аргументів. Існує кілька способів передачі аргументів функціям.
Найбільш поширений тип аргументів - це позиційні аргументи, чиї значення копіюються у відповідні параметри функції згідно порядку слідування. Тому, варто пам’ятати кожну позицію аргументів.
Визначимо функцію, яка створює і повертає словник з вхідних позиційних аргументів:
def music(terminology, musician, genre):
return {'terminology': terminology, 'musician': musician, 'genre': genre}В даному випадку, у визначенні функції music, значення у круглих дужках terminology, musician, genre - це параметри функції.
Викличемо функцію командою print(music('tune', 'guitarist', 'blues')). Значення tune, guitarist, blues у виклику функції і є позиційними аргументами, які будуть скопійовані у відповідні параметри функції і вона поверне словник (порядок у словнику непередбачуваний до версії Python 3.6):
{'terminology': 'tune', 'musician': 'guitarist', 'genre': 'blues'}Аргументи у виклику функції можна вказувати і за допомогою іменованих аргументів - імен відповідних параметрів. Порядок слідування аргументів, у цьому випадку, може бути яким завгодно:
print(music(terminology='tune', musician='guitarist', genre='blues'))У даному виклику функції music: musician - це ім’я аргументу, а 'guitarist' - значення аргументу. Аналогічно і для інших імен і значень аргументів. У результаті словник набуде такого вигляду:
{'terminology': 'tune', 'musician': 'guitarist', 'genre': 'blues'}Можна, також, об’єднувати позиційні аргументи та іменовані аргументи, тільки позиційні аргументи завжди вказуються першими:
print(music('tune', musician='guitarist', genre='blues'))Результат виведення:
{'terminology': 'tune', 'musician': 'guitarist', 'genre': 'blues'}6.6.4. Значення за замовчуванням
Для кожного параметра функції можна визначити значення за замовчуванням.
Якщо при виклику функції передається аргумент, який відповідає цьому параметру, Python використовує значення аргументу, а якщо немає - використовує значення за замовчуванням. Таким чином, якщо для параметра визначено значення за замовчуванням, ви можете опустити відповідний аргумент, який зазвичай входить у виклик функції.
Визначимо функцію, яка повертає інформацію про домашнього улюбленця:
def describe_pet(pet_name, animal_type='parrot'):
print("I have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")У визначення функції describe_pet() включений параметр animal_type із значенням за замовчуванням 'parrot'. Якщо тепер функція буде викликана з іменованим аргументом pet_name='Jack Sparrow', але без аргумента animal_type
describe_pet(pet_name='Jack Sparrow')Python знатиме, що для параметра animal_type слід використовувати значення 'parrot':
I have a parrot.
My parrot's name is Jack Sparrow.Для виведення інформації про будь-яку іншу домашню тварину, окрім папуги, використовується виклик функції describe_pet() наступного виду:
describe_pet(pet_name='peppa', animal_type='guinea pig')Так як аргумент для параметра animal_type у виклику функції заданий явно ('guinea pig'), Python ігнорує значення параметра за замовчуванням:
I have a guinea pig.
My guinea pig's name is Peppa.6.6.5. Використання аргументів з символами * і **
Якщо символ * буде використаний усередині функції з параметром, довільна кількість позиційних аргументів буде згрупована у кортеж. В наступному прикладі визначення функції print_days()
def print_days(*args):
print('Get ready:', args)args є кортежем параметрів. Всі аргументи, які ви передасте у функцію print_days()
print_days('Wednesday', 'Thursday', 'Friday', 'Weekend...')будуть виведені на екран як кортеж args:
Get ready: ('Wednesday', 'Thursday', 'Friday', 'Weekend...')Це корисно при написанні функцій, на зразок print(), які приймають довільну кількість аргументів. Наприклад, якщо у функції
def print_travel(required1, required2, *args):
print('For train travel is required:', required1)
print('For train travel is required too:', required2)
print('All the rest:', args)є також обов’якові параметри (в даному випадку required1 і required2), у які будуть скопійовані значення позиційних аргументів ('return ticket', 'train') при виклику функції
print_travel('return ticket', 'train', 'carriage', 'seat', 'luggage rack')то кортеж *args отримає всі інші аргументи, починаючи із значення 'carriage':
For train travel is required: return ticket
For train travel is required too: train
All the rest: ('carriage', 'seat', 'luggage rack')Ви можете використовувати два символа **, щоб згрупувати іменовані аргументи у словник, де імена аргументів стануть ключами, а їх значення - відповідними значеннями у словнику.
У наступному прикладі визначається функція print_character()
def print_character(**kwargs):
print('Person\'s characteristics:', kwargs)при виклику якої з іменованими аргументами
print_character(emotions='cheerful', sense='happy', look='slim')виводяться її іменовані аргументи у вигляді словника:
Person's characteristics: {'emotions': 'cheerful', 'sense': 'happy', 'look': 'slim'}
При використанні символа * не потрібно обов’язково називати кортеж параметрів args, аналогічно при використанні символів ** називати словник параметрів kwargs, однак це поширена практика у Python.
|
6.6.6. Анонімні функції: інструкція lambda
Python дозволяє в короткій формі оголошувати невеликі анонімні функції - лямбда-функції.
Вони ведуть себе точно так само, як і звичайні функції, які оголошуються ключовим словом def.
Анонімні функції можуть містити лише один вираз, але й виконуються вони швидше.
Часто такі маленькі функції потрібно передавати іншим функціям, як у випадку з ключовою функцією, яка використовується як спосіб сортування списку. У таких випадках великі функції зазвичай не потрібні, і було б незручно визначати функцію десь окремо від місця її виконання.
Анонімні функції створюються за допомогою інструкції lambda:
add = lambda x, y: x + yТа ж сама функція add може бути визначена за допомогою ключового слова def:
def add(x, y):
return x + yВиконавши код
print(add(7, 8))ми отримаємо однаковий результат в обох випадках:
15Крім цього, анонімну функцію не обов’язково присвоювати змінній
print((lambda x, y: x + y)(5, 12))і lambda-функції, на відміну від звичайної, не потрібна інструкція return:
17При виконанні лямбда-функції обчислюється її вираз, а потім результат виразу автоматично повертається, тому завжди існує неявна інструкція return.
В яких випадках в програмному коді слід застосовувати лямбда-функції? Дуже часто, як вище було наголошено, лямбда-функції використовують для написання коротких функцій для сортування об’єктів за альтернативним ключем:
months = [(1, 'January'), (9, 'September'), (7, 'July'), (4, 'March')]
print(sorted(months, key=lambda x: x[1]))
print(sorted(months))У наведеному вище прикладі ми сортуємо список кортежів по другому значенню в кожному кортежі. В даному випадку лямбда-функція забезпечує швидкий спосіб зміни порядку сортування:
[(1, 'January'), (7, 'July'), (4, 'March'), (9, 'September')]
[(1, 'January'), (4, 'March'), (7, 'July'), (9, 'September')]6.7. Обробка помилок
6.7.1. Виняткові ситуації
Для управління помилками, що виникають у ході виконання програми, в Python використовуються спеціальні об’єкти, які називаються винятками.
Якщо при виникненні помилки Python не знає, що робити далі, створюється об’єкт винятку. Якщо у програму включений код обробки виняткової ситуації, то виконання програми продовжиться, а якщо немає - програма зупиняється і виводить трасування (інформацію про хід виконання програми) зі звітом про помилку.
Щось схоже можна спостерігати, коли спробувати отримати доступ до елемента, що не входить у список або кортеж, отримати значення елемента у словнику по ключу, якого не існує. Коли виконується код, який при деяких обставинах може не спрацювати, використовують обробники винятків, щоб перехопити будь-які потенційні помилки.
Хорошим тоном є використання обробників винятків всюди, де може бути згенеровано виняток, щоб користувач знав, що відбувається. Ви можете бути не в змозі виправити помилку, але принаймні можете дізнатися, за яких обставин це сталося, і акуратно завершити програму.
Можна також створювати власні об’єкти винятків.
6.7.2. Блок try-except
Якщо не використовувати обробники винятків, Python виведе повідомлення про помилку і деяку інформацію про те, де сталася помилка, а потім завершить програму, як показано в наступному фрагменті коду:
short_list = [1, 2, 3]
position = 5
print(short_list[position])Виникає помилка виходу за межі діапазону списку:
Traceback (most recent call last):
File "C:\Python34\test.py", line 246, in <module>
print(short_list[position])
IndexError: list index out of rangeРозмістимо свій код у блоці try і використаємо блок except, щоб обробити помилку:
short_list = [1, 2, 3]
position = 5
try:
short_list[position]
except:
print('Need a position between 0 and', len(short_list)-1, 'but got', position)В результаті виконання програми отримаємо повідомлення:
Need a position between 0 and 2 but got 5Код у даному прикладі запускається всередині блока try. Якщо виникла помилка, генерується виняток і виконується код, розміщений всередині блока except. Якщо помилки не виникають в процесі виконання програми, блок except буде не задіяний.
В даному випадку використання блока except говорить лише: «Виникла помилка!». Якщо ви припускаєте, що в програмі може статися помилка і знаєте назву винятку, який при цьому згенерується, напишіть блок try-except для обробки відомого винятка.
Для прикладу, розглянемо виконання операції
print(5/0)яка викликає помилку ділення на нуль, при якій Python ініціює виняток ZeroDivisionError:
Traceback (most recent call last):
File "C:\Python34\test.py", line 266, in <module>
print(5/0)
ZeroDivisionError: division by zeroПомилка ZeroDivisionError - є об’єктом винятку. Повідомимо Python, як слід чинити при виникненні даного винятку, щоб програма буде підготовлена до його появи. Ось як виглядає блок try-except для обробки винятків ZeroDivisionError:
try:
print(5/0)
except ZeroDivisionError:
print("You can't divide by zero!")У цьому прикладі код блоку try породжує помилку ZeroDivisionError, тому Python шукає блок except з описом того, як слід діяти в такій ситуації. При виконанні коду блоку except користувач бачить зрозуміле повідомлення про помилку:
You can't divide by zero!Інколи необхідно отримати не лише об’єкт винятку, а зберегти його у змінну, використовуючи таку форму запису:
try:
блок коду
except тип_винятку as назва_змінної:
блок коду, коли виникла помилка
У наступному прикладі виконується перевірка на IndexError, оскільки саме цей виняток викликається, коли ви вказуєте недійсну (відсутню) позицію у послідовності. Виняток IndexError зберігається у змінній err, а будь-який інший виняток Exception - у змінній other:
predators = ['tiger', 'wolf', 'bear']
while True:
value = input('Position [q to quit]? ')
if value == 'q':
break
try:
position = int(value)
print(predators[position])
except IndexError as err:
print('Bad index:', position)
except Exception as other:
print('Something else broke:', other)У прикладі на екран виводиться все, що зберігається в змінній other:
Position [q to quit]? 1
wolf
Position [q to quit]? 0
tiger
Position [q to quit]? 2
bear
Position [q to quit]? 3
Bad index: 3
Position [q to quit]? 2
bear
Position [q to quit]? two
Something else broke: invalid literal for int() with base 10: 'two'
Position [q to quit]? qВведення позиції 3, як і очікувалося, генерує виняток IndexError. Введення слова two «не сподобалось» функції int(), яка була оброблена у другому обробнику винятку.
Є ще дві інструкції, пов’язані з блоком try-except, це finally і else.
Команда finally виконує блок інструкцій в будь-якому випадку, чи було згенерований виняток, чи ні (це корисно для випадків, коли необхідно обов’язково щось зробити, наприклад закрити файл або мережеве з’єднання).
Інструкція else виконується в тому випадку, якщо виняток не буде згенерований.
Наприклад, при виконанні фрагмента коду
def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("Division by zero!")
else:
print("Result is", result)
finally:
print("End of the calculation.")
divide(2, 1)
divide(2, 0)отримаємо наступні результати:
Result is 2.0
End of the calculation.
Division by zero!
End of the calculation.
Основні помилки, що можуть виникнути при написанні програм на Python і шляхи їх виправлення можна переглянути у Додатку D: Код не працює: типові помилки.
|
Переглянути список винятків, які генеруються у разі появи помилок, можна на сайті офіційної документації Python.
|
Можна також визначити власні типи винятків, щоб обробляти особливі ситуації, які можуть виникнути у програмах.
| Для визначення власних винятків необхідно використовувати класи, які описуються у Розділі 10. |
6.8. Завдання
6.8.1. Контрольні запитання
-
Які два значення має булевий тип даних?
-
Назвіть три булевих оператори і шість операторів порівняння.
-
Напишіть кілька прикладів із таблиць істинності.
-
Яка різниця між операторами порівняння і присвоювання?
-
Що таке вказівка розгалуження і де вона використовується?
-
Наведіть приклади виразів, що можуть використовуватись як умова.
-
Яке сполучення клавіш використовується для виходу з нескінченного циклу?
-
Чим відрізняються виклики функцій
range(15),range(0, 15),range(0, 15, 1)у цикліfor? -
Навіщо використовувати у програмах функції?
-
Коли виконується код функції: коли вона визначається, чи коли вона викликається?
-
З допомогою якої конструкції створюються функції?
-
Чим відрізняється визначення функції від її виклику?
-
Скільки глобальних областей видимості може мати програма на
Python? Скільки локальних? -
Що таке «значення, яке повертає функція»? Чи може бути це значення у вигляді виразу?
-
Що відбувається із змінними, які знаходяться у локальній області видимості, при поверненні їх із функції?
-
Яке значення повертає функція, якщо у ній відсутній оператор
return? -
Як змусити змінну у функції посилатися на глобальну змінну?
-
Що таке тип даних
None? -
Як можна запобігти аварійному завершенню програми?
-
Які блоки коду записують у блок
try? А які уexcept?
6.8.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Які результати обчислення таких виразів?
(15 > 8) and (2 == 9)
not (2 > 1)
(6 > 3) or (8 == 7)
not ((9 > 4) or (3 == 4))
(True and True) and (True == False)
(not False) or (not True)-
Напишіть код, який виводить різні повідомлення, в залежності від значення, що зберігається у змінній
weather_forecast:What a beautiful day!, якщо значення змінної дорівнюєsun,Take an umbrella!, якщо значення змінної дорівнюєrainіThe sun’s just gone in!– у іншому випадку. -
Створіть програму, яка виводить повідомлення про кількість очок, які отримав гравець у комп’ютерній грі. Створіть змінну з ім’ям
points_colorі надайте їй значення'green','yellow'або'red'. Якщо зміннаpoints_colorмістить значення'green', виведіть повідомлення про те, що гравець отримав5очок, якщо'yellow'-10очок, якщо'red', виведіть повідомлення про те, що гравець отримав15очок. -
Напишіть ланцюжок
if-elif-elseдля визначення віку людини. Надайте значення зміннійage, а потім виведіть повідомлення. Якщо значенняageменше2-baby, якщо значенняageбільше або дорівнює2, але менше4-kid, якщо значенняageбільше або дорівнює4, але менше13-child, якщо значенняageбільше або дорівнює13, але менше20-teenager. якщо значенняageбільше або дорівнює20, але менше65-grown-up, якщо значенняageбільше або дорівнює65-senior. -
Створіть список трьох своїх улюблених фруктів і назвіть його
favorite_fruits. Напишіть перевірку на те, чи входить фрукт у список. Якщо фрукт входить у список, виводиться повідомлення, на зразокYou really like peaches!, у протилежному випадку - повідомлення про відсутність фрукту у списку. -
Використайте цикл
for, щоб вивести на екран в окремих рядках значення списку[5, 4, 3, 2, 1, 0, 'GO!']. -
Використайте функцію
zip(), щоб створити словникmovies, який об’єднує у пари списки:seasons = ['summer', 'autumn']іmonths = [ 'july', 'november']. Виведіть вміст словника. -
Використайте відомі вам структури коду для виведення ключів і значень словника
activity = {'business': 'manager', 'it': 'software developer', 'science': 'scientist'}у вигляді, на зразок «категорія: професія». -
Використайте включення списку, щоб створити список, який містить парні числа у діапазоні
range(12). -
Використайте включення словника, щоб створити словник
squaresз ключами у вигляді цілих чисел з діапазонуrange(1, 11). Значення словника формуються піднесенням ключів до другого степеня. -
Використайте цикл
forдля виведення чисел від1до15включно, в один рядок і пропусками між ними. -
Створіть список чисел від
1до1 000 000. Скористайтеся функціямиmin()іmax()та переконайтеся у тому, що список дійсно починається1і закінчується1 000 000. Викличте функціюsum()і подивіться, наскільки швидкоPythonзможе підсумувати мільйон чисел. -
Cкористайтеся третім аргументом функції
range()для створення списку непарних чисел від1до25і виведіть усі числа в окремих рядках у цикліfor. -
Створіть список перших
10кубів (тобто кубів усіх цілих чисел від1до10) і виведіть значення усіх кубів у цикліforв один рядок з пропусками. -
Cтворіть список чисел у діапазоні від
3до60і виведіть усі числа списку у цикліwhileв окремих рядках. -
Визначте функцію
trees, яка повертає список['poplar', 'willow', 'lime']. Викличте функцію. -
Напишіть функцію
favorite_book(), яка отримує один параметрtitle. Функція повинна виводити повідомлення, на зразокOne of my favorite books is "The Lord of the Rings".. Викличте функцію і переконайтеся у тому, що назва книги правильно передається як аргумент при виконанні функції. -
Напишіть функцію
make_shirt(), яка отримує розмір футболки і текст, який повинен бути надрукований на ній. Функція повинна виводити повідомлення з розміром і текстом. Викличте функцію з використанням позиційних аргументів. Викличте функцію вдруге з використанням іменованих аргументів. Змініть функціюmake_shirt(), щоб футболки за замовчуванням мали розмірXL, і на них виводився текстI love Python!. Створіть футболку з розміромXLі текстом за замовчуванням. -
Напишіть функцію
city_country(), яка отримує назву міста і країну. Функція повинна повертати рядок у форматіKyiv, Ukraine. Викличте функцію як мінімум для трьох пар «місто-країна». -
Визначте виняток, який називається
MyException. Згенеруйте його, щоб побачити, що станеться. Потім напишіть код, що дозволяє перехопити цей виняток і вивести рядокThis is my exception.. -
При введенні числових даних часто зустрічається типова проблема: користувач вводить текст замість чисел. При спробі перетворити дані в
intгенерується винятокTypeError. Напишіть функцію, яка приймає два числа, шукає їх суму і виводить результат. Перехопіть винятокTypeError, якщо будь-яке із вхідних значень не є числом, і виведіть зручне повідомлення про помилку. Протестуйте функцію: спочатку введіть два числа, а потім введіть текст замість одного з чисел.
6.8.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Виведіть вітальне повідомлення для кожного користувача після його входу на сайт. Cтворіть список з кількох імен користувачів, включаючи ім’я
'Admin'. Перебираючи елементи списку, виведіть повідомлення для кожного користувача. Для користувача з ім’ям'Admin'виведіть особливе повідомлення - наприклад:Hello Admin, I hope you’re well.. У інших випадках виводиться універсальне привітання - наприклад:Hello Alex, thank you for logging in again.. Додайте командуif, яка перевірить, що список користувачів не порожній. Якщо список порожній, виведіть повідомлення:We need to find some users!. Видаліть зі списку всі імена користувачів і переконайтеся у тому, що програма виводить правильне повідомлення. -
Визначте назву геометричної фігури за введеною кількістю її сторін. Програма повинна підтримувати фігури від
3до6сторін. Якщо введена кількість сторін поза межами цього діапазону, програма повинна відображати відповідне повідомлення. -
Порядкові числівники у англійській мові закінчуються суфіксом
th(окрім1st,2ndі3rd). Cтворіть список чисел від1до9. Використайте ланцюжокif-elif-elseу циклі для виведення правильного закінчення числівника для кожного числа. Програма повинна виводити числівники1st 2nd 3rd 4th 5th 6th 7th 8th 9th, кожен у новому рядку. -
Зчитайте ціле число введене користувачем і виведіть повідомлення про те, чи число парне або непарне.
-
Зчитайте назву місяця від користувача як рядок і виведіть кількість днів у вказаному місяці. Врахувати те, що «February» може мати
28або29днів. -
Потрібно визначити, чи є даний рік високосним. Нагадаємо, що високосними роками вважаються ті роки, порядковий номер яких або кратний
4, але при цьому не кратний100, або кратний400(наприклад,2000-й рік був високосним, а2100-й буде невисокосним роком). Програма повинна коректно працювати на числах від1900до3000років. ВиведітьLeap year.у разі, якщо рік є високосним іOrdinary year.у протилежному випадку. -
Зчитайте зі стандартного вводу цілі числа, по одному числу у рядку, і після першого введеного нуля виведіть суму отриманих на вхід чисел.
-
Зчитайте цілі числа, які вводить користувач, по одному числу у рядку. Для кожного введеного числа виконайте перевірку: якщо число менше
10, то пропускаємо це число, якщо число більше100, то припиняємо зчитувати числа. У інших випадках вивести це число в окремому рядку. -
Напишіть простий калькулятор, який зчитує три рядки, які вводить користувач: перше число, друге число і операцію, після чого застосовує операцію до введених числах («перше число» «операція» «друге число») і виводить результат на екран. Підтримувані операції:
+,-,/,*,mod,pow,div, деmod- це взяття залишку від ділення,pow- піднесення до степеня,div- цілочисельне ділення. У випадку ділення на0, необхідно використати обробник винятку, який має вивести повідомленняDivision by zero!. -
Виведіть імена видатних особистостей України, зображених на грошових знаках. Користувач вводить номінал банкноти . Програма виводить значення номіналу і ім’я особи, яка зображена на цій банкноті. Якщо користувач вводить неіснуюче значення номіналу, на екран виводиться відповідне повідомлення.
-
Створіть програму, яка зчитує позицію шахової фігури від користувача і повідомляє про колір квадрату, де знаходиться фігура. Наприклад, якщо користувач вводить
aі1, то програма повинна повідомити, що квадрат має колірblack, якщоdі5- програма повідомляє, що квадрат має колірwhite.

-
Чи є рядок «паліндромом»? Рядок є паліндромом, якщо він однаково читається зліва направо та справа наліво. Наприклад, слова
Level,Noon,Annaє паліндромами, незалежно від регістру літер. Рядки, які треба перевірити, вводяться користувачем. Введення даних можна перервати, якщо ввести словоescape. Програма повинна вивести результат перевірки у вигляді повідомленняis a palindromeабоis not a palindrome. -
Створіть таблицю множення. Розмірність таблиці (кількість рядків і стовпців) вводиться з клавіатури.
-
Як відомо, День програміста припадає на
256день року, у невисокосний рік це13вересня, а у високосний -12. Дізнайтеся число і номер місяця, що припадають на день, за номеромn, який вводиться користувачем, у невисокосному2017році. -
Конвертуйте десяткове число (з основою
10) у бінарне (двійкове, з основою2). Користувач вводить десяткове число як ціле, а потім використовується алгоритм поділу (псевдокод), показаний нижче, щоб виконати перетворення. Коли алгоритм завершується, результат містить двійкове подання числа. Програма має вивести відповідне повідомлення, на зразок:2018 in Decimal is 11111100010 in Binary. Модифікуйте програму таким чином, щоб вона виконувала зворотну операцію: перетворювала двійкове чило у десяткове.
Нехай result буде порожнім рядком
Нехай q представляє ціле число для перетворення
Повторити
Встановити r рівним остачі, коли q ділиться на 2
Перетворити r у рядок та додати його на початку до result
Розділити q на 2, відкидаючи будь-який залишок, і зберегти результат назад у q
Поки q не дорівнює 0
Вивести повідомлення про результат переведення-
Реалізуйте шифр Цезаря. Один з перших відомих прикладів шифрування був використаний Юлієм Цезарем. Цезар надавав письмові вказівки своїм генералам, але він не бажав, зрозуміло, щоб про них знали вороги. У результаті він створив власне шифрування, що згодом стало відоме як шифр Цезаря. Ідея цього шифру проста (і, як наслідок, вона не забезпечує серйозного захисту). Кожна буква в оригінальному повідомленні зміщується на
3позиції. В результатіAстаєD,BстаєE,CстаєF,DстаєGі т. д. Останні три букви у алфавіті повертаються до початку:XстаєA,YстаєB, аZстаєC. Нелітерні символи не враховуються шифром. Користувач вводить з клавітури повідомлення та зсув, а потім програма відображає зашифроване повідомлення. Переконайтеся, що програма шифрує як великі та малі літери. Програма також повинна підтримувати значення негативних зсувів, щоб її можна було використовувати як для кодування повідомлень, так і для декодування повідомлень. У нагоді стануть такі функції:ord()(перетворює символ у номер позиції цього символу у таблиці ASCII ) іchr()(перетворює номер позиції символу у таблиціASCIIу відповідний символ). -
У програмі визначте функцію, яка генерує випадковий пароль. Пароль має бути довільної довжини від
7до10символів. Кожен символ паролю повинен бути випадково обраним з позицій33до126з таблиці кодів ASCII . Функція повертає випадково сформований пароль як єдиний її результат і він виводиться в основній програмі. Скористайтеся вказівками з попередньої задачі. -
Напишіть програму, у якій комп’ютер генерує випадкове число, а користувач повинен вгадати число, вводячи його з клавіатури за вказану кількість спроб.
-
Створіть програму за мотивами відомої гри «Камінь, Ножиці, Папір». Застосуйте функціональний підхід при написанні коду програми.
7. Модулі і пакети
У багатьох мовах програмування існує концепція бібліотек, або блоків коду, призначених для повторного використання.
Python також має в своєму арсеналі велику добірку бібліотек, що спрощують роботу з кодом. В базовий дистрибутив Python входить повнофункціональна стандартна бібліотека,
яка дозволяє впоратися з широким спектром задач без необхідності установки додаткових бібліотек.
Те, що вважається стандартною бібліотекою в Python, складається з декількох компонентів, до яких входять вбудовані типи даних і константи, які можуть використовуватися без команди імпортування, як, наприклад, числа і списки.
Будь-якій програмі на мові Python доступний базовий набір вбудованих функцій, в число яких входять такі функції як print(), input(), len() тощо, які можна використовувати у програмі, як кажуть, «з коробки».
Але найбільшою частиною стандартної бібліотеки є велика добірка модулів для роботи з різними типами даних, взаємодії з операційною системою, для написання серверів і клієнтів для багатьох протоколів Інтернету, розробки та налагодження вашого коду.
Наприклад, модуль math містить математичні функції, модуль random - функції для роботи з випадковими числами.
7.1. Що таке модуль?
Модуль являє собою файл з програмним кодом. Він визначає групу функцій Python або інших об’єктів, а ім’я модуля визначається ім’ям файла.
Модулі часто містять початковий код Python, але вони також можуть містити скомпільовані об’єктні файли C і C++. Скомпільовані модулі і модулі Python з початковим кодом використовуються однаково.
Багато стандартних функцій Python не вбудовані в основне ядро мови, а надаються конкретними модулями, що завантажуються в міру необхідності.
|
Крім групування взаємозалежних об’єктів Python, модулі сприяють запобіганню конфліктів імен.
Наприклад, ви пишете для своєї програми модуль з ім’ям firstmodule, який визначає функцію rounded. У тій же програмі може використовуватися модуль secondmodule, який також визначає функцію з ім’ям rounded, яка виконує якусь відмінну від вашої функції rounded дію.
Завдяки модулям у Python, можна використовувати дві різні функції з одним ім’ям rounded: ви просто звертаєтеся в програмі до функцій з іменами firstmodule.rounded і secondmodule.rounded.
Використання імен модулів допомагає відокремити дві функції rounded одну від одної. Завдяки тому, що кожен модуль має власний простір імен, це запобігає конфлікту імен.
7.2. Простір імен і області видимості
Програми в Python можуть мати різні простори імен - розділи, всередині яких певне ім’я унікальне і не пов’язане з такими ж іменами в інших просторах імен.
Простір імен в Python представляє собою спосіб зберігання в Python інформації про активні змінні й про ті об’єкти, на які вони вказують.
У блоці коду, що виконується в Python, є три простори імен: локальний, глобальний і вбудований.
Коли під час виконання програми з’являється змінна, Python спочатку шукає її в локальному просторі імен. Якщо змінна не була знайдена, пошук триває в глобальному просторі імен. Якщо змінну і тут не виявлено, перевіряється вбудований простір імен.
Якщо змінна не існує, Python вирішує, що сталася помилка, і повертає виняток NameError.
Для модуля, команди, виконаної в інтерактивному сеансі або в сценарії, запущеному з файла, глобальні та локальні простори імен збігаються. Створення будь-якої змінної або функції, або імпортування чого-небудь з іншого модуля призводить до появи нового елемента в цьому просторі імен.
Але при виконанні функції створюється локальний простір імен, в якому для кожного параметра виклику створюється окремий елемент. Далі нові елементи вводяться в локальний простір імен кожного разу, коли всередині функції створюється змінна.
Тобто, якщо ви визначите змінну, яка називається a в основній програмі, і іншу змінну a в окремій функції, вони будуть посилатися на різні значення. Але, якщо необхідно, ви можете отримати доступ до імен інших просторів імен різними способами.
| В основній програмі визначається глобальний простір імен, тому змінні, що знаходяться у цьому просторі імен, є глобальними. |
Значення глобальної змінної можна отримати всередині функції. Наприклад, визначимо глобальну змінну animal і функцію print_global():
animal = 'kangaroo'
def print_global():
print('inside print_global:', animal)Використавши функцію print() і виклик функції print_global()
print('at the top level:', animal)
print_global()отримаємо значення змінної animal в обох випадках:
at the top level: kangaroo
inside print_global: kangarooАле якщо спробувати отримати значення глобальної змінної і змінити його всередині функції
animal = 'kangaroo'
def change_and_print_global():
print('inside change_and_print_global:', animal)
animal = 'giraffe'
print('after the change:', animal)
change_and_print_global()то отримаємо помилку:
...
... line 3, in change_and_print_global
print('inside change_and_print_global:', animal)
UnboundLocalError: local variable 'animal' referenced before assignmentassignmentРозглянемо програму з іншою функцією, яка містить змінну з такою ж назвою, що і глобальна змінна animal:
animal = 'kangaroo' (1)
def change_local():
animal = 'giraffe' (2)
print('inside change_local:', animal, id(animal)) (3)
change_local()
print(animal)
print(id(animal)) (4)В результаті виконання програми отримаємо:
inside change_local: giraffe 47293440
kangaroo
47287896-
Ми присвоїли рядок
'kangaroo'глобальній змінній з іменемanimal. -
Функція
change_local()також має зміннуanimal, але ця змінна знаходиться в локальному просторі імен функції. -
Ми використали функцію
id(), щоб вивести на екран унікальне значення об’єктаanimalвсередині функції. -
Ми використали функцію
id(), щоб вивести на екран унікальне значення об’єктаanimalззовні функції.
Порівнюючи результати роботи функції id(), можна зробити висновок: змінна animal, розміщена всередині функції change_local() - це не змінна, що знаходиться на рівні основної програми. Це два об’єкти, що посилаються на різні ділянки в пам’яті комп’ютера.
Щоб змінна всередині функції була видимою в основній програмі, потрібно явно використовувати ключове слово global. Перепишемо попередню програму таким чином
animal = 'kangaroo'
def change_and_print_global():
global animal
animal = 'giraffe'
print('inside change_and_print_global:', animal)
print(animal) (1)
change_and_print_global() (2)
print(animal) (3)і, виконавши її, отримаємо наступні результати:
kangaroo (1)
inside change_and_print_global: giraffe (2)
giraffe (3)-
До виклику функції
change_and_print_global()глобальна зміннаanimalмала значення'kangaroo'. -
Виклик функції
change_and_print_global()з використанням ключового словаglobalу функції перетворив локальну зміннуanimalна глобальну і переписав її значення з'kangaroo'на'giraffe'. -
Тепер змінна
animalв основній програмі має значення'giraffe'.
В даному випадку, змінна animal посилається також на два різні об’єкти до перетворення її на глобальну і після цього.
Якщо не використовувати ключове слово global всередині функції, Python використовує локальний простір імен і змінна буде локальною. Вона зникає після того, як функція завершує роботу.
|
Python надає дві функції для доступу до вмісту ваших просторів імен:
-
locals()- повертає словник, що містить імена локального простору імен -
globals()- повертає словник, що містить імена глобального простору імен
Ці функції використовуються так:
animal = 'kangaroo' # глобальна змінна
def change_local():
animal = 'giraffe' # локальна змінна
print('locals:', locals()) (1)
print(animal)
change_local()
print('locals:', locals()) (2)
print('globals:', globals()) (3)
print(animal)Результат використання цих функцій:
kangaroo
locals: {'animal': 'giraffe'} (1)
locals: {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000021BB6A8C748>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:\\Python36\\namespace.py', '__cached__': None, 'animal': 'kangaroo', 'change_local': <function change_local at 0x0000021BB6901E18>} (2)
globals: {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000021BB6A8C748>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:\\Python36\\namespace.py', '__cached__': None, 'animal': 'kangaroo', 'change_local': <function change_local at 0x0000021BB6901E18>} (3)
kangaroo-
Як бачимо з прикладу, локальний простір імен функції
change_local()містить лише локальну зміннуanimalзі значенням'giraffe'. -
Локальний простір імен змінних в основній програмі містить окрему змінну
animalзі значенням'kangaroo'і багато інших змінних, імена яких починаються і закінчуються з__. -
Глобальний простір імен змінних в основній програмі містить окрему змінну
animalзі значенням'kangaroo'і багато інших змінних, імена яких починаються і закінчуються з__.
Як бачимо, глобальні та локальні простори імен змінних основної програми збігаються. Вони містять три вхідні пари «ключ: значення», призначені для внутрішнього використання Python:
-
рядок документації
__doc__ -
ім’я основного модуля
__name__(для інтерактивних сеансів і сценаріїв, запущених з файлів, завжди містить__main__) -
модуль, який використовується для вбудованого простору імен (модуль
__builtins__).
Вбудованим простором імен є простір імен модуля __builtins__. Цей модуль містить всі вбудовані функції, такі, як len(), min(), max(), int(), float(), list(), tuple(), range(), str() та інші.
|
Зверність увагу, іноді збиває з пантелику той факт, що ви можете перевизначати елементи у вбудованому модулі __builtins__.
Щоб зрозуміти, про що йде мова, використаємо інтерактивний режим інтерпретатора Python.
Наприклад, якщо створити список і зберегти його в змінній з ім’ям list, ви в подальшому не зможете використовувати вбудовану функцію list() із вбудованого простору імен:
>>> list = [1, 2, 3] (1)
>>> list((4, 5, 6)) (2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object is not callable-
Створення списку із ім’я
list, яке вже зарезервоване функціюlist(). -
Спроба використати функцію
list()для перетворення кортежу(4, 5, 6)у список є невдалою, так як тепер ім’яlist- це ім’я змінної, що посилається на числовий список, а не на функцію.
Це відбувається тому, що Python першочергово шукає ім’я нової змінної list у локальному та глобальному просторах імен. Знайшовши там вашу змінна list, інтерпретатор Python припиняє пошук. Вбудований простір імен перевіряється в останню чергу, де, власне, і розміщується вбудована функція list().
Тепер ім’я list пов’язане з вашою змінною, хоча ви і використовуєте синтаксис вбудованої функції list().
Щоб повернути ситуацію у початковий стан, необхідно перезавантажити середовище інтерпретатора Python.
|
>>> list((4, 5, 6))
[4, 5, 6]
У глобальному просторі імен globals, наприклад, основній програмі присвоєно спеціальне ім’я __main__, обрамлене по обидва боки символами __. Такі імена заразервовані для використання всередині Python, тому їх використання для імен власних змінних неприпустимі. Це також стосується зарезервованих імен вбудованих функцій, модулів та інших об’єктів.
|
7.3. Імпорт модулів: інструкція import
Щоб використовувати модуль, потрібно завантажити код з модуля в простір імен вашої програми.
Щоб використовувати функції, які входять у модуль, необхідно його імпортувати (підключити) у програму за допомогою інcтрукції import.
|
Звичайна форма використання інструкції import:
import модуль
де модуль - це ім’я без розширення .py іншого файла Python.
Як тільки модуль імпортований, ви можете використовувати будь-яку функцію, яка входить до його складу.
Наприклад, щоб імпортувати модуль nameofmodule в простір імен, введіть наступну команду:
import nameofmoduleПри цьому у просторі імен створюється нова змінна nameofmodule, яка вказує на модуль.
7.4. Модуль random: правила імпорту
Модуль random надає функції для генерації псевдовипадкових чисел, букв, випадкового вибору елементів послідовності. Псевдовипадкові генератори цього модуля непридатні для криптографічного використання.
|
Поширені функції модуля random представлені у таблиці Додаток C: Модулі Python: random.
|
Проаналізуємо, як працює модуль random, який надає доступ, зокрема, до функції randint().
Введіть поданий нижче код у файл і збережіть з певним ім’ям:
import random
for i in range(5):
print(random.randint(1, 10))
Функція randint() повертає випадкове ціле число з діапазону між двома цілими числами, які передаються у функцію в якості аргументів.
|
Виконавши програму, ви повинні отримати п’ять випадкових цілих чисел з діапазону від 1 до 10 включно:
7
6
2
3
6
Оскільки функція randint() знаходиться у модулі random, то ім’я модуля повинне вказуватися у вигляді префікса (через крапку) перед іменем функції, щоб Python міг визначити, що дану функцію слід шукати у модулі random.
|
Для імпортування декількох модулів, використовують такий синтаксис:
import модуль1, модуль2, модуль3,...
або імпортують у такому вигляді:
import модуль1 import модуль2 import модуль3, модуль4
Всі інструкції import рекомендують розміщувати у верхній частині файла.
|
Тепер можна використовувати будь-які функції, які знаходяться у цих модулях.
Оператор import має альтернативну форму використання:
from модуль import функція1, функція2,...
В такому записі ми імпортуємо не увесь модуль з його усіма функціями, а лише конкретні функції з цього модуля. Таким чином у коді вже не треба використовувати префікс модуля перед іменем функції:
from random import randint, random
for i in range(5):
print(randint(1, 10))
print(random())8
7
3
6
10
0.12147106708747124 # результат виконання функції random()
Функція random() викликається без аргументів і генерує випадкове дійсне число від 0 до 1 не включаючи меж даного діапазону.
|
Ім’я функції, перед яким записане ім’я модуля, наприклад, random.randint(), використовувати безпечніше. Тому краще всього користуватися звичайною формою інструкції імпорту: import назва_модуля.
|
При імпортуванні можна використовувати символ *. Для нашого прикладу з модулем random()
from random import *цей запис можна прочитати так: з модуля random() імпортувати все.
| Будьте обережні при використанні форми імпортування «імпортувати все». Якщо деяке ім’я імпортованої функції визначається у двох модулях і ви імпортуєте обидва модуля, виникне конфлікт імен та ім’я з другого модуля замінить ім’я з першого модуля. Окрім того, з цією формою імпорту буде важче визначити, звідки взялися використовувані імена. |
Для скорочення назв імпортованих модулів (або функцій із модулів) можна також користуватися псевдонімами. Форма запису при такому використанні:
import модуль as псевдонім # псевдонім для модуля from модуль import функція as псевдонім # псевдонім для функції
Для прикладу, використання псевдоніма rn (назву обрано довільно) для модуля random, код для генерації випадкових цілих чисел зміниться таким чином:
import random as rn
for i in range(5):
print(rn.randint(1, 10))7.5. Модуль math: що всередині?
Модуль math стандартної бібліотеки Python містить багато математичних функцій.
Поширені функції і константи модуля math представлені у таблиці Додаток C: Модулі Python: math.
|
Щоб отримати до них доступ зі своїх програм, необхідно імпортувати бібліотеку math за допомогою команди
import mathВикористаємо інтерактивний режим інтерпретатора Python для дослідження даної бібліотеки. Ця бібліотека містить такі константи, як pi (число Пі) і e (експонента):
>>> import math
>>> math.pi
3.141592653589793
>>> math.e
2.718281828459045Розглянемо кілька корисних функцій бібліотеки math:
>>> math.fabs(-221.1) (1)
221.1
>>> math.floor(56.8) (2)
56
>>> math.ceil(38.3) (3)
39
>>> math.factorial(7) (4)
5040
>>> math.pow(4, 3) (5)
64.0
>>> math.sqrt(256) (6)
16.0
>>> math.radians(180) (7)
3.141592653589793
>>> math.degrees(math.pi) (8)
180.0-
Повертає абсолютне значення.
-
Округлення вниз.
-
Округлення вгору.
-
Обчислення факторіалу.
-
Піднесення числа до степеня.
-
Обчислення кореня квадратного з числа.
-
Перетворення значення в градусах у радіани.
-
Перетворення значення в радіанах у градусну міру.
Щоб дізнатися увесь список функцій імпортованого модуля math, використаємо функцію dir():
>>> import math
>>> dir(math)
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
>>>Рузультатом буде список атрибутів об’єкта math, більшість з яких є функціями.
Функція dir() повертає список атрибутів об’єкта, впорядкований за алфавітом. Ці атрибути є методами - функціями, пов’язаними з об’єктами.
|
Атрибути (або методи), що починаються і закінчуються на __, називаються спеціальними або магічними. Спеціальні методи визначають, що відбувається у внутрішній реалізації при виконанні операцій з об’єктами.
|
Якщо ви хочете викликати функцію factorial(), наприклад, для значення 3, зробити це не вдасться, тому що ім’я factorial не входить у простір імен - у просторі імен лише змінна math.
Однак, ви можете провести пошук атрибута factorial по змінній math з використанням оператора крапка (цей оператор переглядає атрибути об’єкта):
>>> math.factorial(3)
6Якщо ви захочете прочитати документацію по функції factorial(), скористайтеся функцією help().
Функція help() виводить документацію для методу, модуля, класу, функції тощо.
|
Якщо вас цікавить, що робить атрибут pow в модулі math, виконайте наступний код:
>>> import math
>>> help(math.pow)
Help on built-in function pow in module math:
pow(...)
pow(x, y)
Return x**y (x to the power of y).
>>>7.6. Стандартна бібліотека Python: короткий огляд модулів
Одна з основних переваг мови Python полягає в тому, що вона має велику добірку модулів у стандартній бібліотеці, які виконують багато корисних завдань і розташовуються окремо один від одного, щоб уникнути розростання ядра мови.
Коли ви збираєтеся писати код, часто спочатку варто перевірити, чи існує стандартний модуль, який вже робить те, що ви хочете.
Python надає авторитетну документацію для модулів стандартної бібліотеки.
|
7.6.1. Модулі string і inspect, функції capwords(), isinstance(), getmembers() і repr()
У модулі string визначена функція capwords(), яка переводить у верхній регістр першу букву кожного слова в рядку.
import string
s = 'It was nice talking to you! Thank you!'
print(s)
print(string.capwords(s))Резульатом роботи функції буде таким:
It was nice talking to you! Thank you!
It Was Nice Talking To You! Thank You!У модулі string визначено ряд констант, що мають відношення до таблиці ASCII і символьних послідовностей.
Текстові константи модуля string та їх значення можна переглянути у таблиці Додаток C: Модулі Python: string.
|
За допомогою коду
import inspect
import string
def is_str(value):
return isinstance(value, str)
for name, value in inspect.getmembers(string, is_str):
if name.startswith('_'):
continue
print('{0} = {1}'.format(name, repr(value)))можна отримати значення цих констант:
ascii_letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
digits = '0123456789'
hexdigits = '0123456789abcdefABCDEF'
octdigits = '01234567'
printable = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
punctuation = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
whitespace = ' \t\n\r\x0b\x0c'Модуль inspect, що був використаний у попередньому програмному коді, також входить у стандартну бібліотеку Python. Він надає корисні функції для отримання інформацію про живі об’єкти, такі як модулі, класи, методи, функції тощо.
Наприклад, модуль inspect може допомогти вам вивчити вміст класу, отримати початковий код методу, отримати і відформатувати список аргументів для функції, або отримати всю інформацію, необхідну для відображення детального трасування (інформація про хід виконання програми).
У нашому випадку ми використали з модуля inspect функцію getmembers() для отримання атрибутів модуля string.
Необов’язковий аргумент функції getmembers(), у вигляді окремо визначеної функції is_str(), дозволив отримати з модуля string лише текстові константи, минаючи функції, a використана функція startswith() відбирала спеціальні атрибути, які починаються і закінчуються на символ __, які в циклі також не бралися до уваги.
Для отримання друкованого представлення рядка із значенням константи використовувалася функція repr().
Функція isinstance() використовується для перевірки приналежності даних певному типу даних. Результатом виконання функції є значення True або False.
|
Функція repr() повертає представлення об’єкта у вигляді текстового рядка.
|
7.6.2. Модуль collections, функція OrderedDict()
Дуже часто при розв’язуванні задач необхідно порахувати кількість елементів послідовності.
В стандартній бібліотеці Python є функція Counter(), яка міститься у модулі collections, і справляється із цією задачею:
from collections import Counter
birds = ['stork', 'sparrow', 'woodpecker', 'owl', 'woodpecker', 'sparrow', 'sparrow']
birds_counter = Counter(birds)
print(birds_counter)
print(birds_counter['woodpecker'])
print(birds_counter['sparrow'])Результат роботи функції:
Counter({'sparrow': 3, 'woodpecker': 2, 'stork': 1, 'owl': 1})
2
3Визначимо ще один список ther_birds і порахуємо скільки птахів з нього зустрічається у списку birds:
from collections import Counter
birds = ['stork', 'sparrow', 'woodpecker', 'owl', 'woodpecker', 'sparrow', 'sparrow']
birds_counter = Counter(birds)
other_birds = ['flamingo', 'nightingale', 'stork', 'sparrow']
for bird in other_birds:
print('{0} : {1}'.format(bird, birds_counter[bird]))flamingo : 0
nightingale : 0
stork : 1
sparrow : 3Однією з поширених задач є впорядкування елементів послідовності. Розглянемо, як її розв’язувати на прикладі роботи зі словником.
Порядок вставки елементів у словник не можна передбачити (до версії Python 3.6). Розглянемо такий код:
regions = {
'sands': 'Sahara',
'mountains': 'Himalayas',
'rivers': 'Yangtze',
}
for region in regions:
print(region)Результатом виведення будуть ключі, але не обов’язково в порядку, в якому вони були додані у словник:
sands
rivers
mountains
Функція OrderedDict(), яка міститься у модулі collections, запам’ятовує порядок, в якому додавалися ключі, і повертає їх в тому ж порядку.
|
Спробуємо використати OrderedDict для послідовності кортежів виду «ключ: значення»:
from collections import OrderedDict
regions = OrderedDict([
('mountains', 'Himalayas'),
('sands', 'Sahara'),
('rivers', 'Yangtze')
])
for region in regions:
print(region)В даному прикладі порядок ключів словника при виведенні зберігається:
mountains
sands
rivers7.6.3. Модуль pprint, функція pprint()
Щоб виводити інформацію на екран використовують функцію print(). У випадку, коли результати виведення важко прочитати, можна використовувати pretty printer («гарний друк») - функцію pprint(), яка міститься у модулі pprint:
from collections import OrderedDict
from pprint import pprint
regions = OrderedDict([
('mountains', 'Himalayas'),
('sands', 'Sahara'),
('rivers', 'Yangtze')
])
print(regions)
pprint(regions)Порівняти результати використання функції print() і гарного принтера можна побачити у такому виведенні:
OrderedDict([('mountains', 'Himalayas'), ('sands', 'Sahara'), ('rivers', 'Yangtze')])
OrderedDict([('mountains', 'Himalayas'),
('sands', 'Sahara'),
('rivers', 'Yangtze')])7.6.4. Модуль decimal, функції Decimal(), getcontext()
Більшість десяткових дробів не можуть бути представлені точно з використанням типу float.
Щоб отримати точні результати, подібні до тих, з якими ми звикли працювати під час розрахунків вручну, нам потрібно щось, що підтримує швидку, правильно округлену, десяткову арифметику з рухомою крапкою. Модуль decimal робить саме це.
Після імпорту з модуля decimal функції Decimal(), можна створювати десяткові числа з цілих чисел, рядків, чисел з рухомою крапкою чи кортежів.
Коли десяткове число будується з цілого числа або числа з рухомою крапкою, існує точне перетворення значення цього числа. Давайте проаналізуємо наведені нижче приклади
from decimal import Decimal
print(Decimal(234)) (1)
print(Decimal(0.08)) (2)
print(Decimal('0.08')) (3)
print(Decimal((0, (6, 2, 5, 1), -3))) (4)
print(Decimal((1, (6, 2, 5, 1), -1))) (5)та результати виконання:
234 (1)
0.08000000000000000166533453693773481063544750213623046875 (2)
0.08 (3)
6.251 (4)
-625.1 (5)-
Точне представлення цілого числа у десятковій формі.
-
Наближене представлення числа з рухомою крапкою у десятковій формі. Кількість значущих цифр не може бути точно виражена з використанням апаратного представлення чисел з рухомою крапкою.
-
Точне представлення числа з рухомою крапкою у десятковій формі. Числа з рухомою крапкою можуть попередньо перетворюватися в рядок, перш ніж будуть оброблені
Decimal, тим самим виконуваний код явно встановить кількість значущих цифр. -
Створення дробового десяткового числа на основі кортежу
(6, 2, 5, 1),0- додатне число,-3- кількість знаків після десяткової крапки. -
Створення дробового десяткового числа на основі кортежу
(6, 2, 5, 1),1- від’ємне число,-1- кількість знаків після десяткової крапки.
Функція Decimal() дозволяє виконувати арифметичні операції.
from decimal import Decimal
print(Decimal('0.09') + Decimal('0.11'))
print(Decimal(0.09) + Decimal(0.11))
print(Decimal('0.09') - Decimal('0.11'))Результати арифметичних дій:
0.20
0.1999999999999999972244424384
-0.02До цих пір у всіх прикладах використовувалася поведінка модуля decimal за замовчуванням. Існує можливість змінити цю поведінку, використовуючи контекст для налаштування таких параметрів, як підтримувана точність, спосіб округлення і обробка помилок. Контекст можна змінити за допомогою функції getcontext().
Атрибут prec контексту керує точністю обчислення. На відміну від апаратної двійкової рухомої крапки, модуль decimal має змінну точність обчислення (за замовчуванням до 28 місць).
from decimal import Decimal, getcontext
d = Decimal('0.123456')
for i in range (1, 7):
getcontext().prec = i
print(i, ':', d, d * 1)Точність обчислення атрибут prec підтримує для нових значень, що створюються в результаті виконання математичних операцій:
1 : 0.123456 0.1
2 : 0.123456 0.12
3 : 0.123456 0.123
4 : 0.123456 0.1235
5 : 0.123456 0.12346
6 : 0.123456 0.123456Модуль decimal включає поняття значущих місць. Це означає, що протяжність нуля зберігається для позначення значущості (це звичайне подання для фінансових застосунків):
from decimal import Decimal, getcontext
print(Decimal(1) / Decimal(13))
print(Decimal(1.30) + Decimal(1.20))
print(Decimal(1.30) * Decimal(1.20))
print(Decimal(1.3) * Decimal(1.2))
getcontext().prec = 4
print(Decimal(1.30) + Decimal(1.20))
print(Decimal('1.30') * Decimal('1.20'))
print(Decimal('1.3') * Decimal('1.2'))
print(Decimal('1') / Decimal('13'))
print(Decimal(1) / Decimal(9))Зверніть увагу не лише на точності обчислень, але і на зберігання значущих нулів у результатах виконання вищенаведеного коду:
0.07692307692307692307692307692
2.500000000000000000000000000
1.559999999999999995559107901
1.559999999999999995559107901
2.500
1.560
1.56
0.07692
0.1111У модулі decimal присутні опції, які керують округленням значень в межах заданої точності обчислень. Наведемо приклади деяких таких опцій:
-
ROUND_DOWN. Округлення в напрямку нуля. -
ROUND_HALF_DOWN. Округлення в напрямку від нуля, якщо остання цифра рівна або більша5, інакше - округлення в напрямку до нуля. -
ROUND_HALF_EVEN. АналогічнаROUND_HALF_DOWN, за винятком того, що у випадках, коли остання цифра дорівнює5, перевіряється передостання цифра. Якщо передостання цифра парна, округлення результату відбувається вниз, непарна - округлення вгору. -
ROUND_HALF_UP. АналогічнаROUND_HALF_DOWN, за винятком того, що в тих випадках, коли остання цифра дорівнює5, значення округлюється у напрямку від нуля. -
ROUND_UP. Округлення в напрямку від нуля.
Приклади використання округлення, наведені нижче,
import decimal
from decimal import Decimal, getcontext
getcontext().prec = 5
getcontext().rounding = decimal.ROUND_DOWN
print(Decimal('0.52631558947368') * Decimal('1'))
getcontext().prec = 5
getcontext().rounding = decimal.ROUND_HALF_DOWN
print(Decimal('0.52631558947368') * Decimal('1'))
getcontext().prec = 6
getcontext().rounding = decimal.ROUND_HALF_EVEN
print(Decimal('0.52631558947368') * Decimal('1'))
getcontext().prec = 7
getcontext().rounding = decimal.ROUND_HALF_UP
print(Decimal('0.52631558947368') * Decimal('1'))
getcontext().prec = 8
getcontext().rounding = decimal.ROUND_UP
print(Decimal('0.52631558947368') * Decimal('1'))повернуть наступні результати:
0.52631
0.52632
0.526316
0.5263156
0.526315597.7. Модуль __name__
У файлах Python часто розміщують таку конструкцію:
...
if __name__ == '__main__':
... # блок кодуДавайте розберемось як ця інструкція працює. Для прикладу, визначимо функцію у файлі users.py:
def greet_users(names):
"""Виведення привітання для кожного користувача у списку."""
for name in names:
message = "Hello, " + name.title() + "!"
print(message)
usernames = ['alex', 'jack', 'anna']
greet_users(usernames)Дана функція отримує список імен користувачів і формує вітальні вітання для кожного із них:
Hello, Alex!
Hello, Jack!
Hello, Anna!Файл users.py вважатимемо модулем, який містить єдину функцію. Створимо ще один файл main_file.py і помістимо у нього такий код:
from users import greet_users (1)
print('This code is executed!') (2)
if __name__ == '__main__': (3)
print('This code is executed because the main_file.py is not being imported!')-
У файл
main_file.pyвиконується імпорт функціїgreet_users()із модуля-файлаusers.py. -
Цей рядок коду виконується як при запуску файла
main_file.py, так і у випадку, коли файлmain_file.pyімпортуємо у інший файлanother_file.py(у даному випадку файлmain_file.pyстає модулем) таким чином:
import main_file-
Умова
ifі відповідний блок коду виконуються лише у випадку, коли ми запукаємо на виконання сам файлmain_file.py.
Результати окремого виконання кожного із файлів у терміналі Windows будуть такими:
C:\Python36>python users.py (1)
Hello, Alex!
Hello, Jack!
Hello, Anna!
C:\Python36>python main_file.py (2)
Hello, Alex!
Hello, Jack!
Hello, Anna!
This code is executed!
This code is executed because the main_file.py is not being imported!
C:\Python36>python another_file.py (3)
Hello, Alex!
Hello, Jack!
Hello, Anna!
This code is executed!-
Запуск файла
users.pyіз функцією, яка повертає результи своєї роботи. -
Запуск файла
main_file.py, у який імпортували функцію з файлаusers.py. Конструкціяif __name__ == '__main__':повертаєTrueі блок коду виконується. -
Запуск файла
another_file.py, у який імпортували код файлаmain_file.py. Конструкціяif __name__ == '__main__':повертаєFalseі блок коду не виконується.
Python визначає змінну рівня модуля __name__ для будь-якого імпортованого модуля або будь-якого виконуваного файла.
Використання змінної __name__ можна продемонструвати на простому прикладі. Створіть файл some_module.py з наступним кодом:
print('The __name__ is: {0}'.format(__name__))Коли файл імпортується як модуль:
>>> import some_module
The __name__ is: some_moduleзначення змінної __name__ буде some_module і дорівнюватиме імені файла. Тобто, якщо перевірка
...
if __name__ == '__main__':
... # блок кодубула імпортована в інтерактивний сеанс або інший модуль, то значення змінної __name__ буде відповідати імені файла, який імпортується, умова не буде виконуватися і блок коду не буде виконуватися відповідно.
Коли файл виконується як сценарій
C:\Python36>python some_module.py
The __name__ is: __main__змінна __name__ матиме значення __main__, перевірка умови
...
if __name__ == '__main__':
... # блок кодупройде успішно і, відповідно, виконається блок коду.
Одна з поширених ідіом у світі Python - розміщення подібних перевірок в кінці модуля, який також може служити сценарієм. Така перевірка визначає, виконується файл або імпортується.
Ідіома Python (Python Trick) - короткий фрагмент початкового коду на Python, який використовується як інструмент навчання. Ідіома Python навчає окремій властивості мови Python шляхом простої ілюстрації або служить в якості мотивуючого прикладу, який дає можливість копнути глибше і розвинути інтуїтивне розуміння.
|
7.8. Аргументи командного рядка
При запуску програми на Python, яка збережена у файлі з певним ім’ям, у термінальму вікні (вікні командного рядка) необхідно ввести python і ім’я цього файла.
Створимо файл test.py, який міститиме наступні рядки:
import sys
print('Program arguments:', sys.argv)Тепер, запустимо цей файл у термінальному вікні, наприклад, Windows, перед тим перейшовши у каталог, де файл був збережений:
C:\Python36>python test.py
Program arguments: ['test.py']
C:\Python36>python test.py one two three
Program arguments: ['test.py', 'one', 'two', 'three']Змінна argv з модуля sys містить список аргументів командного рядка. Значення argv[0] - ім’я файла, який запускається (або повний шлях до нього). argv[1], argv[2] - це інші аргументи командного рядка.
В нашому випадку argv[0] має значення test.py, argv[1] має значення one, argv[2] має значення two і argv[3] має значення three.
7.9. Пакети
Модулі Python ораганізовують в групи файлів, які називаються пакетами.
Якщо ви розумієте, як працюють модулі, розібратися з пакетами має бути нескладно, тому що пакет являє собою каталог з програмним кодом і, можливо, кількома підкаталогами.
Пакет - це каталог, який містить файл __init__.py, файли модулів та інші підпакети.
|
Каталог пакета має обов’язково містити файл __init__.py, тому що так він може бути розпізнаний як пакет. Це убезпечує випадковове імпортування каталогів, що містять посторонній код Python, в якості пакетів.
|
Пакети є природним розширенням концепції модуля; вони призначені для дуже великих проектів. За аналогією з тим, як модулі групують взаємопов’язані змінні, функції і класи, пакети групують взаємопов’язані модулі.
7.9.1. Створення власних пакетів
Створимо власний пакет на прикладі такої задачі. Наприклад, нам потрібно дізнатися різні типи прогнозів погоди: на наступний день і на наступний тиждень.
Створимо каталог boxes, а у ньому каталог sources (він і буде пакетом), який буде містити два модуля: файли daily.py і weekly.py. Кожний з них міститиме функцію forecast(). Версія файла погоди на кожний день повертатиме рядок, а версія файла погоди на кожен тиждень повертатиме список із 7 рядків.
Відповідно до стилю написання коду Python, імена каталогів пакета повинні бути короткими і записаними в нижньому регістрі, без використання символа підкреслення.
|
Розглянемо основну програму і два модуля в операційній системі Windows.
Основна програма буде міститися у файлі по шляху boxes\weather.py:
from sources import daily, weekly
print("Daily forecast:", daily.forecast())
print("Weekly forecast:")
for number, outlook in enumerate(weekly.forecast(), 1):
print(number, outlook)
У прикладі вище, функція enumerate() розбиває список на частини і відправляє кожний елемент списку в цикл for, додаючи до кожного елемента число - порядковий номер, починаючи з 1.
|
Модуль 1 буде знаходитися у файлі по такому шляху: boxes\sources\daily.py:
def forecast():
'''Fake daily forecast'''
return 'like yesterday'Модуль 2 буде знаходитися у файлі по такому шляху: boxes\sources\weekly.py:
def forecast():
"""Fake weekly forecast"""
return ['mist', 'strong winds', 'sleet', 'freezing rain', 'rain', 'fog', 'drizzle']
У модулях 1 і 2 присутні коментарі '''fake daily forecast''' і """Fake weekly forecast""" відповідно, створені за допомогою різних типів лапок. Інтерпретатор ігнорує рядки з цими коментарями при виконанні програми.
|
В каталозі sources необхідно розмістити файл __init__.py. Цей файл може бути порожнім, але він потрібний для того, щоб Python міг вважати каталог, який його містить, пакетом.
Виконання основної програми weather.py дасть такий результат:
Daily forecast: like yesterday
Weekly forecast:
1 mist
2 strong winds
3 sleet
4 freezing rain
5 rain
6 fog
7 drizzle7.9.2. Менеджер пакетів pip
Стандартна бібліотека Python дозволяє охопити широкий спектр задач, але з часом неминуче виникне ситуація, в якій вам знадобиться функціональність, відсутня в стандартній бібліотеці.
Щоб знайти потрібний пакет чи модуль Python, можна скористатися пошуковою системою і знайти в Інтернеті необхідний пакет чи модуль у вигляді виконуваного файла для вашої операційної системи Windows чи пакета для вашого дистрибутива Linux.
У цьому випадку, програма встановлення або менеджер пакетів беруть на себе всі подробиці коректного додавання модуля в систему зі всіма залежностями.
Якщо вам знадобиться сторонній модуль, який не був заздалегідь упакований для вашої платформи, можна використати менеджер пакетів pip .
Пакет pip - це система управління пакетами і найпопулярніший спосіб встановити сторонні пакети Python.
|
Менеджер пакетів pip намагається знайти модуль в каталозі Python Package Index , завантажує його з усіма залежностями і бере на себе встановлення.
Починаючи з версії мови Python 3.4, pip є стандартною частиною Python.
|
Відкрийте термінальне вікно і введіть команду:
pip helpНа екрані з’явиться інформація про команди pip та їх використання. Наведемо приклади використання деяких з них у термінальному вікні.
Для оновлення самого pip використовують команду:
pip install --upgrade pipДля перегляду списку установлених пакетів використовують команду:
pip listДля установки пакета використовують команду:
pip install назва_пакетаДля видалення пакета використовують команду:
pip uninstall назва_пакетаДля оновлення пакета використовують команду:
pip install --upgrade назва_пакета7.10. Віртуальні середовища
Деякі застосунки, які створюються на Python, іноді, вимагають конкретні версії бібліотек, для інших така вимога може бути не суттєвою. Це означає, що неможливо для однієї установленої копії інтерпретатора Python задовольнити вимоги кожної програми.
Рішення цієї проблеми полягає у створенні віртуального середовища, автономного дерева каталогів, що містить установку Python для певної версії Python, а також ряд додаткових пакетів.
Так як все оточення Python міститься у віртуальному середовищі, встановлені в ньому бібліотеки і модулі не будуть конфліктувати з бібліотеками і модулями основної системи або інших віртуальних середовищ, що дозволяє різним програмам використовувати різні версії Python і його пакетів.
Розглянемо створення і використання віртуального середовища.
-
Створення віртуального середовища.
Модуль, який використовується для створення та управління віртуальними середовищами, називається venv. venv, зазвичай, встановлює найновішу версію Python у віртуальне середовище, яка у вас зараз встановлена.
Якщо у вашій системі є кілька версій Python, ви можете вибрати певну версію Python, наприклад, python3.6.
Версія Python, яку ви використовуєте для створення віртуального середовища, стане версією Python за замовчуванням для цього середовища, тому ви можете використовувати команду python замість python3 або python3.6.
|
Отже, відкрийте термінальне вікно і введіть команду:
python -m venv tutorial-envДана команда створить каталог tutorial-env, якщо він не існує, а також створить каталоги всередині нього, що містять копію інтерпретатора Python, pip, стандартну бібліотеку та різні допоміжні файли.
-
Після створення віртуального середовища його треба активувати.
У системі Windows виконайте:
tutorial-env\Scripts\activate.batУ Linux Ubuntu виконайте:
source tutorial-env/bin/activateПроаналізуємо увесь процес створення віртуального середовища і основи роботи в ньому у системі Windows.
C:\Users\user>python -m venv tutorial-env (1)
C:\Users\user>tutorial-env\Scripts\activate.bat (2)
(tutorial-env) C:\Users\user>python -V (3)
Python 3.6.5
(tutorial-env) C:\Users\user>python (4)
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> name = 'tutorial-env'
>>> print('I am a virtual environment', name)
I am a virtual environment tutorial-env
>>>exit() (5)
(tutorial-env) C:\Users\user>python -m pip install --upgrade pip (6)
...
Successfully installed pip-19.1.1
(tutorial-env) C:\Users\user>pip install requests==2.19.0 (7)
...
Successfully installed certifi-2019.6.16 chardet-3.0.4 idna-2.7 requests-2.19.0 urllib3-1.23
(tutorial-env) C:\Users\user>deactivate (8)
C:\Users\user>-
Створення віртуального середовища
tutorial-env. -
Активація віртуального середовища
tutorial-env. -
Отримання інформації про версію інтерпретатора
Pythonу віртуальному середовищі. -
Запуск інтерактивного режиму інтерпретатора
Pythonу віртуальному середовищі і виконання деяких команд. -
Вихід з інтерактивного режиму інтерпретатора
Pythonу віртуальному середовищі. -
Оновлення пакета
pipдо останньої версії у віртуальному середовищі (не впливає на пакетиpipсистемної копіїPythonта інших віртуальних середовищ, якщо такі є). -
Встановлення пакета
requestsконкретної версії2.19.0лише у віртуальне середовищеtutorial-env. -
Вихід з віртуального середовища
tutorial-envза допомогою командиdeactivate.
7.11. Завдання
7.11.1. Контрольні запитання
-
Що робить інструкція
import? -
Яка різниця між модулем і пакетом?
-
Якщо у вас є функція
myfunc(), яка міститься у модуліaddfunc, то як би ви її викликали після імпортування цього модуля? -
Для чого використовується модуль
__name__? -
Як отримати доступ у програмі до аргументів командного рядка?
-
Навіщо використовувати віртуальні середовища?
7.11.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Створіть файл, який називається
city.py. У ньому оголосіть функціюlibrary_services(), яка виводить на екран рядокInternet access is open 24 hours.. Використайте інтерактивний інтерпретатор, щоб імпортувати модульcity.pyі викликати його функціюlibrary_services(). -
У інтерактивному інтерпретаторі імпортуйте модуль
city.pyз ім’ямctі викличте його функціюlibrary_services(). -
Залишаючись у інтерпретаторі, імпортуйте безпосередньо функцію
library_services()з модуляcity.pyі викличте її. -
Імпортуйте функцію
library_services()з ім’ямinfoі викличте її.
7.11.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Файл
models.pyмістить програмний код, поданий нижче, що імітує друкування 3D-моделей різних об’єктів. Перенесіть функціїprint_models()іshow_completed_models()у окремий файл з ім’ямprinting_functions.py. Виконайте імпорт цих функцій у файлmodels.py, змінивши файл так, щоб у ньому імпортовані функції можна було використовувати.
def print_models(unprinted_designs, completed_models):
"""
Імітує друк 3D-моделей, доки список не стане порожнім.
Кожна модель після друку переміщується у completed_models.
"""
while unprinted_designs:
current_design = unprinted_designs.pop()
# Імітація друку моделі на 3D-принтері.
print("Printing model: " + current_design)
completed_models.append(current_design)
def show_completed_models(completed_models):
"""Виводить інформацію про усі надруковані моделі."""
print("\nThe following models have been printed:")
for completed_model in completed_models:
print(completed_model)
unprinted_designs = ['iphone case', 'robot pendant', 'dodecahedron']
completed_models = []
print_models(unprinted_designs, completed_models)
show_completed_models(completed_models)-
Візьміть за основу одну з написаних вами програм з однією функцією. Збережіть цю функцію в окремому файлі. Імпортуйте функцію у файл основної програми і викличте функцію будь-яким із таких способів:
імпорт ім'я_модуля from ім'я_модуля import ім'я_функції from ім'я_модуля import ім'я_функції as псевдонім import ім'я_модуля as псевдонім
8. Файли
Активна програма працює з даними, які зберігаються в оперативній пам’яті (Random Access Memory). RAM - дуже швидка пам’ять, але вимагає постійного живлення; якщо живлення зникає, то всі дані, які в ній зберігаються, будуть втрачені. Різноманітні накопичувачі (жорсткі диски, твердотільні диски, флеш-диски тощо) можуть зберігати дані навіть після того, як вимкнуть живлення.
Звичайний файл - найпростіший приклад сховища даних. Дані зчитуються з файла в пам’ять і записуються з пам’яті у файл.
Серед типів файлів можна виділити дві групи: прості текстові файли і бінарні файли.
Прості текстові файли - містять лише базові текстові символи, без інформації про шрифт, розмір і колір тексту тощо. Прикладом таких файлів є файли з розширенням .txt або файли Python з розширенням .py.
|
Бінарні (двійкові) файли - це файли документів, які створені текстовими процесорами, PDF-файли, файли зображень, елетронних таблиць і, взагалі, виконуваних програм.
|
Приклад бінарного файла (файл інтерпретатора Python), відкритого у програмі Блокнот:
8.1. Відкриття текстового файла
Перед тим як щось записати у файл або зчитати з нього, спочатку необхідно відкрити файл:
fileobj = open(filename, mode)
-
fileobj- об’єкт файла, який повертається функцієюopen() -
filename- рядок з назвою файла або шлях до файла -
mode- рядок, який вказує на тип файла і дії, які можна виконувати над файлом
Перша літера рядка mode вказує на операцію з файлом:
-
r- означає читання з файла -
w- означає запис в існуючий файл (якщо файла не існує, він буде створений) -
x- означає запис у новий файл, тобто, якщо файла не існує (він буде створений) -
a- означає додавання в кінець файла, якщо файл існує
Друга літера рядка mode вказує на тип файла:
-
t(або нічого) - означає, що файл текстовий -
b- означає, що файл бінарний
Після відкриття файла, виконують читання даних з файла або запис даних у файл.
Потім необхідно файл закрити функцією close():
fileobj.close()
Закриття об’єкта fileobj звільняє системні ресурси, дозволяє виконувати читання або запис у файл з іншого коду і, загалом, підвищує надійність програми.
|
8.2. Запис даних у текстові файли
Використаємо як джерело даних фрагмент вірша Тараса Шевченка англійською мовою, що міститься у змінній poem і запишимо цей вірш у текстовий файл result.txt:
poem = '''The mighty Dnieper roars and bellows,
The wind in anger howls and raves,
Down to the ground it bends the willows,
And mountain-high lifts up the waves.'''
frecord = open('result.txt', 'wt')
a = frecord.write(poem)
frecord.close()
print(a)Функція write(), значення якої було присвоєне змінній a, повертає число записних у файл байтів
151але не додає ніяких інших символів у файл, як це робить функція print(), яка також дозволяє записувати у файл:
frecord = open('result.txt', 'wt')
print(poem, file=frecord)
frecord.close()Для запису у файл можна використовувати обидві функції. Варто лише пам’ятати про два аргументи функції print():
-
sep- розділювач (за замовчуванням це пропуск' ') -
end- символ кінця файла (за замовчуванням це символ нового рядка\n)
Для того щоб функція print() працювала так само, як функція write(), змінений код виглядатиме так:
frecord = open('result.txt', 'wt')
print(poem, file=frecord, sep='', end='')
frecord.close()Вміст файла result.txt буде таким:
The mighty Dnieper roars and bellows,
The wind in anger howls and raves,
Down to the ground it bends the willows,
And mountain-high lifts up the waves.Перевіримо, чи «врятує» режим x файл result.txt
frecord = open('result.txt', 'xt')від його перезаписування?
Traceback (most recent call last):
File "C:\Python34\test.py", line 1007, in <module>
frecord = open('result.txt', 'xt')
FileExistsError: [Errno 17] File exists: 'result.txt'Перезаписати не вдалося, оскільки у режимі x запис у файл здійснюється лише у новий файл. Виникла помилка і згенерувався виняток. У такому випадку корисно використовувати обробник винятку:
try:
frecord = open('result.txt', 'xt')
frecord.write(poem)
except FileExistsError:
print('result.txt already exists!')Результатом використання обробника винятку буде повідомлення про те, що файл з таким ім’ям вже існує і записати у нього інформацію неможливо:
result.txt already exists!8.3. Зчитування даних з текстових файлів
Щоб прочитати дані з файла, можна використовувати такі функції: read(), readline(), readlines().
|
Щоб прочитати увесь вміст файла за один раз, використаємо функцію read().
Використання функції read() для зчитування даних з великих за обсягом файлів потребує достатнього обсягу оперативної пам’яті.
|
freading = open('result.txt', 'rt' )
poem = freading.read()
freading.close()
print(poem) (1)
print(len(poem)) (2)-
Виведення усього вмісту файла за один раз.
-
Виведення кількості байтів, зчитаних з файла.
Результат зчитування даних з файла буде наступним:
The mighty Dnieper roars and bellows,
The wind in anger howls and raves,
Down to the ground it bends the willows,
And mountain-high lifts up the waves.
151Можна вказати максимальну кількість символів, які зчитуються з файла за один раз. Для прикладу, будемо зчитувати по 60 символів за раз і приєднувати кожний фрагмент до рядка poem, щоб відтворити увесь вміст файла:
poem = ''
freading = open('result.txt', 'rt' )
chunk = 60
while True:
fragment = freading.read(chunk)
if not fragment:
break
poem += fragment
print(len(fragment))
freading.close()Після того як зчитали увесь файл, подальші виклики функції read() будуть повертати порожній рядок (''). Це буде оцінено як False в перевірці if not fragment і дозволить вийти з нескінченного циклу while True.
Можна також зчитувати файл по одному рядку за раз за допомогою функції readline(). У наступному прикладі будемо приєднувати кожен рядок до рядка poem, щоб відтворити увесь вміст файла:
poem = ''
freading = open('result.txt', 'rt' )
while True:
line = freading.readline()
if not line:
break
poem += line
freading.close()
print(poem)Коли весь файл буде зчитаний, функція readline() (як і функція read()) поверне порожній рядок, що буде вважатися False і відбудеться вихід з циклу.
Найпростіший спосіб прочитати текстовий файл - використовувати цикл. Він буде повертати по одному рядку за раз. Цей приклад схожий на попередній, але коду у ньому менше:
poem = ''
freading = open('result.txt', 'rt' )
for line in freading:
poem += line
freading.close()
print(poem)А функція readlines() повертає список зчитаних рядків:
freading = open('result.txt', 'rt' )
lines = freading.readlines()
freading.close()
print(len(lines), 'lines read')
print(lines)
for line in lines:
print(line.rstrip())Функція rstrip() видаляє символи нового рядка \n у кожному із виведених рядків, окрім останнього, в якому цей символ відсутній.
4 lines read
['The mighty Dnieper roars and bellows,\n', 'The wind in anger howls and raves,\n', 'Down to the ground it bends the willows,\n', 'And mountain-high lifts up the waves.']
The mighty Dnieper roars and bellows,
The wind in anger howls and raves,
Down to the ground it bends the willows,
And mountain-high lifts up the waves.8.4. Інструкція with
| Файл повинен бути закритий після того, як усі операції з ним будуть завершені. |
У Python присутні менеджери контексту, що використовуються для очищення об’єктів (звільнення ресурсів), на зразок відкритих файлів. Для роботи з файлами менеджер контексту має таку конструкцію:
with вираз as змінна: блок коду
Наприклад:
with open('result.txt', 'wt') as freading:
freading.write(poem)Після того як блок коду, розташований у менеджері контексту (у цьому випадку один рядок freading.write(poem)), завершиться (або звичайним способом, або шляхом генерації винятку), файл буде закритий автоматично.
Використовуйте конструкцію with для читання та запису файлів і вам не доведеться турбуватися про їх закриття.
|
8.5. Бінарні файли
Якщо у синтаксис функції для відкривання файлів open(filename, mode) включити символ 'b' у рядок mode, файл буде відкритий в бінарному режимі. В цьому випадку, замість читання і запису рядків, операції будуть виконуватися з байтами .
Щоб працювати з бінарними файлами, використаємо функцію bytes().
Функція bytes() повертає незмінний об’єкт байтів, ініціалізований із заданим розміром і даними.
|
За допомогою функції range() згенеруємо 256 байтових значень від 0 до 255 і відкриємо файл bfile у бінарному режимі для запису цих згенерованих даних:
bdata = bytes(range(0, 256))
frecord = open('bfile', 'wb')
frecord.write(bdata)
frecord.close()Як і у випадку з текстом, бінарні дані можна записувати (зчитувати) фрагментами. Запишемо у файл згенеровані бінарні дані фрагментами не більшими за 100 байт:
bdata = bytes(range(0, 256))
frecord = open('bfile', 'wb')
size = len(bdata)
offset = 0
chunk = 100
while True:
if offset > size:
break
result = frecord.write(bdata[offset:offset+chunk])
print(result)
offset += chunk
frecord.close()Рядок print(result) буде візуалізувати цей процес запису - на екран буде виводитися кількість вже записаних байтів:
100
100
56Щоб прочитати бінарний файл - треба відкрити його у бінарному режимі rb:
freading = open('bfile', 'rb')
bdata = freading.read()
freading.close()При виконанні операцій з бінарними файлами для відслідковування місцезнаходження у файлі конкретних байтів використовують функції tell() і seek().
Для прикладу скористаємося 256-байтним бінарним файлом bfile, який був створений раніше:
freading = open('bfile', 'rb')
print(freading.tell()) (1)
print(freading.seek(25)) (2)-
Функція
tell()повертає ціле число - поточне розташування від початку файла, виміряне у байтах. -
Функцію
seek()використовують для того, щоб зміститися до конкретного байту у файлі.
0 # знаходимось на нульовому байті у файлі
25 # йдемо до 25-го байта у файліВи також можете викликати функцію seek(), передавши їй другий аргумент:
seek(offset, origin)або звичайною мовою
seek(скільки, звідки)В результаті:
-
Якщо значення
originдорівнює0(за замовчуванням), зміститися наoffsetбайтів з початку файла. -
Якщо значення
originдорівнює1, зміститися наoffsetбайтів з поточної позиції праворуч. -
Якщо значення
originдорівнює2, зміститися наoffsetбайтів з кінця файла ліворуч.
Завдяки цьому, ми можемо перейти до будь-якого байту у файлі. Об’єднаємо усі прийоми, написавши програму з коментарями для кращого розуміння процесу:
freading = open('bfile', 'rb') # відкриваємо файл (містить 256 байтових значень) у бінарному режимі
freading.seek(251, 0) # переходимо у позицію за 5 байтів до кінця файла
print(freading.tell()) # виводимо на екран поточну позицію, рахуючи від початку файла
freading.seek(3, 1) # переходимо на 3 байти праворуч з поточної позиції
print(freading.tell()) # виводимо на екран поточну позицію, рахуючи від початку файла
bdata = freading.read() # зчитуємо усі байти до кінця файла (їх усього 2)
print(bdata) # виводимо на екран зчитані даніРезультатами виведення трьох функцій print() у тому ж порядку, як вони записані, будуть такі рядки:
251
254
b'\xfe\xff'
Функції tell() і seek() найбільш корисні при роботі з бінарними файлами. Їх можна використовувати і для роботи з текстовими файлами, проте, якщо файл містить не тільки символи формату ASCII (що займають по одному байту у пам’яті), буде важко визначити місцеположення символу, оскільки воно буде залежати від системи кодування тексту. Наприклад, кодування UTF-8 використовує різну кількість байтів для різних символів.
|
8.6. Структуровані текстові файли
Для простих текстових файлів єдиним рівнем організації є рядок. Але іноді може знадобитися більш структурований файл, у якому необхідно зберегти дані своєї програми для подальшого використання або відправити їх іншій програмі.
Існує ряд популярних форматів, які можна розрізнити за такими ознаками.
8.6.1. CSV
Файли цього формату часто використовуються у якості формату обміну даними для електронних таблиць і баз даних.
Ви можете зчитати CSV-файл по одному рядку за раз, розділяючи кожен рядок на поля, розставляючи коми (або альтернативні розділювачі) і додаючи результат в структуру даних на зразок списку або словника. Але кращим варіантом буде використовувати стандартний модуль csv.
Для початку, поглянемо, як зчитувати і записувати список рядків, кожен з яких містить список стовпців:
import csv
programmers = [
['Python', 'Guido van Rossum'],
['Scala', 'Martin Odersky'],
['PHP', 'Rasmus Lerdorf'],
['Ruby', 'Yukihiro Matsumoto'],
['C', 'Dennis Ritchie']
]
with open('programmers.csv', 'wt', newline='') as frecord: # менеджер контексту містить вказівку newline=''
csvrecord = csv.writer(frecord)
csvrecord.writerows(programmers)Цей код створює файл з п’ятьма записами:
Python,Guido van Rossum
Scala,Martin Odersky
PHP,Rasmus Lerdorf
Ruby,Yukihiro Matsumoto
C,Dennis Ritchie
Якщо вказівка newline='' не використовується, нові рядки, вбудовані всередині полів з лапками, не будуть інтерпретовані правильно, а на платформах, які використовують позначення \r\n для закінченння рядків, буде додатково додана послідовність \r. Це зумовлено тим, що модуль csv виконує власну (універсальну) обробку нового рядка.
|
Тепер спробуємо зчитати ці записи:
import csv
with open('programmers.csv', 'rt') as freading:
creading = csv.reader(freading)
programmers = [row for row in creading] # тут використовується включення списку
print(programmers)Виконавши попередній код, отримаємо список списків:
[['Python', 'Guido van Rossum'], ['Scala', 'Martin Odersky'], ['PHP', 'Rasmus Lerdorf'], ['Ruby', 'Yukihiro Matsumoto'], ['C', 'Dennis Ritchie']]
Використовуючи функції reader() і writer() із стандартними опціями, ми отримуємо стовпці, які розділені комами, і рядки, розділені символами нового рядка.
|
Дані можуть мати формат списку словників, а не списку списків. Знову зчитаємо файл programmers.csv, цього разу використовуючи нову функцію DictReader() і вказуючи імена стовпців:
import csv
with open('programmers.csv', 'rt') as freading:
creading = csv.DictReader(freading, fieldnames=['language', 'developer'])
programmers = [row for row in creading]
print(programmers)Результатом буде список словників:
[{'developer': 'Guido van Rossum', 'language': 'Python'}, {'developer': 'Martin Odersky', 'language': 'Scala'}, {'developer': 'Rasmus Lerdorf', 'language': 'PHP'}, {'developer': 'Yukihiro Matsumoto', 'language': 'Ruby'}, {'developer': 'Dennis Ritchie', 'language': 'C'}]Перепишемо CSV-файл за допомогою функції DictWriter(). Також зробимо виклик функції writeheader(), щоб записати початковий рядок, що містить імена стовпців, у CSV-файл:
import csv
programmers = [
{'language': 'Python', 'developer': 'Guido van Rossum'},
{'language': 'Scala', 'developer': 'Martin Odersky'},
{'language': 'PHP', 'developer': 'Rasmus Lerdorf'},
{'language': 'Ruby', 'developer': 'Yukihiro Matsumoto'},
{'language': 'C', 'developer': 'Dennis Ritchie'},
]
with open('programmers.csv', 'wt', newline='') as frecord:
crecord = csv.DictWriter(frecord, ['language', 'developer'])
crecord.writeheader()
crecord.writerows(programmers)Цей код створює файл programmers.csv з рядком заголовку:
language,developer
Python,Guido van Rossum
Scala,Martin Odersky
PHP,Rasmus Lerdorf
Ruby,Yukihiro Matsumoto
C,Dennis Ritchie
Тепер зчитаємо файл programmers.csv, не враховуючи аргумент fieldnames у виклику DictReader()
import csv
import pprint
with open('programmers.csv', 'rt') as freading:
creading = csv.DictReader(freading)
programmers = [{'language': row['language'], 'developer': row['developer']} for row in creading]
pprint.pprint(programmers)використовуючи значення першого рядка файла (language, developer) як імена стовпців і відповідні ключі словників:
[{'developer': 'Guido van Rossum', 'language': 'Python'},
{'developer': 'Martin Odersky', 'language': 'Scala'},
{'developer': 'Rasmus Lerdorf', 'language': 'PHP'},
{'developer': 'Yukihiro Matsumoto', 'language': 'Ruby'},
{'developer': 'Dennis Ritchie', 'language': 'C'}]Відформатоване виведення створеного списку словників забезпечила функція pprint() з однойменного модуля.
8.6.2. XML
Для обміну структурами даних між програмами необхідний спосіб кодувати ієрархії, послідовності, множини та інші структури за допомогою тексту.
XML є найвідомішим форматом розмітки, який можна використовувати у даному випадку. XML є ієрархічним форматом даних, і найбільш природним способом його представлення є деревоподібна структура.
Для структурування даних цей формат використовує наступний синтаксис:
<?xml version="1.0"?>
<data class="countries">
<country name="Qatar">
<rank>1</rank>
<year>2018</year>
<gdppc>130475</gdppc>
<neighbor name="Saudi Arabia" direction="S"/>
</country>
<country name="Singapore">
<rank>3</rank>
<year>2018</year>
<gdppc>100345</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Norway">
<rank>6</rank>
<year>2018</year>
<gdppc>74356</gdppc>
<neighbor name="Sweden" direction="E"/>
</country>
<country name="Germany">
<rank>16</rank>
<year>2018</year>
<gdppc>52559</gdppc>
<neighbor name="Nederland" direction="W"/>
<neighbor name="Danmark" direction="N"/>
<neighbor name="Czech Republic" direction="E"/>
<neighbor name="Switzerland" direction="S"/>
</country>
<country name="Ukraine">
<rank>111</rank>
<year>2018</year>
<gdppc>9283</gdppc>
<neighbor name="Belarus" direction="N"/>
<neighbor name="Poland" direction="W"/>
</country>
</data>Найпростіший спосіб проаналізувати XML у Python - використати бібліотеку ElementTree.
Спробуємо зробити такий аналіз на прикладі файла country_data.xml , що містить дані щодо деяких країн за валовим внутрішнім продуктом (купівельною спроможністю) на душу населення.
Спочатку необхідно зчитати дані із файла country_data.xml:
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()Дані формату XML можна отримати також безпосередньо з рядка:
root = ET.fromstring(country_data_as_string)Звертаючись до об’єкта root
print(root.tag)
print(root.attrib)ми можемо отримати значення кореневого тега і словника його атрибутів:
data
{'class': 'countries'}Об’єкт root також має дочірні вузли (теги). Пройдемо у циклі по дочірнім тегам
for child in root:
print(child.tag, child.attrib)і отримаємо назви дочірніх (вкладених) тегів та їхні словники атрибутів:
country {'name': 'Qatar'}
country {'name': 'Singapore'}
country {'name': 'Norway'}
country {'name': 'Germany'}
country {'name': 'Ukraine'}Як бачимо, ми можемо отримати доступ до певних дочірніх тегів за індексом, використовуючи команду, на зразок print(root[0][2].text) (функція text() повертає текстовий вміст елемента):
130475Використаємо функцію iter(), яка рекурсивно перебирає всі дочірні теги, теги дочірніх тегів і т. д.
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)для пошуку назв країн-сусідок тих країн, для яких наведені дані валового внутрішнього продукту на душу населення:
{'name': 'Saudi Arabia', 'direction': 'S'}
{'name': 'Malaysia', 'direction': 'N'}
{'name': 'Sweden', 'direction': 'E'}
{'name': 'Nederland', 'direction': 'W'}
{'name': 'Danmark', 'direction': 'N'}
{'name': 'Czech Republic', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'S'}
{'name': 'Belarus', 'direction': 'N'}
{'name': 'Poland', 'direction': 'W'}Використаємо ще кілька функції для розбору дерева документа:
for country in root.findall('country'):
rank = country.find('rank').text
name = country.get('name')
print(name, rank)-
findall()- знаходить тільки теги, які є прямими нащадками кореневого тега (у нашому випадку здійснюється пошук тегівcountryякі є прямими нащадками тегаdata) -
find()- знаходить перший дочірній тег (у нашому випадку здійснюється пошук першого тегаrankвсередині тегаcountry) -
get()- отримує доступ до атрибутів тега (у нашому випадку повертається значення атрибутаnameусіх тегівcountry)
Результатами виконання наведеного коду будуть рядки з назвами країн і їхніми рангами:
Qatar 1
Singapore 3
Norway 6
Germany 16
Ukraine 111У підсумку, об’єднаємо усі наведені відомості в один код:
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()
print('tag:', root.tag)
for child in root:
print('\ttag:', child.tag, 'attributes:', child.attrib)
for grandchild in child:
print('\t\ttag:', grandchild.tag, 'attributes:', grandchild.attrib)Для кожного елемента у виведеній структурі tag - це рядок тега, а attrib - це словник його атрибутів:
tag: data
tag: country attributes: {'name': 'Qatar'}
tag: rank attributes: {}
tag: year attributes: {}
tag: gdppc attributes: {}
tag: neighbor attributes: {'name': 'Saudi Arabia', 'direction': 'S'}
tag: country attributes: {'name': 'Singapore'}
tag: rank attributes: {}
tag: year attributes: {}
tag: gdppc attributes: {}
tag: neighbor attributes: {'name': 'Malaysia', 'direction': 'N'}
tag: country attributes: {'name': 'Norway'}
tag: rank attributes: {}
tag: year attributes: {}
tag: gdppc attributes: {}
tag: neighbor attributes: {'name': 'Sweden', 'direction': 'E'}
tag: country attributes: {'name': 'Germany'}
tag: rank attributes: {}
tag: year attributes: {}
tag: gdppc attributes: {}
tag: neighbor attributes: {'name': 'Nederland', 'direction': 'W'}
tag: neighbor attributes: {'name': 'Danmark', 'direction': 'N'}
tag: neighbor attributes: {'name': 'Czech Republic', 'direction': 'E'}
tag: neighbor attributes: {'name': 'Switzerland', 'direction': 'S'}
tag: country attributes: {'name': 'Ukraine'}
tag: rank attributes: {}
tag: year attributes: {}
tag: gdppc attributes: {}
tag: neighbor attributes: {'name': 'Belarus', 'direction': 'N'}
tag: neighbor attributes: {'name': 'Poland', 'direction': 'W'}
Бібліотека ElementTree має багато інших способів роботи з даними, організованими у форматі XML. Всі подробиці можна знайти у документації ElementTree .
|
8.6.3. JSON
JSON (JavaScript Object Notation) популярний формат обміну даними. Він є частиною мови JavaScript і, водночас, гарним вибором при визначенні формату даних для обміну між програмами. Дані у цьому форматі можна передавати програмам, написаним на багатьох інших мовах програмування.
Для роботи з форматом JSON у Python існує модуль з ім’ям json. Розглянемо, як можна використовувати цей модуль, на прикладі файла із звітом про погоду на Марсі. Завантажте файл із сайту NASA і збережіть його з ім’ям mars_weather.json.
Файл має формат JSON і наступний вміст (скорочена форма):
{
"211":{
"AT":{
"av":-68.537,
"ct":88777,
"mn":-100.965,
"mx":-24.343
},
"First_UTC":"2019-07-01T00:23:47Z",
"HWS":{
"av":4.316,
"ct":40197,
"mn":0.138,
"mx":15.415999999999999
},
"Last_UTC":"2019-07-02T01:03:22Z",
"PRE":{
"av":762.93,
"ct":887772,
"mn":738.133,
"mx":782.7239999999999
},
"Season":"winter",
"WD":{
"0":{
"compass_degrees":0.0,
"compass_point":"N",
"compass_right":0.0,
"compass_up":1.0,
"ct":4
},
"10":{
"compass_degrees":225.0,
"compass_point":"SW",
"compass_right":-0.707106781187,
"compass_up":-0.707106781187,
"ct":3528
}
}
}
}Отже, виконаємо кілька перетворень з даними файла. Використаємо функцію load(), яка отримує як параметр об’єкт файла file_json і підтримує функцію читання read(), для зчитування даних з файла mars_weather.json у форматі JSON
import json
with open('mars_weather.json', 'r') as file_json:
weather = json.load(file_json)
print(weather)
print(weather['211']['Season'])
print(isinstance(weather, dict))і перетворення у словник Python:
{'211': {'AT': {'av': -68.537, 'ct': 88777, 'mn': -100.965, 'mx': -24.343}, 'First_UTC': '2019-07-01T00:23:47Z', 'HWS': {'av': 4.316, 'ct': 40197, 'mn': 0.138, 'mx': 15.415999999999999}, 'Last_UTC': '2019-07-02T01:03:22Z', 'PRE': {'av': 762.93, 'ct': 887772, 'mn': 738.133, 'mx': 782.7239999999999}, 'Season': 'winter', 'WD': {'0': {'compass_degrees': 0.0, 'compass_point': 'N', 'compass_right': 0.0, 'compass_up': 1.0, 'ct': 4}, '10': {'compass_degrees': 225.0, 'compass_point': 'SW', 'compass_right': -0.707106781187, 'compass_up': -0.707106781187, 'ct': 3528}}}}
winter
TrueЯкщо формат JSON необхідно перетворити у рядок, використовують функцію dumps():
weather_str = json.dumps(weather)
print(weather_str)
print(isinstance(weather_str, str)) #Об’єкт JSON був перетворений в єдиний рядок:
{"211": {"AT": {"av": -68.537, "ct": 88777, "mn": -100.965, "mx": -24.343}, "First_UTC": "2019-07-01T00:23:47Z", "HWS": {"av": 4.316, "ct": 40197, "mn": 0.138, "mx": 15.415999999999999}, "Last_UTC": "2019-07-02T01:03:22Z", "PRE": {"av": 762.93, "ct": 887772, "mn": 738.133, "mx": 782.7239999999999}, "Season": "winter", "WD": {"0": {"compass_degrees": 0.0, "compass_point": "N", "compass_right": 0.0, "compass_up": 1.0, "ct": 4}, "10": {"compass_degrees": 225.0, "compass_point": "SW", "compass_right": -0.707106781187, "compass_up": -0.707106781187, "ct": 3528}}}}
TrueЯкщо необхідно записати дані у файл у форматі JSON використовують функцію dump(), яка працює протилежно по відношенню до load(). Функція dump() отримує як параметр об’єкт файла file_json і містить функцію запису write() (використаємо значення weather, отримане з попереднього прикладу):
with open('mars_weather_out.json', 'w') as file_json:
json.dump(weather, file_json)Повернемося до завантаженого на початку файла mars_weather.json. Ззовні він нагадує формат JSON, але, насправді, це всього лише подання об’єкта JSON у вигляді послідовності байтів.
Для перевірки структури даних на відповідність формату JSON можна використати JSON Formatter & Validator .
|
Щоб перетворити цю послідовність у реальний об’єкт JSON і перетворити у словник Python, необхідно скористатися функцією loads(), яка протилежно працює по відношенню до функції dumps() (використаємо значення weather_str, отримане раніше):
weather_dict = json.loads(weather_str)
print(weather_dict)
print(isinstance(weather_dict, dict))Зверніть увагу на те, що виклик loads() отримує рядкове подання об’єкту JSON і перетворює його у словник Python:
{'211': {'AT': {'av': -68.537, 'ct': 88777, 'mn': -100.965, 'mx': -24.343}, 'First_UTC': '2019-07-01T00:23:47Z', 'HWS': {'av': 4.316, 'ct': 40197, 'mn': 0.138, 'mx': 15.415999999999999}, 'Last_UTC': '2019-07-02T01:03:22Z', 'PRE': {'av': 762.93, 'ct': 887772, 'mn': 738.133, 'mx': 782.7239999999999}, 'Season': 'winter', 'WD': {'0': {'compass_degrees': 0.0, 'compass_point': 'N', 'compass_right': 0.0, 'compass_up': 1.0, 'ct': 4}, '10': {'compass_degrees': 225.0, 'compass_point': 'SW', 'compass_right': -0.707106781187, 'compass_up': -0.707106781187, 'ct': 3528}}}}
True8.7. Файли бази даних
Базами даних у комп’ютерному світі користуються повсюдно. Для зберігання і вибірки значних обсягів даних, зазвичай, застосовується той чи інший різновид бази даних.
Cловосполучення «база даних» використовується у декількох випадках: коли мова йде про сервер, про сховище і про дані, які там зберігаються. Якщо потрібно згадати їх одночасно, можна назвати їх сервером бази даних, базою даних і даними.
Розглянемо реляційні бази даних. Ця технологія перевірена часом і отримала повсюдне поширення.
| Бази даних називаються реляційними, якщо вони показують відношення між різними типами даних, які представлені у вигляді таблиць. |
Python може підключатися до безлічі різних реляційних баз даних, і, в основному, працює з базами даних за єдиною схемою.
8.7.1. Python Database API
Програмний інтерфейс програми (Application Programming Interface, API ) - набір чітко визначених методів для взаємодії різних компонентів, який можна використовувати для отримання доступу до веб-систем, операційних систем, баз даних тощо.
|
Python містить стандартний Database API , в якому вказані деякі стандартні правила підключення до баз даних.
Розглянемо його основні функції:
-
connect()- створення з’єднання з базою даних. Виклик цієї функції може включати в себе аргументи, на зразок, імені користувача, пароля, адреси сервера та ін. -
cursor()- створення об’єкта курсору, призначеного для роботи із запитами. -
execute()іexecutemany()- запуск однієї або багато командSQL. -
fetchone(),fetchmany()іfetchall()- отримання результатів роботи функціїexecute().
8.7.2. Мова запитів SQL
SQL - це декларативна універсальна мова реляційних баз даних. Запити SQL до бази даних є текстовими рядками, які комп’ютер-клієнт відправляє серверу бази даних, а той, в свою чергу, визначає, що з ними робити далі.
Існують дві основні категорії SQL:
-
DDL(Data Definition Language, мова визначення даних) - обробляє створення, видалення, обмеження і дозволи для таблиць, баз даних. -
DML(Data Manipulation Language, мова маніпулювання даними) - обробляє додавання даних, їх вибірку, оновлення та видалення.
У таблиці, поданій нижче, перераховані основні команди SQL DDL:
| Операція | Шаблон SQL |
Приклад SQL |
|---|---|---|
Створення бази даних |
|
|
Вибір поточної бази даних |
|
|
Видалення бази даних і її таблиць |
|
|
Створення таблиці |
|
|
Видалення таблиці |
|
|
Видалення усіх записів (рядків) таблиці |
|
|
Мова SQL не залежить від регістру, але ключові слова пишуться ВЕЛИКИМИ ЛІТЕРАМИ, щоб можна було відрізнити їх від назв полів.
|
Основні операції DML реляційної бази даних можна запам’ятати за допомогою акроніма CRUD:
-
Create - вставка за допомогою оператора
INSERT -
Read - вибір за допомогою оператора
SELECT -
Update - оновлення за допомогою оператора
UPDATE -
Delete - видалення за допомогою оператора
DELETE
У таблиці, поданій нижче, перераховані основні команди SQL DML:
| Операція | Шаблон SQL |
Приклад SQL |
|---|---|---|
Додавання запису (рядка) у таблицю |
|
|
Вибір усіх записів (рядків) і полів (стовпців) з таблиці |
|
|
Вибір всіх записів (рядків) з деяких полів (стовпців) таблиці |
|
|
Вибір деяких записів (рядків) з деяких полів (стовпців) таблиці |
|
|
Зміна деяких записів (рядків) у полі (стовпці) таблиці |
|
|
Видалення деяких записів (рядків) таблиці |
|
|
8.7.3. SQLite
SQLite - це легка реляційна база даних з відкритим початковим кодом.
Вона є частиною стандартної бібліотеки Python і зберігає бази даних у звичайних файлах. Ці файли можна переносити на інші комп’ютери і в операційні системи, що робить SQLite портативним рішенням для створення простих реляційних баз даних, що добре підходить для невеликих застосунків.
На відміну від MySQL і PostgreSQL , SQLite має менше можливостей, але вона підтримує мову запитів SQL і дозволяє кільком користувачам працювати з нею одночасно.
Браузери і операційні системи використовують SQLite як вбудовану базу даних.
|
Робота з базою даних починається з виклику connect() для встановлення з’єднання з локальним файлом бази даних, який треба створити або використовувати.
Для прикладу, створимо базу даних ishop.db. База даних буде містити таблицю computers з інформацією про товари інтернет-магазину комп’ютерної техніки. У таблицю будуть входити такі поля:
-
id- унікальний номер товару (первинний ключ) -
name- назва товару (рядок змінної довжини) -
count- кількість одиниць конкретного товару (ціле число) -
price- ціна одного екземпляру конкретного товару (дійсне число)
import sqlite3 (1)
conn = sqlite3.connect('ishop.db') (2)
curs = conn.cursor() (3)
curs.execute('''CREATE TABLE сomputers (id INT PRIMARY KEY, name VARCHAR(20), count INT, price FLOAT)''') (4)
conn.commit() (5)
curs.close() (6)
conn.close() (7)
Використовуйте потрійні лапки (''' ''') при створенні довгих рядків і при створенні запитів SQL.
|
Якщо записати для поля id тип INTEGER PRIMARY KEY, значення id буде збільшуватися на одиницю автоматично.
|
-
Імпортуємо бібліотеку, що відповідає типу нашої бази даних (
sqlite3). -
Створюємо з’єднання з нашою базою даних (у нашому прикладі це створення файла бази даних
ishop.db). -
Створюємо курсор - це спеціальний об’єкт (
curs), який робить запити і отримує їх результати. -
Створюємо таблицю
computersз відповідними полями. -
Якщо ми не просто читаємо дані, а й вносимо зміни у базу даних - необхідно зберегти транзакцію. Рядок
conn.commit()дозволяє зберети поточні зміни. -
Перед тим, як завершити роботу з
SQLite, необхідно закрити курсор. -
Перед тим, як завершити роботу з
SQLite, необхідно закрити з’єднання.
Тепер додамо у наш магазин декілька товарів:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute('INSERT INTO computers VALUES(1, "PC", 5, 7570.50)')
curs.execute('INSERT INTO computers VALUES(2, "Notebook", 8, 11430.30)')
conn.commit()
curs.close()
conn.close()Існує більш безпечний спосіб додавання даних - використовуючи заповнювач у вигляді ?:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
ins = 'INSERT INTO computers (id, name, count, price) VALUES(?, ?, ?, ?)'
curs.execute(ins, (3, 'TabletPC', 4, 3970.20))
ins = 'INSERT INTO computers (id, name, count, price) VALUES(?, ?, ?, ?)'
curs.execute(ins, (4, 'Console', 2, 16780.90))
conn.commit()
curs.close()
conn.close()Цього разу у запиті використовувалися чотири знаки ?, щоб показати, що планується додати чотири значення, а потім додати ці значення списком у функцію execute().
Заповнювачі полегшують розставлення лапок і захищають від SQL-ін’єкцій.
|
SQL ін’єкція - зовнішня атака, поширена в мережі Інтернет, яка впроваджує у систему шкідливі команди SQL.
|
Також в запиті можна використовувати імена змінних з префіксом :. У цьому випадку у запиті слід передати відповідний словник зі значеннями, які вставляються у базу даних, і ключами, що є іменами цих змінних:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute("INSERT INTO computers (id, name, count, price) VALUES (:idpc, :namepc, :countpc, :pricepc)", {"idpc": 5, "namepc": "Smartphone", "countpc": 10, "pricepc": 4999.99})
conn.commit()
curs.close()
conn.close()Тепер перевіримо, чи зможемо ми отримати список наших товарів:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute('SELECT * FROM computers')
conn.commit()
rows = curs.fetchall()
print(rows)
curs.close()
conn.close()Результат виконання:
[(1, 'PC', 5, 7570.5), (2, 'Notebook', 8, 11430.3), (3, 'TabletPC', 4, 3970.2), (4, 'Console', 2, 16780.9), (5, 'Smartphone', 10, 4999.99)]Також можна у циклі пройти по рядкам об’єкта курсору
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute("SELECT * FROM computers")
for row in curs:
print(row)
curs.close()
conn.close()за аналогією з перебором по файла:
(1, 'PC', 5, 7570.5)
(2, 'Notebook', 8, 11430.3)
(3, 'TabletPC', 7, 3970.2)
(4, 'Console', 2, 16780.9)
(5, 'Smartphone', 10, 4999.99)Отримаємо список знову, але на цей раз впорядкуємо його за кількістю товарів:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute('SELECT * FROM computers ORDER BY count')
rows = curs.fetchall()
print(rows)
curs.close()
conn.close()Результат впорядкування за зростанням за полем count (за кількістю товарів):
[(4, 'Console', 2, 16780.9), (3, 'TabletPC', 4, 3970.2), (1, 'PC', 5, 7570.5), (2, 'Notebook', 8, 11430.3), (5, 'Smartphone', 10, 4999.99)]Отримаємо список товарів за полем price (за спаданням ціни):
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute('SELECT * FROM computers ORDER BY count DESC')
rows = curs.fetchall()
print(rows)
curs.close()
conn.close()Результат впорядкування за спаданням:
[(4, 'Console', 2, 16780.9), (2, 'Notebook', 8, 11430.3), (1, 'PC', 5, 7570.5), (5, 'Smartphone', 10, 4999.99), (3, 'TabletPC', 4, 3970.2)]Зробимо вибірку товарів, які коштують найдорожче, використавши такий код:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute('SELECT * FROM computers WHERE price = (SELECT MAX(price) FROM computers)')
rows = curs.fetchall()
print(rows)
curs.close()
conn.close()Результат у даному випадку буде такий:
[(4, 'Console', 2, 16780.9)]Оновимо дані у базі даних ishop.db. Змінимо кількість TabletPC з 4 на 7:
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute('UPDATE computers SET count = 7 WHERE id = 3')
conn.commit()
curs.execute('SELECT * FROM computers WHERE id = 3')
row = curs.fetchone()
print(row)
curs.close()
conn.close()Запис у базі даних із значенням id = 3 зміниться на такий:
(3, 'TabletPC', 7, 3970.2)Виконаємо операцію видалення товарів з бази даних за назвою PC
import sqlite3
conn = sqlite3.connect('ishop.db')
curs = conn.cursor()
curs.execute("DELETE FROM computers WHERE name = 'PC'")
conn.commit()
curs.execute("SELECT * FROM computers")
row = curs.fetchall()
print(row)
curs.close()
conn.close()і відобразимо усі записи із бази даних (товар з назвою PC відсутній):
[(2, 'Notebook', 8, 11430.3), (3, 'TabletPC', 7, 3970.2), (4, 'Console', 2, 16780.9), (5, 'Smartphone', 10, 4999.99)]8.8. Завдання
8.8.1. Контрольні запитання
-
Які аргументи задають режим відкривання файла з допомогою функції
open()? -
За допомогою яких функцій можна записувати у файл?
-
Чим відрізняється робота функцій
read(),readline()іreadlines()? -
Для чого використовують у роботі з файлами оператор
with? -
Як створити і прочитати бінарний файл?
-
Які засоби
Pythonвикористовуються для відслідковування місцезнаходження конкретних байтів у бінарних файлах? -
Як використовуються функції
csv.reader()іcsv.writer? -
Яка функція приймає
JSON-рядок і повертає структуру данихPython? -
Яка функція приймає структуру даних
Python, а повертає рядокJSON-даних? -
Які інструменти
Pythonвикористовують для отримання доступу до баз даних і роботи з ними? -
Що таке
SQL? -
Наведіть приклад запиту з використанням мови
SQL.
8.8.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Збережіть рядок
'Test variable to write to file'у зміннуtest1і запишіть зміннуtest1у файл з ім’ямtests.txt. -
Відкрийте файл
tests.txtі зчитайте його вміст у рядокtest2. -
Порівняйте рядки
test1іtest2? -
Скопіюйте наступні кілька рядків у файл
painters.csv.
author, canvas
Vincent Willem van Gogh, "Vase with sunflowers"
Rembrandt Harmenszoon van Rijn, "Aristotle"
Leonardo da Vinci, "Self-portrait"-
Використайте модуль
csvі його функціюDictReader(), щоб зчитати вміст файлаpainters.csvу зміннуpainters. Виведіть значення змінної на екран.
-
Створіть
CSV-файлimdb.csvз рейтингом фільмів за версієюIMDb, використовуючи список словників:
imdb = [
{
'title': 'Lord of the Rings: Two towers',
'year': 2002,
'rating': 8.7},
{
'title': 'Matrix',
'year': 1999,
'rating': 8.7},
{
'title': 'Interstellar',
'year': 2014,
'rating': 8.5},
{
'title': 'Back to the Future',
'year': 1985,
'rating': 8.5},
{
'title': 'Logan: Wolverine',
'year': 2017,
'rating': 8.1}
]8.8.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Створіть новий файл
numbers.txtу текстовому редакторі і запишіть у нього10чисел, кожне з нового рядка. Напишіть програму, яка зчитує ці числа з файла і обчислює їх суму, виводить цю суму на екран і, водночас, записує цю суму у інший файл з назвоюsum_numbers.txt. -
Реалізуйте програму, яка зчитує ціле число, що вводиться з командного рядка, і записує у текстовий файл інформацію, щодо парності або непарності числа.
-
Створіть новий файл у текстовому редакторі і напишіть кілька рядків тексту у ньому про можливості
Python. Кожен рядок повинен починатися з фрази:In Python you can .... Збережіть файл з ім’ямlearning_python.txt. Напишіть програму, яка зчитує файл і виводить текст з перебором рядків об’єкта файла і зі збереженням рядків у списку з подальшим виведенням списку поза блокомwith. -
Функція
replace()може використовуватися для заміни будь-якого слова у рядку іншим словом. Прочитайте кожен рядок зі створеного у попередньому завданні файлаlearning_python.txtі замініть словоPythonназвою іншої мови, наприкладCпри виведенні на екран. -
Створіть порожній файл
guest_book.txtу текстовому редакторі. Напишіть циклwhile, який запитує у користувачів імена. При введенні кожного імені виведіть на екран рядок з вітанням для користувача і запишіть рядок вітання у файл з ім’ямguest_book.txt. Простежте за тим, щоб кожне повідомлення розміщувалося в окремому рядку файла. Передбачте вихід з циклу. -
Зайдіть на сайт Project Gutenberg’s і знайдіть кілька книг для аналізу. Завантажте текстові файли цих творів або скопіюйте текст з браузера у текстовий файл на вашому комп’ютері. Напишіть програму, яка зчитує дані з файла і визначає кількість входжень слова
'the'в кожному тексті незалежно від регістру. Для підрахунку кількості входжень слова або виразу в рядок можна скористатися функцієюcount(). -
Завантажте текстову версію однієї з книг із сайту Project Gutenberg’s . Замініть усі розриви рядків у тексті символом пропуску і запишіть відформатований текст у новий файл
formatted_text.txt. -
Завантажте текстову версію книги The Life and Adventures of Robinson Crusoe By Daniel Defoe із сайту Project Gutenberg’s . Витягніть із тексту заголовки усіх розділів, які мають вигляд, на зразок:
CHAPTER I—START IN LIFE. Запишіть знайдені назви у новий файлchapters.txt. -
Визначте відсоток малих і великих літер у тексті, що зберігається у файлі. Скористайтеся, як зразком вхідного текстового файла, файл The Count of Monte Cristo із сайту Project Gutenberg’s . Використайте функцію
isalpha(). -
Використайте модуль
sqlite3, щоб створити базу данихSQLiteпід назвоюimdb.dbі таблицюratings, що містить наступні поля:id (INTEGER PRIMARY KEY),title (VARCHAR(20)),year (INT),rating (FLOAT). Зчитайте дані з файлаimdb.csvі додайте їх у таблицюratings. Зчитайте і виведіть на екран усі значення таблиціratingsу алфавітному порядку за полемtitle. Зчитайте і виведіть на екран усі записи таблиціratingsз ретингом більшим за8.70.
9. Система
Робота з файловою системою передбачає створення, перейменування, переміщення або звернення до файлів і каталогів. Усі ці та багато інших завдань можна виконати за допомогою програм, написаних на Python.
Python надає багато системних функцій, що містяться в модулі os (скорочення від Operating System - операційна система), який необхідно імпортувати для роботи програм.
Всі наступні приклади коду, за замовчуванням, виконуються у середовищі Windows.
|
9.1. Файли і каталоги
| Файл - це послідовність байтів, яка зберігається під певною назвою. |
Частина назви файла, яка слідує за останньою крапкою, називається розширенням файла і вказує на тип файла. Розширення файла, зазвичай, надає програма, у якій він був створений.
Наприклад, файл з назвою projects.docs має тип файла - документ Word, про що свідчить розширення .docs. Частина назви файла (projects) до останньої крапки - це ім’я файла, яке вказує користувач.
Файл має дві ключові ознаки: назва файла і шлях до файла.
Шлях визначає, де саме на комп’ютері знаходиться файл. Наприклад, файл з назвою projects.docs може мати шлях до файла C:\Users\gt\Documents. Це означає, що файл projects.docs зберігається у каталозі Documents.
Частина C:\ шляху до файла - це кореневий каталог, який містить усі інші каталоги (gt, Users) і сам файл projects.docs.
У системах Windows кореневим каталогом є C:\, а шляхи до файлів записують з використанням зворотного слешу (\), який розділяє імена каталогів. В Linux Ubuntu кореневим каталогом є каталог /, а розділення імен каталогів виконують з використанням прямого слеша (/).
Організацію каталогів у Windows показує наступна ілюстрація:
Шлях до файла (або каталогу), який враховує використання обох слешів, можна сформувати з використанням функції join(), яка міститься у модулі path, який у свою чергу міститься у модулі os.
Інформацію про використання модуля os.path можна знайти на сайті документації Python.
|
Якщо передати у цю функцію значення назв файлів і каталогів й виконати наступний код
import os
print(os.path.join('usr', 'bin', 'media'))функція поверне значення, у якому сформується шлях з коректною підстановкою слеша-розділювача:
usr\bin\mediaЯкщо ж виконати даний приклад в інтерактивному режимі інтерпретатора Python, виклик функції os.path.join() поверне рядок:
'usr\\bin\\media'| Cимволи зворотного слешу продубльовані, оскільки кожний з них потребує екранування іншим символом зворотного слеша. |
Якщо викликати вищезгадану фукнцію os.path.join() в Linux Ubuntu, вона поверне рядок:
'usr/bin/media'Отже, для формування шляхів до файлів або каталогів у вигляді рядків використовується функція os.path.join(). Наприклад, наступний код
import os
myfiles = ['accounts.txt', 'details.csv', 'invite.docs']
for filename in myfiles:
print(os.path.join('C:\\Users\\gt\\Documents', filename))формує шляхи до файлів, додаючи до імен каталогів назви файлів зі списку:
C:\Users\gt\Documents\accounts.txt
C:\Users\gt\Documents\details.csv
C:\Users\gt\Documents\invite.docsКожна програма, яка виконується на комп’ютері, має свій поточний робочий каталог (current working directory - cwd).
Будь-які шляхи до файлів або каталогів, які не починаються з кореневого каталогу, задаються відносно поточного робочого каталогу.
Для отримання значення поточного робочого каталогу у вигляді рядка використовується функція os.getcwd(), а для переходу з поточного робочого каталогу у інший каталог - функція os.chdir().
import os
print(os.getcwd())
os.chdir('C:\\Windows\\Temp')
print(os.getcwd())У даному випадку, в якості робочого поточного каталогу встановлюється каталог по шляху C:\Python36, відбувається перехід у інший каталог, який стає поточним:
C:\Python36
C:\Windows\Temp
При спробі перейти у каталог, якого не існує, Python виведе повідомлення про помилку.
|
Існує два способи визначення шляху до файла або каталогу:
-
абсолютний шлях - завжди починається з імені кореневого каталогу
-
відносний шлях - задається відносно поточного робочого каталогу програми
Існують також каталоги, які позначаються одним (.) або двома (..) символами крапки. Це не реальні каталоги, а спеціальні імена, які використовуються для визначення шляхів.
Зрозумілою мовою, позначення . означає «поточний каталог», а позначення .. - «каталог вищого рівня».
Приклад розташування каталогів і файлів показаний на наступній ілюстрації (в якості поточного робочого каталогу обраний каталог по шляху C:/books):
Використовування імені .\ на початку відносного шляху є необов’язковим. Наприклад, шляхи .\authors.txt і authors.txt ведуть до одного файла.
|
Для створення нових каталогів використовується функція os.makedirs(), яка створює усі необхідні проміжні каталоги:
os.makedirs('C:\\Python36\\other\\myprograms')Модуль os.path містить функції для визначення абсолютного шляху по заданому відносному, а також для перевірки того, чи шлях є абсолютним.
-
Виклик
os.path.abspath(path)- повертає рядок абсолютного шляху до файла або каталогу. -
Виклик
os.path.isabs(path)- повертаєTrue, якщо шлях є абсолютним, іFalseу протилежному випадку, коли шлях виявиться відносним. -
Виклик
os.path.relpath(path, start)- повертає рядок відносного шляху від точкиstartдоpath. Якщоstartне вказаний, то в якості нього використовується поточний робочий каталог.
На наступному прикладі коду:
import os
print(os.path.abspath('.'))
print(os.path.abspath('.\\Scripts'))
print(os.path.isabs('.'))
print(os.path.isabs(os.path.abspath('.')))
print(os.path.relpath('C:\\Windows', 'C:\\'))
print(os.path.relpath('C:\\Windows', 'C:\\Python36\\Scripts'))
print(os.getcwd())робота цих функцій виглядає так:
C:\Python36
C:\Python36\Scripts
False
True
Windows
..\..\Windows
C:\Python36Для отримання із повного шляху лише назви файла використовують функцію os.path.basename(). Якщо необхідно отримати частину шляху без назви файла використовують функцію os.path.dirname().
Якщо шлях до файла вважати таким рядком 'C:\\Windows\\System32\\calc.exe', то ці дві функції:
import os
path = 'C:\\Windows\\System32\\calc.exe'
print(os.path.basename(path))
print(os.path.dirname(path))відпрацюють так:
calc.exe
C:\Windows\System32Щоб отримати одночасно і назву файла, так і імена каталогів на шляху до нього, можна скористатися функцією split() у такому виконанні:
import os
path = 'C:\\Windows\\System32\\calc.exe'
print(os.path.split(path))Результатом виведення буде кортеж з двох елементів:
('C:\\Windows\\System32', 'calc.exe')Щоб отримати список усіх каталогів на шляху до файла і назву самого файла використовують розділювач os.path.sep.
import os
path = 'C:\\Windows\\System32\\calc.exe'
print(path.split(os.path.sep))Для системи Windows буде такий результат:
['C:', 'Windows', 'System32', 'calc.exe']Для системи Linux Ubuntu
import os
print('/usr/bin'.split(os.path.sep))першим елементом такого списку буде порожній рядок:
['', 'usr', 'bin']У модулі os.path присутні функції, які дозволяють обчислювати розміри файлів у байтах і визначати, які файли та каталоги знаходяться у вказаному каталозі. До таких функцій належать:
-
os.path.getsize(path)- повертає у байтах розмір файла, шлях до якого вказаний уpath. -
os.listdir(path)- повертає список рядків з назвами усіх файлів, шлях до яких вказаний уpath.
Функція listdir() міститься у модулі os, а не у модулі os.path.
|
Коли виконати поданий код
import os
print(os.path.getsize('C:\\Windows\\System32\\calc.exe'))
print(os.listdir('C:\\Windows\\System32'))отримаємо розмір у байтах вказаного файла і список усіх файлів вказаного каталогу.
Для знаходження сумарного розміру файлів, наприклад, у каталозі по шляху C:\\Python36, можна використати таку програму:
total = 0
for filename in os.listdir('C:\\Python36'):
total = total + os.path.getsize(os.path.join('C:\\Python36', filename))
print(total)Результатом виконання даної програми буде розмір у байтах усіх файлів каталогу по шляху C:\\Python36:
4582106Функції Python для роботи з файлами і каталогами можуть повідомляти про помилки, коли не знаходять шлях до файла або каталогу. Модуль os.path містить функції, які перевіряють, чи існує шлях до каталогу або файла:
-
os.path.exists(path)- повертає значенняTrue, якщо файл (або каталог) за вказаним шляхомpathіснує, і значенняFalseу протилежному випадку -
os.path.isfile(path)- повертає значенняTrue, якщо файл за вказаним шляхомpathіснує, і значенняFalseу протилежному випадку -
os.path.isdir(path)- повертає значенняTrue, якщо каталог за вказаним шляхомpathіснує, і значенняFalseу протилежному випадку
Спробуємо подані функції у дії:
print(os.path.exists('C:\\Windows'))
print(os.path.exists('C:\\some_made_up_folder'))
print(os.path.isdir('C:\\Windows\\System32'))
print(os.path.isfile('C:\\Windows\\System32'))
print(os.path.isdir('C:\\Windows\\System32\\calc.exe'))
print(os.path.isfile('C:\\Windows\\System32\\calc.exe'))Результат перевірки матимуть такий вигляд:
True
False
True
False
False
TrueЩоб дізнатися, чи існують файли або каталоги з певними назвами, використовують функцію glob(), яка шукає шляхи, які співпадають із вказаним шаблоном. Функція працює за певними правилами:
-
*- збігається з усім -
?- збігається з одним символом -
[abc]- збігається з символамиa,bабоc -
[!abc]- збігається з усіма символами, окрімa,bабоc
Отримаємо всі файли і каталоги, імена яких:
-
починаються з літери
o -
складаються з двох символів
-
містять слово, яке починається з
c, далі містить довільну кількість символів і закінчується наdb -
починаються з літер
k, абоm, абоr
import glob
print(glob.glob('o*'))
print(glob.glob('??'))
print(glob.glob('c*db'))
print(glob.glob('[kmr]*'))Результат пошуку файлів або каталогів може бути наступним:
['open_port.py', 'output.txt']
[]
['cities.db']
['mars_weather.json', 'result.txt']Для виконання операції копіювання використовується функція copy(), яка знаходиться у модулі shutil. У наступному прикладі вміст файла file1.txt копіюється у файл file2.txt:
import shutil
shutil.copy('file1.txt', 'file2.txt')
Функція shutil.move() копіює файл, а потім видаляє оригінал.
|
Для перейменування імен файлів використовують функцію rename(). Роботу функції rename() можна побачити у наступному прикладі: файл one.txt перейменовується в two.txt:
import os
os.rename('one.txt', 'two.txt')Щоб видалити файл, використовується функція remove(), а для видалення каталогів - функція os.rmdir. Щоб «попрощатися» з файлом file.txt і каталогом my_old_folder, виконайте наступні команди:
import os
os.remove('file.txt')
os.rmdir('my_old_folder')9.2. Дата й час
Процес роботи з датами й часом викликає багато проблем, оскільки дати можуть бути представлені різними способами. Ось деякі з варіантів представлення простих дат:
-
July 29 1981
-
29 Jul 1981
-
29/7/1981
-
7/29/1981
Cистемні значення цієї дати можуть бути неоднозначними. У деяких з цих варіантів досить легко визначити, що 7 означає місяць, а 29 - день місяця, в основному тому, що у місяці не може бути номера 29.
Але як щодо дати 8/7/2019?
Високосні роки - це ще одна проблема. Кожен четвертий рік є високосним, а кожен сотий рік не є високосним, а кожен 400-й - є. Проте, використавши модуль calendar
import calendar
print(calendar.isleap(1900))
print(calendar.isleap(2000))
print(calendar.isleap(2019))можна перевірити, чи є рік високосним:
False
True
FalseРобота з часом також може завдати неприємностей, особливо, із-за годинних поясів і переходу на літній час. Якщо поглянути на карту годинних поясів, то виявиться, що ці пояси більше відповідають політичним та історичним кордонам, замість того, щоб змінюватися кожні 15 градусів (360 / 24) довготи. Крім того, різні країни переходять на літній час і назад у різні дні року.
Стандартна бібліотека Python надає багато модулів для роботи з датою і часом: datetime, time, calendar та ін. Розглянемо деякі з них.
9.2.1. Модуль datetime
У цьому модулі визначено такі об’єкти:
-
date- для років, місяців і днів -
time- для годин, хвилин, секунд і часток секунди -
datetime- для дати і часу одночасно -
timedelta- для інтервалів дати і/або часу
Отже, можна створити об’єкт date, вказавши рік, місяць і день:
import datetime
from datetime import date
independence_day = date(2020, 8, 24)
print(independence_day)
datetime.date(2020, 8, 24)
print(independence_day.day)
print(independence_day.month)
print(independence_day.year)
print(independence_day.isoformat())Ці значення (рік, місяць і день) будуть доступні як атрибути:
2020-08-24
24
8
2020
2020-08-24Останній рядок у коді виводить вміст об’єкту date з використанням функції isoformat(). iso у даному контексті відноситься до ISO 8601.
| ISO 8601 - міжнародний стандарт для представлення дати й часу. |
У цьому форматі дата записується, починаючи із самого загального елемента (рік) і закінчуючи найточнішим (день). Використовуючи цей формат можна коректно впорядкувати дати: спочатку по році, потім по місяцю, потім по дню. Зазвичай, цей формат вибирають для представлення даних у програмах і для назв файлів, які зберігають дані за датою.
Згенеруємо сьогоднішню дату, використовуючи функцію today():
from datetime import date
now = date.today()
print(now)Результат може бути таким:
2019-07-08У наступному прикладі
from datetime import date
from datetime import timedelta
now = date.today()
print(now) # сьогодні
one_day = timedelta(days=1) # часовий інтервал в 1 день
tomorrow = now + one_day
print(tomorrow) # взавтра
after_days = now + 17 * one_day # через 17 днів від сьогодні
print(after_days)
yesterday = now - one_day
print(yesterday) # вчораоб’єкт timedelta використовується для того, щоб додати до об’єкта date певний часовий інтервал:
2019-07-08
2019-07-09
2019-07-25
2019-07-07Об’єкт datetime має функцію now(),
from datetime import datetime
now = datetime.now()
print(now) # дата й час повністю
print(now.month) # місяць
print(now.day) # день
print(now.hour) # години
print(now.minute) # хвилини
print(now.second) # секунди
print(now.microsecond) # частки секундиза допомогою якої можна отримати поточні дату й час:
2019-07-08 20:41:26.343698
7
8
20
41
26
3436989.2.2. Модуль time
Одним із способів подання абсолютного часу є підрахунок кількості секунд, що пройшли з деякої стартової точки. Наприклад, у Unix використовується кількість секунд, що пройшли з півночі 1 січня 1970. Це значення часто називають epoch («епоха Unix»), і часто воно є найпростішим способом обмінюватися датою і часом між системами.
Функція time() модуля time повертає поточний час як значення epoch, а функція ctime() конвертує значення epoch у рядок:
import time
now = time.time()
print(now)
print(time.ctime(now))З результату видно, скільки пройшло секунд після настання 1970 року:
1562607827.8701854
Mon Jul 8 20:43:47 2019Функцію time() модуля time можна використовувати для визначення періодів часу виконання блоків коду програми. Напишемо невелику програму, яка виводить числа від 1000 до 1 включно і повідомлення про час роботи програми:
import time
starttime = time.time()
for i in range(1000, 0, -1):
print(i)
endtime = time.time()
print('The program has been running:', str(endtime - starttime), 'seconds.')Якщо виконати подану програму, можна отримати подібний результат:
1000
999
998
...
3
2
1
The program has been running: 0.2105104923248291 seconds.Іноді, потрібно отримати саме значення днів, годин, хвилин і т. д. Із модуля time такі значення можна отримати як об’єкти struct_time:
import time
now = time.time()
print(time.localtime(now))
print(time.gmtime(now))У даному прикладі використані:
-
функція
localtime()- представляє час у вашому поточному годинному поясі -
функція
gmtime()- представляє час у форматі UTC
Результати використання останніх двох функцій будуть такими:
time.struct_time(tm_year=2019, tm_mon=7, tm_mday=8, tm_hour=20, tm_min=48, tm_sec=49, tm_wday=0, tm_yday=189, tm_isdst=1)
time.struct_time(tm_year=2019, tm_mon=7, tm_mday=8, tm_hour=17, tm_min=48, tm_sec=49, tm_wday=0, tm_yday=189, tm_isdst=0)Дату й час можна перетворювати за допомогою функції strftime() з модуля time, яка у виведенні дати й часу використовує специфікатори виведення, показані у таблиці:
| Специфікатор | Одиниця дати/часу | Діапазон |
|---|---|---|
|
Рік |
|
|
Місяць |
|
|
Назва місяця |
|
|
День місяця |
|
|
Назва дня |
|
|
Години (24 години) |
|
|
Хвилини |
|
|
Секунди |
|
|
Мікросекунди |
|
Розглянемо приклад роботи функції strftime(), наданої модулем time. Вона перетворює об’єкт struct_time у рядок. Визначимо рядок формату під назвою row_format, використавши специфікатори формату з таблиці, і використаємо функцію localtime() з модуля time:
import time
row_format = "It's %A, %B %d, %Y, local time %H:%M:%S"
t = time.localtime()
print(t)
print(time.strftime(row_format, t))Результат роботи функції strftime():
time.struct_time(tm_year=2019, tm_mon=7, tm_mday=8, tm_hour=20, tm_min=53, tm_sec=51, tm_wday=0, tm_yday=189, tm_isdst=1)
It's Monday, July 08, 2019, local time 20:53:51Якщо ми спробуємо зробити це з об’єктом date,
from datetime import date
some_day = date(2020, 3, 4)
row_format = "It's %B %d, %Y, local time %I:%M:%S%p"
print(some_day.strftime(row_format))функція відпрацює тільки для дати, час буде встановлено в опівніч:
It's March 04, 2020, local time 12:00:00AMДля об’єкта time
from datetime import time
row_format = "It's %B %d, %Y, local time %I:%M:%S%p"
some_time = time(20, 55)
print(some_time.strftime(row_formбудуть перетворені тільки частини, що стосуються часу:
It's January 01, 1900, local time 08:55:00PMЄ інший шлях для перетворення рядка на дату або час. Для цього використовують функцію strptime() з рядком формату row_format. Рядок з датою і часом повинен точно збігатися із частинами рядка формату. Зазначимо формат «рік-місяць-день», на зразок 2019-07-21:
import time
row_format = "%Y-%m-%d"
print(time.strptime("2019-07-21", row_format))
print(time.strptime("2019-07-21", row_format)[6]) # 0 = Monday (0 = Понеділок)
print(time.strptime("2019-07-21", row_format)[7]) # номер дня у роціРезультати виведення будуть такими:
time.struct_time(tm_year=2019, tm_mon=7, tm_mday=21, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=202, tm_isdst=-1)
6
2029.3. Інструменти локалізації, модуль locale
При розробці програм, інколи, виникає необхідність мати справу з певними культурними особливостями в застосунку: форматування числових значень як валют різних країн, обробка символів відокремлення цілої та дробової частини числа, групування розрядів чисел, робота з датами.
Для усіх цих завдань використовують модуль locale, який забезпечує стандартний спосіб обробки операцій, які можуть залежати від мови або розташування користувача.
Дізнатися більш детально про механізм локалізації, ознайомитись з файлом модуля locale і правилами використання можна в офіційній документації Python.
|
Напишемо програму, яка повідомляє дату вашого народження для ваших міжнародних друзів із соціальної мережі. На екран буде друкуватися дата дня народження (місяць, число і день тижня) різними мовами.
Імена днів, місяців тощо відповідатимуть вашій локалі - набору параметрів, який визначає мову користувача, країну та будь-які інші особливі варіанти, які користувач хоче бачити у своєму інтерфейсі.
Використаємо модуль locale, який завантажує формати даних, специфічні для певного культурного оточення.
Щоб визначити, яка локаль у вас за замовчуванням, виконайте такий код:
import locale
print(locale.getdefaultlocale())Результатом роботи попереднього фрагменту коду буде кортеж, наприклад, з такими значеннями:
('uk_UA', 'cp1251')Перший рядок кортежу - ідентифікатор локалі ('uk_UA'), другий рядок - кодування (cp1251).
| Ідентифікатор локалі складається, щонайменше, з ідентифікатора мови та ідентифікатора регіону (країни). |
Щоб вивести на екран назви місяців і днів іншими мовами, необхідно змінити свою локаль за допомогою функції setlocale(): її перший аргумент має дорівнювати locale.LC_ALL для дати і часу, а другий аргумент - це рядок, що містить скорочення мови і країни.
Для розв’язування даної задачі назви локалей, у випадку Windows, отримаємо з таблиці локалей системи Moodle.
|
Необхідно враховувати і те, що часто у роботі з локалями можуть виникати помилки. Це можна передбачити, використовуючи обробники винятків.
Текст програми:
import locale, datetime
deafult_locale = locale.getdefaultlocale()
print('Default locale:', deafult_locale)
happy = datetime.date(2020, 3, 4)
print(happy.strftime('%A, %B %d'))
set_locale = locale.setlocale(locale.LC_ALL, '') # використовувати бажані локалі користувача
print('Set locale by default:', set_locale)
happy = datetime.date(2020, 3, 4)
print(happy.strftime('%A, %B %d'))
unsupported_locales = [] # список локалей, які не підтримуються
encode_errors_characters_locales = [] # список локалей у випадку проблем з кодуванням символів
# доповніть список іншими значеннями
localewin = [
'Afrikaans_South Africa.1252',
'Albanian_Albania.1250',
'Arabic_Saudi Arabia.1256',
'Basque_Spain.1252',
'Belarusian_Belarus.1251',
'Turkish_Turkey.1254',
'Ukrainian_Ukraine.1251',
'Vietnamese_Viet Nam.1258',
]
for lang_country in localewin:
try:
locale.setlocale(locale.LC_ALL, lang_country)
print(happy.strftime('%A, %B %d'), '//', lang_country.split('.')[0])
except locale.Error:
unsupported_locales.append(lang_country)
#print('unsupported locale setting')
except UnicodeEncodeError:
encode_errors_characters_locales.append(lang_country)
#print('can\'t encode characters')
print('Unsupported locales:', unsupported_locales)
print('Can\'t encode characters:', encode_errors_characters_locales)Результатом роботи програми буде:
Default locale: ('uk_UA', 'cp1251')
Wednesday, March 04
Set locale by default: Ukrainian_Ukraine.1251
середа, березень 04
Woensdag, Maart 04 // Afrikaans_South Africa
e mërkurë, Mars 04 // Albanian_Albania
الأربعاء, مارس 04 // Arabic_Saudi Arabia
asteazkena, Martxoa 04 // Basque_Spain
серада, сакавік 04 // Belarusian_Belarus
Çarşamba, Mart 04 // Turkish_Turkey
середа, березень 04 // Ukrainian_Ukraine
Unsupported locales: ['Vietnamese_Viet Nam.1258']
Can't encode characters: []Значення усіх lang_country можна також дізнатися із файла модуля locale, використовуючи такий код:
names = locale.locale_alias.keys()
print(names)А тепер отримаємо імена тільки тих локалей, які будуть працювати з функцією setlocale(), доповнивши попередній код:
good_names = [name for name in names if len(name) == 5 and name[2] == '_']
print(good_names)Якщо необхідно отримати значення локалей для конкретної країни, наприклад Франції, доповніть попередній код рядками:
fr = [name for name in good_names if name.startswith('fr')]
print(fr)Список локалей для Франції виявиться таким:
['fr_be', 'fr_ca', 'fr_ch', 'fr_fr', 'fr_lu']9.4. Завдання
9.4.1. Контрольні запитання
-
Відносно чого задається відносний шлях?
-
З чого починається абсолютний шлях?
-
Яке призначення функцій
os.getcwd()іos.chdir()? -
Що позначають імена
.і..? -
Які частини шляху
C:\Users\gt\logging\log12042019.txtпредставляють імена каталогів та ім’я файла? -
Які функціії використовуються для копіювання, перейменування і видалення файлів і каталогів?
-
Що таке «епоха Unix«?
-
Яка функція повертає кількість секунд, які пройшли з моменту початку «епохи Unix»?
-
У чому різниця між об’єктами
datetimeіtimedelta? -
Які інструменти локалізації присутні у
Python?
9.4.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Виведіть на екран повний шлях і список файлів поточного каталогу.
-
Виведіть на екран розмір у байтах будь-якого файла у каталозі.
-
Здійсніть пошук файлів у поточному каталозі за певним шаблоном і виведіть результати на екран.
-
У поточному каталозі вручну створіть два текстові файли, перший з яких містить довільний текст, другий - порожній. Використовуючи функції для роботи з файлами, виконайте такі дії: виконайте копіювання даних з першого файла у другий, зчитайте з другого файла скопійовані дані і виведіть їх на екран, а потім видаліть перший файл.
-
Виведіть на екран поточну дату й час.
-
Виведіть на екран кількість днів і років, які пройшли з початку «епохи Unix». Вважати
1рік =365днів.
9.4.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Запишіть програмно поточні дату й час як рядок у текстовий файл
today.txt. Зчитайте текстовий файлtoday.txtі розмістіть дані у рядкуtoday_string. Розберіть дату з рядкаtoday_stringна складові, використовуючи функції для роботи з датом й часом, і виведіть їх на екран у вигляді повідомлень з пояснюючим текстом. -
Створіть об’єкт
happy, що містить дату вашого народження. Використайте функції для роботи з датою і часом, щоб дізнатися відповіді на такі питання (виведення організуйте в окремий файл у вигляді, на зразок «запитання: відповідь», у окремих рядках):-
"Яка дата вашого народження?"
-
"У який день тижня ви народилися?"
-
"Коли вам буде (або вже було)
13 330днів від народження?"
-
10. Класи
10.1. Об’єкти
Об’єктно-орієнтоване програмування (ООП ) вважається однією з найефективніших методологій створення програмних застосунків.
У об’єктно-орієнтованому програмуванні використовують класи, що описують реально існуючі предмети і ситуації, а потім створюють об’єкти на основі цих описів. При написанні класу визначається загальна поведінка для цілої категорії об’єктів.
При створенні конкретних об’єктів (екземплярів) на основі класів, кожен об’єкт автоматично наділяється загальною поведінкою; після цього можна наділити кожен об’єкт унікальними особливостями на свій вибір.
Об’єктно-орієнтовані мови, такі як C++, Java і Python, використовують класи (для визначення стану, який може зберігатися в об’єкті), і методи (функції для зміни цього стану).
| Клас містить як дані (змінні, які називаються атрибутами), так і функції, які називаються методами. Створення об’єкта на основі класу називається створенням екземпляра класу. Як правило, коли говорять про об’єкти, мають на увазі екземпляри класів. |
В Python майже все є об’єктом. Рядки, словники, функції, файли і цілі числа - все це об’єкти. Є й винятки: ключові слова (наприклад, in) об’єктами не є. Крім того, імена змінних об’єктами також не є, але змінні вказують на об’єкти.
Ви можете написати num = 20, щоб створити об’єкт типу int зі значенням 20, і присвоїти посилання на нього змінній num. І тепер, цілочисельний об’єкт зі значенням 20 може використовувати методи на зразок додавання і множення. Число 9 - це вже інший цілочисельний об’єкт. Це означає, що існує клас Integer, якому належать об’єкти 9 і 20, або інакше, 9 і 20 - це екземпляри класу Integer.
Наприклад, String є вбудованим класом Python, який створює рядкові об’єкти-екземпляри на зразок 'Nairobi' і 'Singapore'. Рядки 'Nairobi' і 'Singapore' мають методи, наприклад, capitalize() і replace().
Python має багато інших вбудованих класів, що дозволяють створювати інші стандартні типи даних, включаючи списки, словники тощо.
Зрозумілою мовою, об’єкти можна вважати іменниками, а їх методи - дієсловами. Об’єкт представляє окрему річ, а його методи визначають, як вона взаємодіє з іншими речами.
10.2. Створення і використання класу
Почнемо з написання простого класу Dog, що представляє собаку - не якусь конкретну, а собаку взагалі.
Що ми знаємо про собак? У них є кличка і вік. Також відомо, що більшість собак вміють сідати і перекочуватися по команді. Ці два види інформації (кличка і вік) і два види поведінки (сидіти і перекочуватися) будуть включені в клас Dog, тому що вони є загальними для більшості собак.
Клас повідомляє Python, як створити об’єкт, який представляє собаку. Після того як клас буде написаний, ми використовуємо його для створення екземплярів, кожен з яких представлятиме одну конкретну собаку.
10.2.1. Створення класу
| Функція, що є частиною класу, називається методом. Практична відмінність між функціями і методами - спосіб виклику методів. |
У кожному екземплярі, створеному на основі класу Dog, буде зберігатися кличка і вік; крім того, у ньому будуть присутні методи sit() і roll_over():
class Dog(): (1)
"""Проста модель собаки.""" (2)
def __init__(self, name, age): (3)
"""Ініціалізація атрибутів name і age."""
self.name = name (4)
self.age = age
def sit(self): (5)
"""Собака сідає по команді."""
print(self.name.title() + " is now sitting.")
def roll_over(self):
"""Собака перекочується по команді."""
print(self.name.title() + " rolled over!")-
Визначається клас з ім’ям
Dog. -
Записано коментар з коротким описом класу.
-
Метод
__init__- спеціальний метод, який автоматично виконується при створенні кожного нового екземпляра на основі класуDog. Цей метод називається конструктором.-
Ім’я методу починається і закінчується двома символами підкреслення.
-
Метод
__init__визначається з трьома параметрами у дужках:self,nameтаage. -
Параметр
selfє обов’язковим у визначенні методу, він повинен бути першим у списку усіх параметрів. -
selfє включеним у визначення методу для того, щоб у майбутньому виклику методу__init__(для створення екземпляра класуDog) автоматично передавався аргументself. -
При кожному виклику методу, пов’язаного з класом, автоматично передається
self- посилання на екземпляр. Посилання надає конкретному екземпляру доступ до атрибутів і методів класу. -
Коли ви створюєте екземпляр класу
Dog,Pythonвикликає метод__init__із класуDog. -
Ми передаємо класу
Dog()кличку та вік в аргументах, значенняselfпередається автоматично (його передавати не потрібно). -
Кожного разу, коли ви захочете створити екземпляр на основі класу
Dog, необхідно надавати значення лише двох останніх аргументівnameіage.
-
-
Кожна із двох змінних має префікс
self.-
Будь-яка змінна з префіксом
selfдоступна для кожного методу у класі, і можна звернутися до цих змінних у кожному екземплярі, створеному на основі класу. -
Конструкція
self.name = nameотримує значення, яке зберігається в параметріname, і зберігає його в зміннуname, яка потім зв’язується зі створюваним екземпляром. -
Процесс також повторюється з
self.age = age. -
Змінні, до яких звертаються через экземпляри, теж називаються атрибутами.
-
-
В класі
Dogтакож визначаються два метода:sit()іroll_over().-
Так як цим методам не потрібна додаткова інформація (кличка або вік), вони визначаються з єдиним параметром
self. -
Екземпляри, які будуть створені пізніше, зможуть викликати ці методи.
-
Поки методи
sit()іroll_over()обмежуються простим виведенням повідомлення про те, що собака сідає або перекочується.
-
10.2.2. Створення екземпляру класу
Можна вважати, що клас - це, свого роду, інструкція по створенню екземплярів. Відповідно, клас Dog - інструкція по створенню екземплярів, які представляють конкретних собак.
Створимо екземпляр, який представляє конкретну собаку, використовуючи клас Dog:
my_dog = Dog('jessie', 5) (1)
print("My dog's name is " + my_dog.name.title() + ".") (2)
print("My dog is " + str(my_dog.age) + " years old.") (3)-
Cтворюється екземпляр собаки з кличкою
jessieі віком5років.-
У процесі обробки цього рядка
Pythonвикликає метод__init__класуDogз аргументами'jessie'і5. -
Метод
__init__створює екземпляр, який представляє конкретну собаку, і присвоєю атрибутамnameіageцього екземпляру передані значення. -
Метод
__init__не містить явної командиreturn, алеPythonавтоматично повертає екземпляр, який представляє собаку. Цей екземпляр зберігається у зміннуmy_dog.
-
Вважається, що ім’я, яке починається з символу верхнього регістра (наприклад, Dog), позначає клас, а ім’я, записане в нижньому регістрі (наприклад, my_dog), позначає окремий екземпляр, створений на основі класу.
|
10.2.3. Доступ до атрибутів
| Для звернення до атрибутів екземпляра використовується крапковий запис. |
-
Звертаються до значення атрибута
nameекземпляраmy_dog:
my_dog.name-
Крапковий запис часто використовується у
Python. Цей синтаксис показує, якPythonшукає значення атрибутів. -
В даному випадку
Pythonзвертається до екземпляруmy_dogі шукає атрибутname, пов’язаний з екземпляромmy_dog. -
Це той самий атрибут, який позначався
self.nameв класіDog.
-
Використовується такий самий прийом для роботи з атрибутом
age.
У першій команді print() виклик:
my_dog.name.title()записує ім’я собаки 'jessie' (значення атрибута name екземпляра my_dog) з великої літери. У другій команді print() виклик:
str(my_dog.age)перетворює 5, значення атрибута age екземпляра my_dog, у рядок. Даний приклад виводить зведену інформацію відомих фактів про my_dog:
My dog's name is Jessie.
My dog is 5 years old.10.2.4. Виклик методів
Після створення екземпляра на основі класу Dog можна застосовувати крапковий запис для виклику будь-яких методів, визначених у Dog.
Щоб викликати метод, вкажіть екземпляр (у даному випадку my_dog) і метод, який викликається, розділивши їх крапкою:
my_dog.sit()
my_dog.roll_over()В ході обробки my_dog.sit() Python шукає метод sit() в класі Dog і виконує його код. Рядок my_dog.roll_over() інтерпретується аналогічним чином. Тепер екземпляр слухняно виконує отримані команди:
Jessie is now sitting.
Jessie rolled over!10.2.5. Створення декількох екземплярів
На основі класу можна створити стільки екземплярів, скільки вам буде потрібно. Створимо другий екземпляр класу Dog з ім’ям your_dog:
my_dog = Dog('jessie', 5)
your_dog = Dog('jack', 2)
print("My dog's name is " + my_dog.name.title() + ".")
print("My dog is " + str(my_dog.age) + " years old.")
my_dog.sit()
print("\nYour dog's name is " + your_dog.name.title() + ".")
print("Your dog is " + str(your_dog.age) + " years old.")
your_dog.roll_over()У цьому прикладі створюються два екземпляри з іменами jessie і jack. Кожен з них має свій набір атрибутів і здатний виконувати дії із загального набору:
My dog's name is Jessie.
My dog is 5 years old.
Jessie is now sitting.
Your dog's name is Jack.
Your dog is 2 years old.
Jack rolled over!10.3. Робота з класами та екземплярами
Класи можуть використовуватися для моделювання багатьох реальних ситуацій. Після того як клас написаний, більшу частина часу витрачається на роботу з екземплярами, створеними на основі цього класу. Однією з перших задач постає зміна атрибутів, пов’язаних з конкретним екземпляром.
Атрибути екземпляра можна змінювати безпосередньо або ж написати методи, які змінюють атрибути за особливими правилами.
Напишемо клас, що описує автомобіль. Цей клас буде містити інформацію про тип машини, а також метод для виведення короткого опису:
class Car():
"""Проста модель автомобіля."""
def __init__(self, make, model, year): (1)
"""Ініціалізація атрибутів опису автомобіля."""
self.make = make
self.model = model
self.year = year
def get_descriptive_name(self): (2)
"""Повертає опис у відформатованому вигляді."""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
my_new_car = Car('citroen', 'c3', 2018) (3)
print(my_new_car.get_descriptive_name())-
В класі
Carвизначається метод__init__.-
Його список параметрів починається з
self, як і у класіDog. -
За ним слідують ще три параметра:
make,modelіyear. -
Метод
__init__отримує ці параметри і зберігає їх в атрибутах, які будуть пов’язані з екземплярами, створеними на основі класу. -
При створенні нового екземпляра класу
Carнеобхідно вказати фірму-виробника, модель і рік випуску для даного екземпляра.
-
-
Визначається метод
get_descriptive_name(), який об’єднує рік випуску, фірму-виробника і модель в один рядок з описом.-
Це дозволяє виводити значення кожного атрибута не окремо, а цілим рядком.
-
Для роботи зі значеннями атрибутів в цьому методі використовується синтаксис
self.make,self.modelіself.year.
-
-
Cтворюється екземпляр класу
Car, який зберігається у зміннуmy_new_car.-
Виклик методу
get_descriptive_name()показує, з яким автомобілем працює програма:
-
2018 Citroen C310.3.1. Присвоювання атрибуту значення за замовчуванням
Кожен атрибут класу повинен мати початкове значення, навіть якщо воно дорівнює 0 або є порожнім рядком. У деяких випадках (наприклад, при встановленні значень за замовчуванням) це початкове значення є сенс ставити в тілі методу __init__. У такому випадку передавати параметр для цього атрибута при створенні об’єкта не обов’язково.
Додамо у клас Car атрибут, що змінюється з часом - пробіг автомобіля в кілометрах.
Додамо у клас атрибут з ім’ям odometer_reading, початкове значення якого завжди дорівнює 0. Також у клас буде включений метод read_odometer() для читання поточних показників одометра :
class Car():
"""Проста модель автомобіля."""
def __init__(self, make, model, year):
"""Ініціалізація атрибутів опису автомобіля."""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0 (1)
def get_descriptive_name(self):
"""Повертає опис у відформатованому вигляді."""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_odometer(self): (2)
"""Виводить пробіг автомобіля у км."""
print("This car has " + str(self.odometer_reading) + " kilometers on it.")
my_new_car = Car('citroen', 'c3', 2018)
print(my_new_car.get_descriptive_name()) (3)
my_new_car.read_odometer() (3)-
Коли
Pythonвикликає метод__init__для створення нового екземпляраmy_new_car, цей метод зберігає фірму-виробника, модель і рік випуску в атрибутах, як і у попередньому випадку. ПотімPythonстворює новий атрибут з ім’ямself.odometer_readingі присвоює йому початкове значення0. -
Також у клас додається новий метод
read_odometer(), який спрощує читання пробігу автомобіля в кілометрах. -
Виклик методів
get_descriptive_name()іread_odometer()для екземпляраmy_new_carдає такі початкові дані для нового автомобіля:
2018 Citroen C3
This car has 0 kilometers on it.10.3.2. Зміна значень атрибутів
Значення атрибута у нашій задачі можна змінити одним з трьох способів:
-
змінити його безпосередньо в екземплярі
-
задати значення або змінити його за допомогою методу
Розглянемо ці способи.
Щоб змінити значення атрибута, найпростіше звернутися до нього через екземпляр. У наступному прикладі на одометрі безпосередньо виставляється значення 120:
my_new_car.odometer_reading = 120
my_new_car.read_odometer()Крапковий запис використовується для звернення до атрибуту odometer_reading екземпляра і безпосереднього присвоєння йому значення. Рядок my_new_car.odometer_reading = 120 вказує Python взяти екземпляр my_new_car, знайти пов’язаний з ним атрибут odometer_reading і задати значення атрибута рівним 120:
2018 Citroen C3
This car has 120 kilometers on it.У клас можна включити методи, які змінюють атрибути. Замість того, щоб змінювати атрибут безпосередньо, ви передаєте нове значення методу, який бере оновлення атрибуту на себе.
У наступному прикладі в кінець класу включається метод update_odometer() для зміни показів одометра:
class Car():
...
def update_odometer(self, km): (1)
"""Встановлення заданого значення на одометрі."""
self.odometer_reading = km
my_new_car = Car('citroen', 'c3', 2018)
print(my_new_car.get_descriptive_name())
my_new_car.update_odometer(150) (2)
my_new_car.read_odometer() (3)-
Клас
Carмайже не змінився, в ньому тільки додався методupdate_odometer(). Цей метод отримує пробіг в кілометрах і зберігає його вself.odometer_reading. -
Викликається метод
update_odometer()і йому передається значення120в аргументі (відповідному параметруkmу визначенні методу). Метод встановлює на одометрі значення120. -
Метод
read_odometer()доповнює інформацію про автомобіль показниками пробігу:
2018 Citroen C3
This car has 150 kilometers on it.Розширимо метод update_odometer(), щоб при кожній зміні показників одометра виконувалася перевірка, яка гарантує, що ніхто не буде намагатися скидати показники одометра:
class Car():
...
def update_odometer(self, km):
"""Встановлення заданого значення на одометрі.
При спробі зменшення пробігу зміна відхиляється."""
if km >= self.odometer_reading: (1)
self.odometer_reading = km
else:
print("You can't roll back an odometer!") (2)
my_new_car = Car('citroen', 'c3', 2018)
my_new_car.update_odometer(130)
my_new_car.read_odometer()
my_new_car.update_odometer(110)-
Тепер
update_odometer()перевіряє нове значення перед зміною атрибута. Якщо нове значенняkmбільше або дорівнює поточномуself.odometer_reading, показники одометра можна оновити новим значенням. -
Якщо ж нове значення менше поточного, ви отримаєте попередження про неприпустимість скидання показників.
2018 Citroen C3
This car has 130 kilometers on it.
You can't roll back an odometer!Іноді, значення атрибута потрібно змінити із вказаним збільшенням (замість того, щоб присвоювати атрибуту довільне нове значення).
Припустимо, ви придбали машину, яка була у вжитку, і проїхали на ній 100 км. Наступний метод отримує величину приросту і додає її до поточних показників одометра:
class Car():
...
def increment_odometer(self, kkm): (1)
"""Збільшує показників одометра із заданим збільшенням."""
self.odometer_reading += kkm
my_used_car = Car('toyota', 'corolla', 2015) (2)
print(my_used_car.get_descriptive_name())
my_used_car.update_odometer(25700) (3)
my_used_car.read_odometer()
my_used_car.increment_odometer(100) (4)
my_used_car.read_odometer()-
Новий метод
increment_odometer()отримує відстань в кілометрахkkmі додає її доself.odometer_reading. -
Cтворюється екземпляр
my_used_car. -
Показники одометра екземпляра
my_used_carвстановлюється у значення25700, для цього викликається методupdate_odometer(), якому передається значення25700. -
Викликається метод
increment_odometer(), якому передається значення100, щоб збільшити показники лічильника шляху на100км, пройдені з моменту придбання автомобіля:
2015 Toyota Corolla
This car has 25700 kilometers on it.
This car has 25800 kilometers on it.10.4. Наслідування
Робота над новим класом не обов’язково повинна починатися з нуля. Якщо клас, який ви пишете, є спеціалізованою версію раніше написаного класу, ви можете скористатися наслідуванням (успадкуванням).
| Клас, що успадковує від іншого, автоматично отримує всі атрибути і методи першого класу. |
Початковий клас називається батьком, а новий клас - нащадком. Клас-нащадок успадковує атрибути і методи батька, але при цьому також може визначати власні атрибути і методи.
Перше, що робить Python при створенні екземпляра класу-нащадка, - додає значення всіх атрибутів класу-батька. Для цього методу __init__ класу-нащадка необхідна допомога з боку класу-батька.
Наприклад, спробуємо побудувати модель електромобіля. Електромобіль передставляє собою спеціалізований різновид автомобіля, тому новий клас ElectricCar (нащадок) можна створити на основі класу Car (батько), написаного раніше. Залишиться лише додати в нащадка код атрибутів і поведінку, що відноситься тільки до електромобілів.
Почнемо із створення простої версії класу ElectricCar, який робить все, що робить клас Car:
class Car(): (1)
"""Проста модель автомобіля."""
def __init__(self, make, model, year):
"""Ініціалізація атрибутів опису автомобіля."""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""Повертає опис у відформатованому вигляді."""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_odometer(self):
"""Виводить пробіг автомобіля у км."""
print("This car has " + str(self.odometer_reading) + " kilometers on it.")
def update_odometer(self, km):
"""Встановлення заданого значення на одометрі.
При спробі зворотного прокручування зміна відхиляється."""
if km >= self.odometer_reading:
self.odometer_reading = km
else:
print("You can't roll back an odometer!")
def increment_odometer(self, kkm):
"""Збільшує показники одометра із заданим збільшенням."""
self.odometer_reading += kkm
class ElectricCar(Car): (2)
"""Представляє аспекти автомобіля, специфічні для електромобілів."""
def __init__(self, make, model, year): (3)
"""Ініціалізує атрибути класу-батька."""
super().__init__(make, model, year) (4)
my_tesla = ElectricCar('tesla', 'model s', 2018) (5)
print(my_tesla.get_descriptive_name())-
Створюється клас
Car. При створенні класу-нащадка клас-батько повинен бути частиною поточного файла, а його визначення повинно передувати визначення класу-нащадка у файлі. -
Визначається клас-нащадок
ElectricCar. У визначенні нащадка ім’я класу-батька записується у круглих дужках. -
Метод
__init__отримує інформацію, необхідну для створення екземпляраCar. -
Функція
super()- спеціальна функція, яка допомагаєPythonзв’язати нащадка з батьком.-
Цей рядок вказує
Pythonвикликати метод__init__класу, який є батькомElectricCar, в результаті чого екземпляр класуElectricCarотримує всі атрибути класу-батька. -
Ім’я
superвиходить з такої термінології: клас-батько називається суперкласом, а клас-нащадок - субкласом.
-
-
Щоб перевірити, чи правильно спрацювало наслідування, спробуємо створити електромобіль з такою ж інформацією, яка передається при створенні звичайного екземпляра
Car.-
Cтворюємо екземпляр класу
ElectricCarі зберігаємо його у зміннуmy_tesla. -
Цей рядок викликає метод
__init__, який визначений у класіElectricCar, який в свою чергу вказуєPythonвикликати метод__init__, визначений в класі-батькаCar. -
При виклику передаються аргументи
'tesla','model s'і2018. -
Крім
__init__клас ще не містить ніяких атрибутів або методів, специфічних для електромобілів. -
Поки ми просто переконуємося в тому, що клас електромобіля містить всю поведінку, властиву класу звичайного автомобіля:
-
2018 Tesla Model SПісля створення класу-нащадка, який успадковує все від класу-батька, можна переходити до додавання нових атрибутів і методів, необхідних для того, щоб нащадок відрізнявся від батька.
Додамо атрибут, специфічний для електромобілів (наприклад, потужність акумулятора), і метод для виведення інформації про цей атрибут:
class Car():
...
class ElectricCar(Car):
"""Представляє аспекти автомобіля, специфічні для електромобілів."""
def __init__(self, make, model, year):
"""Ініціалізує атрибути класу-батька.
Потім ініціалізує атрибути, специфічні для електромобіля."""
super().__init__(make, model, year)
self.battery_size = 70 (1)
def describe_battery(self): (2)
"""Виводить інформацію про потужність акумулятора."""
print("This car has a " + str(self.battery_size) + "-kWh battery.")
my_tesla = ElectricCar('tesla', 'model s', 2018)
print(my_tesla.get_descriptive_name())
my_tesla.describe_battery() (3)-
Додається новий атрибут
self.battery_size, якому присвоюється початкове значення - скажімо,70. Цей атрибут буде присутній у всіх екземплярах, створених на основі класуElectricCar(але не у всякому екземпляріCar). -
Також додається метод з ім’ям
describe_battery(), який виводить інформацію про акумулятор. -
При виклику методу
describe_battery()виводиться опис, який явно відноситься тільки до електромобілів:
2018 Tesla Model S
This car has a 70-kWh battery.Можливості спеціалізації класу ElectricCar безмежні. Ви можете додати скільки завгодно атрибутів і методів, щоб моделювати електромобіль з будь-якими властивостями.
Атрибути або методи, які можуть належати будь-якій машині (а не тільки електромобілю), повинні додаватися до класу Car. Тоді ця інформація буде доступна всім користувачам класу Car, а клас ElectricCar буде містити тільки інформацію і поведінку, специфічні для електромобілів.
10.5. Перевизначення методу
Будь-який метод батьківського класу, який в конкретній ситуації робить не те, що потрібно, можна перевизначити.
Для цього в класі-нащадку визначається метод з тим же ім’ям, що і у методі класу-батька. Python ігнорує метод у класі батька і звертає увагу тільки на метод, визначений в нащадку.
Припустимо, в класі Car є метод fill_petrol_tank(). Для електромобілів заправка бензином безглузда, тому цей метод логічно перевизначити. Наприклад, це можна зробити так:
class Car():
...
def fill_petrol_tank(self):
"""Виводить інформацію про наяність бака для бензину."""
print("This car is equipped with a petrol tank.")
class ElectricCar(Car):
...
def fill_petrol_tank(self):
"""У електромобілів немає бензобаку."""
print("This car doesn't need a petrol tank!")
my_new_car = Car('citroen', 'c3', 2018)
print(my_new_car.get_descriptive_name())
my_new_car.fill_petrol_tank() (1)
my_tesla = ElectricCar('tesla', 'model s', 2018)
print(my_tesla.get_descriptive_name())
my_tesla.fill_petrol_tank() (2)-
Якщо викликати метод
fill_petrol_tank()для звичайного автомобіля з бензобаком,Pythonвикличе методfill_gas_tank()класуCar. -
Якщо хтось спробує викликати метод
fill_petrol_tank()для електромобіля,Pythonпроігнорує методfill_gas_tank()класуCarта виконає замість нього код із методаfill_gas_tank()класуElectricCar:
2018 Citroen C3
This car is equipped with a petrol tank.
2018 Tesla Model S
This car doesn't need a petrol tank!| Із застосуванням наслідування нащадок зберігає ті аспекти батька, які вам потрібні, і перекриває все непотрібне. |
10.6. Екземпляри як атрибути
При моделюванні явищ реального світу у програмах класи нерідко доповнюють все більшою кількістю подробиць. Списки атрибутів і методів ростуть, і через якийсь час файли стають громіздкими.
У такій ситуації частину одного класу нерідко можна записати у вигляді окремого класу. Великий код розбивається на менші класи, які працюють у взаємодії один з одним.
Наприклад, при подальшій доробці класу ElectricCar може виявитися, що в ньому з’явилося занадто багато атрибутів і методів, що відносяться до акумулятора. В такому випадку можна зупинитися і перемістити всі ці атрибути і методи в окремий клас з ім’ям Battery. Таким чином, екземпляр Battery стає атрибутом класу ElectricCar.
class Car():
...
class Battery(): (1)
"""Проста модель акумулятора електромобіля."""
def __init__(self, battery_size=70): (2)
"""Ініціалізує атрибути акумулятора."""
self.battery_size = battery_size
def describe_battery(self): (3)
"""Виводить інформацію про потужність акумулятора."""
print("This car has a " + str(self.battery_size) + "-kWh battery.")
class ElectricCar(Car):
"""Представляє аспекти автомобіля, специфічні для електромобілів."""
def __init__(self, make, model, year):
"""Ініціалізує атрибути класу-батька.
Потім ініціалізує атрибути, специфічні для електромобіля."""
super().__init__(make, model, year)
self.battery = Battery() (4)
def fill_petrol_tank(self):
"""У електромобілів немає бензобаку."""
print("This car doesn't need a petrol tank!")
my_tesla = ElectricCar('tesla', 'model s', 2018) (5)
print(my_tesla.get_descriptive_name())
my_tesla.battery.describe_battery() (6)-
Визначається новий клас з ім’ям
Battery, який не буде наслідувати ні від одного з інших класів. -
Метод
__init__отримуєselfі один параметр за замовчуваннямbattery_size. Якщо значення не надано, цей параметр за замовчуванням задаєbattery_sizeзначення70. -
Метод
describe_battery()також переміщений у класBattery. -
Потім в клас
ElectricCarдодається атрибут з ім’ямself.battery.-
Цей рядок вказує
Pythonстворити новий екземплярBattery(зі значеннямbattery_sizeза замовчуванням, рівним70, тому що значення не задано) і зберегти його в атрибутіself.battery. -
Це буде відбуватися при кожному виклику
__init__і будь-який екземплярElectricCarматиме автоматично створюваний екземплярBattery.
-
-
Програма створює екземпляр електромобіля і зберігає його у змінній
my_tesla. -
Коли буде потрібно вивести опис акумулятора, необхідно звернутися до екземпляра
my_tesla, знайти атрибутbatteryі викликати методdescribe_battery(), який зв’язаний з екземпляромBatteryіз атрибуту:
2018 Tesla Model S
This car has a 70-kWh battery.Здавалося б, новий варіант програми вимагає великої додаткової роботи, але тепер акумулятор можна моделювати з будь-яким ступенем деталізації без збільшення громіздкості класу ElectricCar. Додамо у клас Battery ще один метод, який виводить запас ходу на підставі потужності акумулятора:
class Car():
...
class Battery():
...
def get_range(self): (1)
"""Виводить приблизний запас ходу для акумулятора."""
if self.battery_size == 70:
range = 240
elif self.battery_size == 85:
range = 270
message = "This car can go approximately " + str(range)
message += " kilometers on a full charge."
print(message)
class ElectricCar(Car):
...
my_tesla = ElectricCar('tesla', 'model s', 2018)
print(my_tesla.get_descriptive_name())
my_tesla.battery.describe_battery()
my_tesla.battery.get_range() (2)-
Новий метод
get_range()проводить простий аналіз.-
Якщо потужність дорівнює
70, тоget_range()встановлює запас ходу240км, а при потужності85kWh запас ходу дорівнює270км. -
Потім програма виводить це значення.
-
-
Коли ви захочете використовувати метод
get_range(), його доведеться викликати через атрибутbattery.
Результат повідомляє запас ходу автомобіля в залежності від потужності акумулятора:
2018 Tesla Model S
This car has a 70-kWh battery.
This car can go approximately 240 kilometers on a full charge.Використовування класів у своїх програмах спрямовує представляти у коді реальний світ, мислити на більш високому логічному рівні, не обмежуючись рівнем синтаксису.
10.7. Завдання
10.7.1. Контрольні запитання
Дайте пояснення таких понять у Python:
-
об’єкт
-
клас
-
екземпляр класу
-
метод класу
-
атрибут класу
-
наслідування
-
перевизначення методу
-
екземпляри як атрибути
10.7.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Створіть клас, який називається
SportResults, який не має вмісту, і виведіть його на екран. Потім створіть екземплярdivingцього класу і також виведіть його. Чи збігаються виведені значення? -
У клас
SportResultsдодайте зміннуpointsзі значенням25і виведіть на екран значення атрибутуpointsдля екземпляруdiving. А потім надайте значення150дляpoints. Знову виведіть на екран значення атрибутуpointsдля екземпляруdiving. Чи потрібно було створювати новий екземпляр класу, щоб зробити повторне виведення? -
Створіть клас, який називається
Element, з методом__init__, що має атрибути екземпляруname,symbolіnumber. Створіть екземпляр цього класуelзі значеннями'Silicium','Si'і14і виведіть на екран значення його атрибутів. -
Створіть словник з наступними ключами і значеннями:
'name': 'Argentum', 'symbol': 'Ag', 'number': 47. Далі створіть екземпляр з ім’ямargentumкласуElementза допомогою цього словника і виведіть значення усіх атрибутів. -
Для класу
Elementвизначте метод з ім’ямdump(), який виводить на екран значення атрибутів екземпляру (name,symbolіnumber). Створіть екземплярargentumз цього нового визначення і використайте методdump(), щоб вивести на екран його атрибути. -
Визначте три класи:
Switzerland,EnglandіJapan. Для кожного з них визначте всього один метод -currency(). Метод повинен повертати значення'franc'(дляSwitzerland),'pound'(дляEngland) або'yen'(дляJapan). Створіть по одному екземпляру кожного класу і виведіть на екран грошову одиницю кожної країни. -
Визначте три класи:
Printer,LampіCar. Кожен з них має тільки один методdoes(). Він повертає значення'print'(дляPrinter),'glow'(дляLamp) або'ride'(дляCar). Далі визначте класRobotз методом__init__, який містить по одному екземпляру кожного з цих класів як власні атрибути. Визначте методdo_it()для класуRobot, який виводить на екран усі дії, що роблять його компоненти.
10.7.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Онлайн-магазин.
-
Створіть клас з ім’ям
Shop(). Метод__init__()класуShop()повинен містити два атрибути:shop_nameіstore_type. Створіть методdescribe_shop(), який виводить два атрибути, і методopen_shop(), який виводить повідомлення про те, що онлайн-магазин відкритий. Створіть на основі класу екземпляр з ім’ямstore. Виведіть два атрибути окремо, потім викличте обидва методи. -
Створіть три різних екземпляри класу, викличте для кожного екземпляру метод
describe_shop(). -
Додайте атрибут
number_of_unitsзі значенням за замовчуванням0; він представляє кількість видів товару у магазині. Створіть екземпляр з ім’ямstore. Виведіть значенняnumber_of_units, а потім змінітьnumber_of_unitsі виведіть знову. -
Додайте метод з ім’ям
set_number_of_units(), що дозволяє задати кількість видів товару. Викличте метод з новим числом, знову виведіть значення. Додайте метод з ім’ямincrement_number_of_units(), який збільшує кількість видів товару на задану величину. Викличте цей метод. -
Напишіть клас
Discount(), що успадковує від класуShop(). Додайте атрибут з ім’ямdiscount_productsдля зберігання списку товарів, на які встановлена знижка. Напишіть методget_discounts_ptoducts, який виводить цей список. Створіть екземплярstore_discountі викличте цей метод. -
Збережіть код класу
Shop()у модулі. Створіть окремий файл, що імпортує класShop(). Створіть екземплярall_storeі викличте один з методівShop(), щоб перевірити, що командаimportпрацює правильно.
-
-
Облік користувачів на сайті.
-
Створіть клас з ім’ям
User. Створіть два атрибутиfirst_nameіlast_name, а потім ще кілька атрибутів, які зазвичай зберігаються у профілі користувача. Напишіть методdescribe_userякий виводить повне ім’я користувача. Створіть ще один методgreeting_user()для виведення персонального вітання для користувача. Створіть кілька примірників, які представляють різних користувачів. Викличте обидва методи для кожного користувача. -
Додайте атрибут
login_attemptsу класUser. Напишіть методincrement_login_attempts(), що збільшує значенняlogin_attemptsна1. Напишіть інший метод з ім’ямreset_login_attempts(), обнуляє значенняlogin_attempts. Створіть екземпляр класуUserі викличтеincrement_login_attempts()кілька разів. Виведіть значенняlogin_attempts, щоб переконатися у тому, що значення було змінено правильно, а потім викличтеreset_login_attempts(). Знову виведітьlogin_attemptsі переконайтеся у тому, що значення обнулилося. -
Адміністратор - користувач з повними адміністративними привілеями. Напишіть клас з ім’ям
Admin, що успадковує від класуUser. Додайте атрибутprivilegesдля зберігання списку рядків виду«Allowed to add message»,«Allowed to delete users»,«Allowed to ban users»і т. д. Напишіть методshow_privileges()для виведення набору привілеїв адміністратора. Створіть екземплярAdminі викличте метод. -
Напишіть клас
Privileges. Клас повинен містити всього один атрибутprivilegesзі списком, який треба забрати із класуAdmin. Водночас, необхідно перемістити методshow_privileges()у класPrivilegesіз класуAdmin. Створіть екземплярprivяк атрибут класуAdmin. Створіть новий екземплярadminі використайте метод для виведення списку привілеїв. -
Збережіть клас
Userв одному модулі, а класиPrivilegesіAdminу іншому модулі. В окремому файлі створіть екземплярadminі викличте методshow_privileges(), щоб перевірити, що все працює правильно.
-
11. Робота з даними
11.1. Текстові дані
11.1.1. ASCII
У 60-х роках XX століття в американському національному інституті стандартизації (ANSI ) була розроблена таблиця кодування символів, яка згодом була використана у всіх операційних системах.
Ця таблиця називається ASCII (від англ. American Standard Code for Information Interchange), що означає Американський стандартний код для обміну інформацією. Трохи пізніше з’явилася розширена версія ASCII.
У відповідності з таблицею кодування ASCII для подання одного символу виділяється 1 байт (8 біт). Набір з 8 біт може зберегти
28 = 256різних значень.
Перші 128 значень (від 0 до 127) постійні і формують так звану основну частину таблиці, куди входять десяткові цифри, букви латинського алфавіту (великі і малі), розділові знаки (крапка, кома, дужки і ін.), а також пропуск і різні службові символи (табуляція, перенесення рядка і ін.).

Наприклад, код ASCII для великої англійської літери M становить 77. Це означає, що коли ви натискаєте клавішу з великою літерою M на клавіатурі комп’ютера, число 77 зберігається в пам’яті як бінарне число 01001101).
Значення від 128 до 255 формують додаткову частину таблиці, де прийнято кодувати символи національних алфавітів.
Таке кодування нормально працює в середовищах, орієнтованих на латинський алфавіт, - наприклад, в англійській мові. На жаль, у світі існує більше букв, ніж надає формат ASCII.
Оскільки національних алфавітів надзвичайно багато, то існують розширені ASCII-таблиці у різних варіантах. Це створює додаткові труднощі у відображенні символів, наприклад, при використанні одночасно різних схем кодування.
Було зроблено багато спроб додати більше букв і символів, і час від часу з’являлись різні системи, на зразок:
-
Windows-1252 -
Latin-1абоISO 8859-1
11.1.2. Unicode
У 1991 році був створений стандарт кодування символів Unicode (від англ. Unicode, УНІфіковане КОДування) - промисловий стандарт, розроблений для забезпеченння цифрового представлення символів усіх писемностей світу та спеціальних символів.
Таблиця символів Unicode знімає обмеження на кодування символів лише одним байтом. Натомість, використовується 17 просторів, кожен з яких визначає 65536 кодів і дає можливість описати максимум
17 · 216 = 1 114 112різних символів.
Рядки у Python 3 є рядками формату Unicode, а не масивом байтів.
|
| Unicode - це діючий міжнародний стандарт, який визначає символи усіх мов світу і багато інших символів. |
Unicode надає унікальний номер для кожного символу незалежно від платформи, програми і мови. Підтримка Unicode є основою для представлення мов і символів у всіх основних операційних системах, пошукових системах, браузерах, ноутбуках і смартфонах, а також в Інтернеті та World Wide Web (URL, HTML, XML, CSS, JSON тощо).
У Python вбудовані функції для роботи з символами і їхніми номерами в Unicode:
-
ord()- якщо рядок представляє один символUnicode, функція повертає ціле число - кодUnicodeцього символу. Наприклад,ord('a')повертає ціле число97таord('€')(символ Євро) повертає8364. -
chr()- повертає рядок у вигляді символу, за його кодом вUnicode. Наприклад,chr(97)повертає рядок'a', аchr(8364)повертає рядок'€'.
| Сторінка Unicode Code Charts містить посилання на всі визначені на даний момент набори символів з їхніми зображеннями. |
Кожен із символів у форматі Unicode має унікальне ім’я та ідентифікаційний номер (код). Якщо ви знаєте Unicode ID або назву символу, то можете використовувати його у рядку Python згідно таких правил:
-
Символ
\u, за яким розташовуються чотири шістнадцяткові числа (числа шістнадцяткової системи числення , що містять символи від0до9і відAдоF), визначають символ, що знаходиться в одній із багатомовних площин Unicode .-
Перші два числа є номером площини (від
00доFF), а наступні два - кодом символу всередині площини. -
Площина з номером
00- це старий форматASCII, і позиції символів у ньому такі ж, як і уASCII.
-
Отже, якщо код символу має 4 цифри і менше, необхідно використовувати малу літеру \u і доповнювати код зліва нулями до 4 цифр.
Наприклад, код символу @ має шістнадцяткове значення 40 у таблиці символів Unicode , тому необхідно дописати два 0 попереду, щоб кількість цифр стала рівною 4, і для використання у Python використовувати символ \u:
at = '\u0040'
print(at)Результат:
@-
Для символів вищих площин потрібно більше бітів.
-
Керуюча послідовність для них виглядає як
\U, за яким слідують вісім шістнадцяткових символів. -
Крайній зліва з них має дорівнювати
0.
-
Отже, якщо код символу містить більше 4 цифр, необхідно використовувати велику літеру U і доповнити код символу зліва нулями до 8 цифр. Наприклад, код символу 😗 має шістнадцяткове значення 1F617 у таблиці символів Unicode , тому необхідно дописати три 0 попереду, щоб кількість цифр стала рівною 8, і для використання у Python використовувати символ \U:
kissing_face = '\U0001F617'
print(kissing_face)Результат:
😗-
Для усіх символів конструкція
\N{character_name}дозволяє вказати символ за допомогою стандартного імені символа .
У Python входить модуль unicodedata, що містить функції, які перетворюють символи в обох напрямках:
-
lookup()приймає незалежне від регістру ім’я і повертає символUnicode -
name()приймає символUnicodeі повертає його ім’я у верхньому регістрі
У наступному прикладі напишемо функцію для перевірки, яка приймає рядок із символом Unicode, шукає його ім’я, а потім шукає символ, який відповідає отриманому імені (результат повинен збігтися з оригінальним). Спробуємо перевірити літеру і розділовий знак у форматі ASCII:
import unicodedata
def unicode_test(value):
name_unicode = unicodedata.name(value)
other_value = unicodedata.lookup(name_unicode)
return 'value="{0:s}", name_unicode="{1:s}", other_value="{2:s}"'.format(value, name_unicode, other_value)Результати перевірки будуть наступними:
value="P", name_unicode="LATIN CAPITAL LETTER P", other_value="P"
value="!", name_unicode="EXCLAMATION MARK", other_value="!"А тепер застосуємо функцію до кількох рядків, що містять символи у форматі Unicode (символи валютних знаків '\u00a2', '\u20ac' і '\u20B4'):
print(unicode_test('\u00a2'))
print(unicode_test('\u20ac'))
print(unicode_test('\u20B4'))Результати роботи функції є наступними:
value="¢", name_unicode="CENT SIGN", other_value="¢"
value="€", name_unicode="EURO SIGN", other_value="€"
value="₴", name_unicode="HRYVNIA SIGN", other_value="₴"Проблемою, з якою можна зіткнутися, працюючи із символами Unicode, є обмеження, які накладаються шрифтом. У жодному шрифті немає символів для усіх символів Unicode.
Припустимо, ми хочемо зберегти у рядку французьку назву місяця серпень - слово août. Одне з рішень: скопіювати назву з файла або з сайту, де це слово записано вже у такому вигляді
month = 'août'
print(month)і сподіватися, що це спрацює:
août
Символ над літерою u називається циркумфлексом .
|
Але як вказати, що передостанній символ - це û?
Якщо подивитися на код символа «U» , можна побачити, що повне ім’я символа U WITH CIRCUMFLEX, LATIN SMALL LETTER має код 00FB.
Розглянемо знову функції name() і lookup() із модуля unicodedata. Спочатку передамо код символу
import unicodedata
print(unicodedata.name('\u00FB'))щоб отримати його повне ім’я, але у зміненому вигляді:
LATIN SMALL LETTER U WITH CIRCUMFLEXДля отриманого повного імені
print(unicodedata.lookup('LATIN SMALL LETTER U WITH CIRCUMFLEX'))знайдемо справжнє ім’я в Unicode:
ûТепер символ û можна використовувати як
import unicodedata
month = 'ao\u00FBt'
print(month)
month = 'ao\N{LATIN SMALL LETTER U WITH CIRCUMFLEX}t'
print(month)із допомогою коду символу, так і завдяки повному імені:
août
août11.1.3. UTF-8
Unicode має декілька реалізацій, з яких найпоширенішою є UTF (Unicode Transformation Format) - Формат Перетворення Юнікоду.
У різних стандартах кодувань після назви UTF вказується число, що визначає кількість бітів, що виділяються під один символ.
UTF-8 - динамічна схема кодування, що використовує для символу Unicode від одного до чотирьох байтів:
-
один байт для
ASCII-символів -
два байта для більшості мов, заснованих на латиниці (але не кирилиці)
-
три байта для інших простих мов
-
чотири байти для решти мов, включаючи деякі азіатські мови і символи
UTF-8 - поширене сьогодні кодування, що реалізовує представлення Unicode, сумісне з 8-бітовим кодуванням тексту.
|
UTF-8 для кодування символів використовує від 1 до 4 байтів на символ. Так, перший байт UTF-8 можна використовувати для кодування ASCII, що дає повну сумісність з кодами ASCII.
Простіше кажучи, у форматі UTF-8 символи латинського алфавіту, розділові знаки і керуючі символи ASCII, записуються ASCII-кодами, а решта усіх символів кодується за допомогою послідовностей завдовжки 8 біт із старшим бітом 1.
Кодування UTF-8 дозволяє працювати в стандартизованому міжнародно прийнятому багатомовному середовищі, з порівняно незначним збільшенням обсягу даних при кодуванні.
UTF-8 - це стандартне текстове кодування для Python, Linux і HTML.
|
Якщо ви створюєте рядок Python шляхом копіювання символів з іншого джерела, на зразок веб-сторінки, і їх вставки, переконайтеся, що джерело було закодоване за допомогою UTF-8. Дуже часто може виявитися, що текст був закодований за допомогою систем Latin-1, Windows-1252 та інших, і при копіюванні у рядок Python викличе генерацію винятків через некоректні послідовності байтів.
|
11.1.4. Кодування
Рядок у форматі Unicode кодується байтами за допомогою функції encode() у байтовий рядок. Перший аргумент цієї функції - назва кодування. Деякі види кодувань наведені у таблиці:
|
Cемибітне кодування |
|
Восьмибітне кодування змінної довжини, кращий варіант у більшості випадків |
|
Також відома як |
|
Стандартне кодування |
|
Буквенний формат |
Спробуємо використати кодування UTF-8. Присвоємо рядок '\u2615', записаний у Unicode, змінній cup.
cup - це рядок Python у кодуванні Unicode, що містить один символ незалежно від того, скільки байтів потрібно для зберігання цього рядка:
cup = '\u2615'
print(len(cup)) # 1Закодуємо cимвол '\u2615' послідовністю байтів:
cup = '\u2615'
result = cup.encode('utf-8')
print(len(result))
print(result)Кодування UTF-8 має змінну довжину. У нашому випадку було використано три байта для того, щоб закодувати один символ cup
3
b'\xe2\x98\x95'Функція len() повернула кількість байтів (3), оскільки result є змінною типу bytes, про що свідчить на початку рядка символ b.
Можна використовувати і інші кодування, не лише UTF-8, але коли інше кодування не зможе обробити рядок Unicode, з’явиться помилка.
Наприклад, якщо для нашого випадку використати кодування ASCII
cup = '\u2615'
result = cup.encode('ascii')
print(result)у нас нічого не вийде, оскільки рядок складається з некоректних символів для ASCII:
...
UnicodeEncodeError: 'ascii' codec can't encode character '\u2615' in position 0: ordinal not in range(128)Якщо зустрічається символ, що не входить у кодування ASCII, викликається виняток UnicodeEncodeError.
Функція encode() приймає другий аргумент, який допомагає перехопити виникнення помилок, пов’язаних з кодуванням. Цей аргумент може мати значення:
-
ignore- не враховуються ті символи, які не можуть бути закодовані:
cup = '\u2615'
result = cup.encode('ascii', 'ignore')
print(result)Результатом буде порожній байтовий рядок, оскільки усі символи рядка '\u2615' у форматі Unicode були проігноровані, тому що не можуть бути закодовані в ASCII:
b''-
replace- невідомі символи будуть замінені символами?:
cup = '\u2615'
result = cup.encode('ascii', 'replace')
print(result)Результат:
b'?'-
backslashreplace- невідомі символи будуть замінені на символи, начебто цеunicode-escape:
cup = '\u2615'
result = cup.encode('ascii', 'backslashreplace')
print(result)Результат:
b'\\u2615'
Такий варіант можна використовувати, якщо потрібно надрукувати екрановані послідовності Unicode.
|
-
xmlcharrefreplace- створюються рядки символьних сутностей, які можна зустріти на веб-сторінках:
cup = '\u2615'
result = cup.encode('ascii', 'xmlcharrefreplace')
print(result)Результат:
b'☕'11.1.5. Декодування
Коли ми отримуємо текст з якогось зовнішнього джерела (файли, бази даних, сайти тощо), він закодований у вигляді байтового рядка. Щоб декодувати байтовий рядок і отримати рядок Unicode необхідно застосувати кодування, яке було використано для створення байтового рядка.
Байтові рядки декодуються у рядки Unicode.
|
Але ніяка частина байтового рядка не говорить нам про те, яке кодування було використано.
Створимо рядок у форматі Unicode, який має значення 'résumé' (резюме з французької мови) і зберігається у змінній placement. Якщо подивитися на код символа «E» , можна побачити, що повне ім’я символа E WITH ACUTE, LATIN SMALL LETTER має код 00E9. Замінимо усі входження цього символа в рядку на його код
placement = 'r\u00E9sum\u00E9'
print(placement)
print(type(placement))і отримаємо у результаті рядок у форматі Unicode:
résumé
<class 'str'>Закодуємо рядок placement (перетворимо у рядок байтів) у форматі UTF-8 і збережемо у змінну placement_bytes, яка є типу bytes:
placement = 'r\u00E9sum\u00E9'
placement_bytes = placement.encode('utf-8')
print(placement_bytes)
print(len(placement_bytes))
print(type(placement_bytes))Отримаємо наступний результат:
b'r\xc3\xa9sum\xc3\xa9'
8
<class 'bytes'>Зверніть увагу на те, що змінна placement_bytes містить вісім байтів:
-
r,s,u,m- це символиASCII(один символ -1байт, загалом4байти) -
\xc3і\xa9- це байти, які кодують символé(по2байти на кожний символé, загалом4байти)
Тепер декодуємо цей байтовий рядок назад у рядок Unicode:
other_placement = placement_bytes.decode('utf-8')
print(other_placement)У такому перетворенні все пройшло без проблем, оскільки ми закодували і декодували рядок за допомогою кодування UTF-8:
résuméЩо відбудеться, якщо вказати іншу схему кодування для декодувавання?
another_placement = placement_bytes.decode('ascii')
print(another_placement)Результат:
...
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 1: ordinal not in range(128)Декодер ASCII згенерував виняток, оскільки байтовое значення 0xc3 некоректне у ASCII.
Існують й інші восьмибітні кодування, на зразок ASCII, де значення між 128 (80 в шістнадцятковій системі) і 255 (FF у шістнадцятковій системі) коректні, але не збігаються зі значеннями із UTF-8:
placement_latin1 = placement_bytes.decode('latin-1')
print(placement_latin1)
placement_win1251 = placement_bytes.decode('windows-1251')
print(placement_win1251)
placement_win1252 = placement_bytes.decode('windows-1252')
print(placement_win1252)
placement_cp866 = placement_bytes.decode('cp866')
print(placement_cp866)Результати декодування:
résumé
rГ©sumГ©
résumé
r├йsum├й
Кодування UTF-8 охоплює багато символів, тому варто використовувати його у своєму коді усюди, де це можливо.
|
11.2. Регулярні вирази
Для текстового пошуку ми часто користуємось відомим сполученням клавіш Ctrl+F. Регулярні вирази дозволяють задавати шаблон для тексту, який хочуть знайти.
Механізм регулярних виразів реалізований у стандартному модулі re, який необхідно імпортувати. Спочатку визначається рядок-шаблон, співпадіння з яким потрібно знайти, а потім рядок-джерело, у якому слід виконати пошук.
Простий приклад використання виглядає так:
результат = re.match(шаблон, джерело)
Функція match() перевіряє, чи починається джерело з шаблону.
Для більш складних перевірок необхідно скомпілювати шаблон, щоб прискорити пошук:
патерн = re.compile(шаблон)
| Патерн - шаблон, зразок. |
Далі виконується перевірка за допомогою скомпільованого шаблону:
результат = патерн.match(джерело)
Крім функції match(), порівняти шаблон і джерело можна за допомогою ще кількох функцій:
-
search()- повертає перший збіг, якщо такий є -
findall()- повертає список усіх збігів, які не перетинаються один з одним, якщо такі є
Чи починається рядок 'Thank\'s for your help!', що міститься у змінній source, зі слова 'Thank\'s'? Розглянемо приклад коду:
import re
source = 'Thank\'s for your help!'
find = re.match('Thank\'s', source)
if find:
print(find.group())Відповідь буде позитивною:
Thank'sУ випадку шаблону help
import re
source = 'Thank\'s for your help!'
find = re.match('help', source)
if find:
print(find.group())функція match() нічого не поверне, тому що шаблон знаходиться не на початку джерела. А от функція search() шукає шаблон у будь-якому місці джерела:
import re
source = 'Thank\'s for your help!'
find = re.search('help', source)
if find:
print(find.group())
find = re.match('.*help', source)
if find:
print(find.group())Новий шаблон працює таким чином:
-
символ
.означає будь-який один символ -
символ
*означає будь-яку кількість символів
help
Thank's for your helpУ попередніх прикладах здійснювався пошук тільки одного співпадіння. Якщо необхідно дізнатися скілька разів шаблон входить у джерело, використовують функцію findall():
import re
source = 'Thank\'s for your help!'
find = re.findall('h', source)
print(find)
print('Found:', len(find), 'matches')Шаблон у вигляді символа h зустрічається у рядку-джерелі 'Thank\'s for your help!' два рази:
['h', 'h']
Found: 2 matchesВикористовуючи рядок-шаблон можна перетворити рядок-джерело
import re
source = 'Thank\'s for your help!'
find = re.split('h', source)
print(find)у список:
['T', "ank's for your ", 'elp!']Використовуючи функцію sub()
import re
source = 'Thank\'s for your help!'
find = re.sub('h', '?', source)
print(find)можна виконати заміну у рядку-джерелі, якщо у ньому знайшлось співпадіння з шаблоном:
T?ank's for your ?elp!При створенні регулярних виразів крім звичайних символів (.) , (*), (?), використовують спеціальні символи.
| Шаблон | Співпадіння |
|---|---|
|
цифровий символ |
|
нецифровий символ |
|
буквенний або цифровий символ або знак підкреслення |
|
будь-який символ, крім буквенного або цифрового символа або знака підкреслення |
|
символи пропусків |
|
символи, крім символів пропусків |
|
межа слова |
|
не межа слова |
Модуль Python string містить заздалегідь певні рядкові константи, які ми можемо використовувати для експериментів з регулярними виразами. Скористаємося константою printable
import string
typing_characters = string.printable
print(len(typing_characters))
print(repr(typing_characters[:50]))
print(repr(typing_characters[50:]))яка містить 100 друкованих символів ASCII, включаючи літери в обох регістрах, цифри, пропуски та знаки пунктуації:
100
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMN'
'OPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'Які символи рядка typing_characters є цифрами?
import string
import re
typing_characters = string.printable
result = re.findall('\d', typing_characters)
print(result)Відповідь:
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']Які символи рядка typing_characters є цифрами, буквами і знаком підкреслення?
import string
import re
typing_characters = string.printable
result = re.findall('\w', typing_characters)
print(result)Відповідь:
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '_']Які символи рядка typing_characters є символами пропусків?
import string
import re
typing_characters = string.printable
result = re.findall('\s', typing_characters)
print(result)Відповідь:
[' ', '\t', '\n', '\r', '\x0b', '\x0c']Регулярні вирази не обмежуються символами ASCII. У наступній перевірці використаємо шаблон \w (шукає букви або цифри або знак підкреслення) і додамо наступні символи:
-
п’ять букв
ASCII -
три розділового знака, які не повинні співпасти з шаблоном
\w -
символ
Unicode:A WITH CIRCUMFLEX, LATIN SMALL LETTER(\u00E2) -
символ
Unicode:A WITH BREVE, LATIN SMALL LETTER(\u0103)
import re
search_string = 'email' + '!?,' + '\u00E2' + '\u0103'
result = re.findall('\w', search_string)
print(resultЯк і очікувалося, цей шаблон знайшов тільки букви:
['e', 'm', 'a', 'i', 'l', 'â', 'ă']При створенні регулярних виразів використовують специфікатори шаблонів.
| Шаблон | Співпадіння |
|---|---|
|
буквосполучення |
|
|
|
|
|
будь-який символ, крім |
|
початок рядка |
|
кінець рядка |
|
нуль або одне включення |
|
нуль або більше включень |
|
нуль або більше включень |
|
одне або більше включень |
|
одне або більше включень |
|
|
|
від |
|
від |
|
|
|
не ( |
|
|
|
|
|
|
|
|
Для початку, імпортуємо модуль re і визначимо рядок-джерело для наших експерементів з регулярними виразами (слова Charles Babbage ):
import re
source = '''I have been asked twice [members of Parliament]:
"Tell me graciously, Mr. Babbage, what happens if you enter wrong
numbers in the car?" Can we get the right answer? "I can not even
imagine what confusion in the head might lead to such a question.'''Знайдемо в усьому тексті рядок 'what':
result = re.findall('what', source)
print(result)Результат:
['what', 'what']Далі знайдемо в усьому тексті рядки 'what' або 'can':
result = re.findall('what|can', source)
print(result)Результат:
['what', 'can', 'what']Знайдемо рядок 'have' на початку тексту:
result = re.findall('^have', source)
print(result)Результат:
[]Знайдемо рядок 'I have' на початку тексту:
result = re.findall('^I have', source)
print(result)Результат:
['I have']Знайдемо рядок 'such' в кінці тексту:
result = re.findall('such$', source)
print(result)Результат:
[]Нарешті, знайдемо рядок 'such a question.$' в кінці тексту:
result = re.findall('such a question.$', source)
print(result)Результат:
['such a question.']Символи ^ і $ називаються якорями: за допомогою якоря ^ виконується пошук на початку рядка, а за допомогою якоря $ - у кінці. Поєднання .$ збігається з будь-яким символом в кінці рядка, включаючи крапку, тому регулярний вираз спрацював.
Виконаємо пошуку символів o або i, за якими слідує літера f:
result = re.findall('[oi]f', source)
print(result)Результат:
['of', 'if']Знайдемо одне або кілька поєднань символів q, u і e:
result = re.findall('[que]+', source)
print(result)Результат:
['e', 'ee', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'u', 'e', 'e', 'u', 'e', 'e', 'u', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'e', 'u', 'e', 'e', 'e', 'u', 'que']Знайдемо поєднання символів even, за яким слідує будь-який символ, крім літерного або цифрового символу або знака підкреслення:
result = re.findall('even\W', source)
print(result)Результат:
['even\n']Знайдемо поєднання символів in, за яким слідує поєднання символів the:
result = re.findall('in (?=the)', source)
print(result)Результат:
['in ', 'in ']І нарешті, пошук поєднання символів if, перед яким знаходиться рядок символів happens:
result = re.findall('(?<=happens) if', source)
print(result)Результат:
[' if']Існує кілька ситуацій, у яких правила шаблонів регулярних виразів конфліктують з правилами для рядків Python.
Наступний шаблон повинен збігтися з будь-яким словом, яке починається з ask:
result = re.findall('\bask', source)
print(result)Результат:
[]Чому цього не сталося? Python використовує спеціальні екрановані послідовності для рядків. Наприклад, \b для рядка означає «повернення на крок», але у мові регулярних виразів ця послідовність означає початок слова.
Завжди розміщуйте символ r перед рядком шаблону регулярного виразу, і екрановані послідовності Python будуть відключені.
|
result = re.findall(r'\bask', source)
print(resultРезультат:
['ask']При використанні функцій match() або search() усі збіги можна отримати з об’єкта результату find, викликавши функцію group() таким чином: find.group(). Якщо ви укладете шаблон в круглі дужки, збіги будуть збережені в окрему групу і кортеж, що складається з них, буде доступний завдяки виклику find.groups(), як показано тут:
import re
find = re.search(r'(\bI[a-z\s]+)(\basked)', source)
print(find.group())
print(find.groups())Результат:
I have been asked
('I have been ', 'asked')До окремих груп збігів, збережених в кортежі, можна звертатися, вказавши номер групи:
print(find.groups()[0])
print(find.groups()[1])Результат:
I have been
asked| Для створення регулярних виразів можна скористатися онлайн-сервісами: regexr.com , regex101.com , pythex.org , pyregex.com . |
11.3. Бінарні дані
Python 3 містить типи для керування двійковими даними (послідовностями восьмибітних цілих чисел, які можуть набувати значень від 0 до 255):
-
bytes- незмінний тип (кортеж байтів) -
bytearray- змінний тип (список байтів)
Створимо список з ім’ям blist і у наступному прикладі створимо змінну типу bytes з ім’ям the_bytes і змінну типу bytearray з ім’ям the_byte_array:
blist = [1, 2, 3, 255]
the_bytes = bytes(blist)
print(the_bytes)
the_byte_array = bytearray(blist)
print(the_byte_array)У результаті отримаємо байтовий рядок і масив байтів:
b'\x01\x02\x03\xff'
bytearray(b'\x01\x02\x03\xff')Запис значення типу bytes починається з символу b і лапки, за якими слідують шістнадцяткові послідовності, такі, як \x02 або символи ASCII, закінчується конструкція відповідним символом лапки.
Python перетворює шістнадцяткові послідовності або символи ASCII
print(b'\x61')
print(b'\x01abc\xff')в маленькі цілі числа, але показує байтові значення, які коректно записані з точки зору кодування ASCII:
b'a'
b'\x01abc\xff'Кожна із змінних (the_bytes і the_byte_array) може містити результат, що складається з 256 елементів, що мають значення від 0 до 255:
the_bytes = bytes(range(0, 256))
print(the_bytes)Перед нами не символи, а байти:
b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff'
У попередньму прикладі була використана функція bytes(), яка повертає незмінний об’єкт байтів, ініціалізований із заданим розміром і даними.
|
При виведенні на екран вмісту змінної типу bytes (або bytearray) Python використовує формат \x xx для недрукованих байтів і їх еквіваленти ASCII для друкованих (за винятком деяких екранованих послідовностей, на зразок, \n замість \x0a).
Стандартна бібліотека Python містить модуль struct, який обробляє бінарні дані. За допомогою цього модуля ви можете перетворювати бінарні дані у структури даних Python і навпаки.
Щоб зрозуміти, як цей модуль працює з даними бінарних файлів, напишемо невелику програму, яка отримує ширину і висоту зображення із файла з розширенням PNG.
Використаємо логотип Національного управління з аеронавтики і дослідження космічного простору (NASA) :
| Специфікація формату PNG передбачає, що ширина і висота зберігаються у перших 24 байтах. |
Код цієї програми
import struct (1)
valid_png_header = b'\x89PNG\r\n\x1a\n' (2)
f = open('nasa_logo.png', 'rb') (3)
data = f.read(30) (4)
if data[:8] == valid_png_header: (5)
width, height = struct.unpack('>LL', data[16:24]) (6)
print('Valid PNG, width', width, 'height', height)
else:
print('Not a valid PNG')
f.close()з таким результатом виконання
Valid PNG, width 175 height 145робить наступне:
-
Імпортування модуля
struct. -
Змінна
valid_png_headerмістить восьмибайтову послідовність, яка визначає початок коректногоPNG-файла. -
Відкривання бінарного файла із зображенням логотипу.
-
Зчитування у змінну
dataперших30байт файла зображення. -
Перевірка на валідність
PNG-файла. -
Значення змінної
widthотримується з16-20-го байтів, а змінноїheight- з байтів21-24.-
>LL- це рядок формату, який вказує функціїunpack(), як інтерпретувати вхідні послідовності байтів і перетворювати їх у типи данихPython.
-
Розглянемо рядок >LL детальніше:
-
символ
>означає, що цілі числа зберігаються в форматіbig-endian(зворотний порядок байтів) -
кожен символ
Lвизначає чотирьохбайтне ціле число типуunsigned long
Ви можете перевірити значення кожного чотирибайтового набору безпосередньо:
print(data[16:20])
print(data[20:24])Результати:
b'\x00\x00\x00\xaf'
b'\x00\x00\x00\x91'У цілих чисел зі зворотним порядком байтів головний байт розташовується зліва. Оскільки значення ширини і довжини менше 255, вони поміщаються в останній байт кожної послідовності. Ви можете переконатися у тому, що ці шістнадцяткові значення
print(int(0xaf))
print(int(0x91))або використовуючи інший запис
print(int('0xaf', 16))
print(int('0x91', 16))відповідають очікуваним десятковим значенням
175
145Якщо необхідно перетворити дані Python у байти, використовуйте функцію pack() модуля struct:
print(struct.pack('>L', 175))
print(struct.pack('>L', 145))Отримані результати співпадають з початковими:
b'\x00\x00\x00\xaf'
b'\x00\x00\x00\x91'У таблицях нижче показані специфікатори формату і специфікатори порядку байтів для функцій pack() та unpack().
| Специфікатор | Порядок байтів |
|---|---|
|
Прямий |
|
Зворотний |
| Специфікатори порядку байтів розташовуються першими у рядку формату. |
| Специфікатор | Опис | Кількість байтів |
|---|---|---|
|
Пропустити байт |
|
|
Знаковий байт |
|
|
Беззнаковий байт |
|
|
Знакове коротке ціле число |
|
|
Беззнакове коротке ціле число |
|
|
Знакове ціле число |
|
|
Беззнакове ціле число |
|
|
Знакове довге ціле число |
|
|
Беззнакове довге ціле число |
|
|
Беззнакове дуже довге ціле число |
|
|
Число з рухомою крапкою |
|
|
Число з рухомою крапкою подвійної точності |
|
|
Лічильник і символи |
|
|
Символи |
|
| Специфікатори формату слідують за символом, що вказує порядок байтів. |
Перед будь-яким специфікатором може слідувати число, яке вказує кількість: запис 4L аналогічний запису LLLL. Ви можете використовувати префікс лічильника замість конструкції >LL:
data = struct.unpack('>2L', data[16:24])
print(data)Результат:
(175, 145)Ми використовували зріз data[16:24], щоб отримати безпосередньо байти, які нас цікавлять. Можна додати специфікатор x, щоб пропустити частини, які нас не цікавлять:
data = struct.unpack('>16x2L6x', data)
print(data)Результат:
(175, 145)Останній рядок коду з функцією unpack() означає:
-
використовувати формат зі зворотним порядком байтів (
>) -
пропустити
16байт (16x) -
прочитати
8байт - два беззнакових довгих цілих числа (2L) -
пропустити останні
6байт (6x) із30прочитаних
11.4. Аналіз даних
Python є провідною мовою в області обробки даних, оскільки вона має потужні інструменти обробки та аналізу даних.
Серед популярних засобів аналізу даних в мові Python є:
-
NumPy та інші.
11.4.1. Jupyter Notebook
Розглянемо Jupyter Notebook - веб-застосунок, в якому ви можете створювати та обмінюватися документами, які містять робочий код, рівняння, візуалізації, пояснювальний текст.
Виконаємо встановлення локальної версії Jupyter Notebook у термінальному вікні за допомогою менеджера пакетів pip:
pip install jupyterДля запуску Jupyter Notebook, у термінальному вікні необхідно виконати команду:
jupyter notebookПісля запуску, Jupyter відкриється у вкладці веб-браузера за адресою: http://localhost:8888 .
На вкладці Files зберігаються файли системи, вкладка Running відстежує всі процеси, а вкладка Clusters призначена для інтерактивних паралельних обчислень з IPython .
Розглянемо, які об’єкти можна створити у Jupyter Notebook.
Для цього натисніть кнопку New на вкладці Files. У меню є можливість створити новий блокнот-документ з Python 3, звичайний текстовий файл, каталог і термінал.
-
При створенні звичайного текстового файла, відкривається вікно звичайного текстового редактора. В редакторі ви можете вмикати/вимикати відображення номерів рядків/заголовок, обрати мову програмування і виконати пошук і заміну. Крім того, ви можете зберігати, перейменовувати або завантажувати файл чи створювати новий файл.
-
Ви також можете створювати каталоги для організації документів. Просто натисніть кнопку
Folder, яка з’являється, коли ви натискаєте кнопкуNewу вашому початковому меню, і у вашому огляді з’явиться новий каталог, який краще перейменувати відразу. -
Створений термінал підтримує інтерактивність на основі браузера. Він працює так само, як і термінал вашої системи.
Якщо ви хочете почати роботу у своєму блокноті, поверніться до головного меню та натисніть кнопку Python 3 у категорії Notebook. Відкриється вікно нового блокнота, що містить панель меню, панель інструментів і порожню комірку-рядок для введення коду.
Тепер можна розпочати імпортувати необхідні бібліотеки для вашого коду, вводити сам код і запускати на виконання, додавати, видаляти або редагувати комірки відповідно до ваших потреб, вставляти пояснювальний текст для уточнення програмного коду тощо.
У документі-блокноті відсутнє запрошення >>>, яке використовується в інтерактивному режимі Python, окрім того, натискання клавіші Enter лише додає нові рядки в комірку-рядок. Щоб виконати код в комірці, необхідно натиснути на кнопці Run на панелі інструментів, або натиснути сполучення клавіш Alt+Enter .
|
11.5. Завдання
11.5.1. Контрольні запитання
-
Що таке «система кодування»?
-
Опишіть характеристики форматів
ASCIIіUnicode. -
Що таке
UTF-8? -
Для чого використовуються «регулярні вирази»?
-
Що називають «бінарними даними»? Які типи у
Pythonпризначені для роботи з бінарними даними? -
Які інструменти для аналізу даних присутні в
Python? Для чого використовуєтьсяJupyter Notebook?
11.5.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
Створіть рядок
Unicodeз ім’ямunknownі надайте йому значення'\u2653'. Виведіть на екран значення рядкаunknown. Знайдіть ім’яUnicodeдляunknown. -
Створіть рядок
Unicodeз ім’ямunknown2і надайте йому значення'\U000057A6'. Виведіть на екран значення рядкаunknown2. Знайдіть ім’яUnicodeдляunknown2. -
Закодуйте рядок
unknownз використанням кодуванняUTF-8у змінну типуbytesз ім’ямunknown_bytes. Виведіть на екран значення змінноїunknown_bytes. -
Використовуючи кодування
UTF-8, декодуйте зміннуunknown_bytesу рядокunknown_string. Виведіть на екран значення змінноїunknown_string. Чи однакові значення мають змінніunknown_stringіunknown? -
Продовжіть і надрукуйте рядок
I’m ..., використовуючи стиль форматування за допомогою функціїformat(). Підставте рядки'hungry','in a good mood','looking forward to it','worried'і'thirsty'у цей рядок. -
Запишіть наступний лист за формою за допомогою стилю форматування з використанням функції
format()(або за допомогоюf-рядків). Збережіть рядок з ім’ямletter. Створіть словник з ім’ямresponse, що має значення для ключів:'addressee','amount','product',sender,'post','institution'. Виведіть на екран значення змінноїletter, у яку підставлені значення зі словникаresponse.
Dear Mr. {addressee}:
With reference to our telephone conversation today, I am writing to confirm your order for: {amount} x {product} (Ref. No. 856).
Please contact us again if we can help in any way.
Yours sincerely,
{sender}
{post} of {institution}
11.5.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
-
Використайте регулярні вирази для пошуку рядків у тексті. Текст, у якому відбуватиметься пошук, можна скопіювати із сайту Project Gutenberg’s і зберегти у файл. Імпортуйте модуль
re, щоб використовувати функції регулярних виразів уPython. Вивести на екран усі слова, які починаються з літери «с», чотирилітерні слова, які починаються з літериc, слова, які закінчуються на буквуr, слова, які містять чотири літериtimeпоспіль. -
Виведіть інформацію про однопіксельний прозорий
GIF-файл. Використайте функціюunhexlify()для того, щоб перетворити шістнадцятковий рядок у змінну типуbytesз ім’ямgif. Байти, що містяться у зміннійgif, визначають однопіксельний прозорийGIF-файл. Коректний файл форматуGIFпочинається з рядкаGIF89a. Чи є цей файл коректним? Ширина файла форматуGIFє шістнадцятибітним цілим числом з прямим порядком байтів (little-endian, специфікація GIF ), яке починається зі зсуву6байт. Його висота має такий же розмір і починається зі зсуву8байт. Отримайте і виведіть на екран ці значення для змінноїgif. Чи рівні вони1?
'47494638396101000100800000000000ffffff21f90401000000002c000000000100010000020144003b'
-
Запишіть у текстовий файл з ім’ям
validate.txtінформацію про ширину і висоту зображення, отримані ізGIF-файла (на сторінці розміри файла зменшені, відкрийте зображення у новій вкладці браузера для відображення реальних розмірів). Скористайтеся відомостями із попереднього завдання.

12. WWW
У 1989 році британський спеціаліст з інформатики Тім Бернерс-Лі (Tim Berners-Lee ) запропонував спосіб поширення інформації всередині CERN і дослідницької спільноти. Свій проект він назвав World Wide Web (Всесвітня павутина) і виділив три основні ідеї, які були покладені в її основу:
-
HTTP(Hypertext Transfer Protocol , протокол передачі гіпертексту) - специфікація для веб-клієнтів і веб-серверів для обміну запитами та відповідями -
HTML(Hypertext Markup Language , мова розмітки гіпертексту) - формат для представлення інформації -
URL(Uniform Resource Locator , уніфікований вказівник ресурсу) - спосіб унікально позначити сервер і ресурс на цьому сервері
Всесвітня павутина - це клієнт-серверна система. Веб-клієнт дає запит веб-серверу :
-
Відкриває з’єднання за протоколом
TCP/IP. -
Відправляє
URLта іншу інформацію за допомогою протоколуHTTP. -
Отримує відповідь, формат якої також визначається протоколом
HTTP. -
Відповідь включає у себе статус запиту і (у випадку, якщо запит виконано успішно) дані і формат відповіді (наприклад
HTML).
Найвідоміший веб-клієнт - це браузер .
12.1. Створення веб-клієнтів
12.1.1. Модуль urllib
Python 3 у власній стандартній бібліотеці містить такі модулі для роботи в Інтернеті:
-
http- керує всіма особливостями клієнт-серверної взаємодії за протоколомHTTP:-
clientвиконує всю роботу на стороні клієнта. -
serverдопомагає написати веб-сервер. -
cookiesіcookiejarкерують cookies .
-
-
urllibпрацює на базіhttp:-
request- обробляє клієнтські запити. -
response- обробляє відповіді сервера. -
parse- розбиваєURLна частини.
-
Скористаємося модулем urllib стандартної бібліотеки Python, щоб отримати певну інформацію із сайту. URL у наступному прикладі повертає код веб-сторінки в Інтернеті у вигляді HTML (разом з CSS і JavaScript):
import urllib.request as ur
url = 'http://openweathermap.org'
conn = ur.urlopen(url)
data = conn.read()
print(conn.status)
print(conn.getheader('Content-Type'))
print(data)Цей фрагмент коду відкрив з’єднання з віддаленим сервером, створив запит HTTP і отримав HTTP-відповідь. Відповідь містить не лише сам вміст веб-сторінки. Одна з найбільш важливих частин відповіді - це код статусу HTTP: на екран виводиться значення 200. Це означає, що з’єднання пройшло успішно і отримано відповідь:
200
text/html; charset=UTF-8
b'<!DOCTYPE html>\n<html lang=\'en\'>\n...
...
...</body>\n</html>'Таких кодів статусу HTTP є багато і вони об’єднуються в групи у відповідності з їх першою цифрою:
-
1xx(інформація) - cервер отримав запит, але має деяку додаткову інформацію для клієнта. -
2xx(успіх) - cпрацювало, кожен код успіху, крім200, повідомляє додаткові деталі. -
3xx(перенаправлення) - ресурс був переміщений, тому відповідь повертає кліенту новийURL. -
4xx(помилка клієнта) - деякі проблеми на стороні клієнта, на зразок помилки 404 (ресурс не знайдений). -
5xx(помилка сервера) - код500- це загальна помилка.
Формат даних, які відправляє сервер, вказується значенням Content-Type у заголовку відповіді HTTP. Рядок text/html є MIME-типом і означає, що дані до нас прийшли у вигляді HTML. Значення charset=UTF-8 вказує на кодування веб-сторінки.
Щоб дізнатися, які ще заголовки HTTP нам відправив сервер, доповнимо попередній код:
for key, value in conn.getheaders():
print(key, value)Даний цикл буде відбирати заголовки HTTP-запитів і розміщувати у словнику Python. Назва заголовку - ключ словника, значення заголовку - значення словника. Результати виконання програми доповняться наступними:
...
Server openresty/1.9.7.1
Date Thu, 11 Jul 2019 09:39:43 GMT
Content-Type text/html; charset=UTF-8
Transfer-Encoding chunked
Connection close
X-Powered-By PHP/7.1.7
Cache-Control private, must-revalidate
...12.1.2. Модуль requests
Завдання, пов’язані з розробкою веб-клієнтів, можна виконувати і за допомогою сторонніх бібліотек Python. Одна з таких бібліотек називається requests.
Для початку потрібно встановити бібліотеку requests (якщо вона не встановлена) з вікна терміналу командою:
pip install requestsРеалізуємо попередній приклад за допомогою бібліотеки requests:
import requests
url = 'http://openweathermap.org'
r = requests.get(url)
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
print(r.text)Результати будуть аналогічними і відформатованими:
200
text/html; charset=UTF-8
UTF-8
<!DOCTYPE html>
<html lang='en'>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta http-equiv=Expires content="Tue, Sep 20 2018 15:27:22 GMT">
...
</body>
</html>
Для детального розуміння бібліотеки requests перегляньте її офіційну документацію .
|
12.2. Використання API: Twitter API
API (Application Programming Interface, API ) - це інтерфейс взаємодії між сайтом і сторонніми програмами.
|
Продемонструємо роботу з API на прикладі Twitter - соціальної мережі мікроблогів, яка дає змогу користувачам надсилати короткі текстові повідомлення.
| Cтворіть обліковий запис Twitter , якщо його у вас ще немає. |
12.2.1. Створення облікового запису розробника
Для початку, необхідно подати заявку на створення облікового запису розробника на порталі Twitter для розробників програм.
У процесі створення заявки виконуються ряд наступних кроків (англ.):
-
ввести номер телефону, пов’язаний з вашим обліковим записом
Twitter -
описати своїми словами, який застосунок ви створюєте
-
надіслати заявку
-
перевірити свою електронну пошту, пов’язану з вашим обліковим записом
Twitter, і підтвердити реєстрацію з отриманого електронного листа (у моєму випадку необхідно було відповісти на додатковий лист від команди технічної підтримкиTwitter)
12.2.2. Створення застосунку і отримання ключів
Після створення облікового запису розробника на порталі розробника ви можете перейти до порталу програм для розробників .
На сторінці порталу необхідно натиснути на кнопку Create an app і заповнити подробиці для вашого застосунку та погодитись з Умовами надання послуг.
Після цього, перейти на вкладку Keys and tokens, на якій мають бути присутні ключі Consumer API keys (клієнтські ключі)
-
API key(ключAPI) -
API secret key(секретний ключAPI)
Далі необхідно натиснути кнопку Create для створення Access token & access token secret:
-
Access token(токен доступу) -
Access token secret(секретний токен доступу)
| Токен - це електронний ключ для доступу до чого-небудь. |
API secret key використовується для аутентифікації застосунку, яка використовує Twitter API, а Access token secret - для аутентифікації користувача.
Отримані ключі необхідно зберегти у безпечному місці.
| Усі ці ключі слід розглядати як паролі, і вони не повинні бути включені у ваш код у вигляді звичайного тексту. |
Одним з відповідних способів є збереження їх у файлі JSON twitter_credentials.json і завантаження цих значень з коду, коли це необхідно.
import json
# Ввести ключі і токени (в тому числі і секретні) як рядки в наступних полях
credentials = {}
credentials['CONSUMER_KEY'] = 'your_consumer_key'
credentials['CONSUMER_SECRET'] = 'your_consumer_secret'
credentials['ACCESS_TOKEN'] = 'your_access_token'
credentials['ACCESS_SECRET'] = 'your_access_secret'
# Зберегти словник credentials у файл як JSON
with open("twitter_credentials.json", "w") as file:
json.dump(credentials, file)12.2.3. Бібліотека Python для Twitter API
Python містить велику кількість бібліотек (Twitter libraries ) для Twitter API.
Зупинимось на бібліотеці Tweepy і встановимо її за допомогою менеджера пакетів pip, виконавши команду у термінальному вікні:
pip install tweepy12.2.4. Аутентифікація і отримання даних
Під’єднаємось до власного облікового запису Twitter і надрукуємо останні твіти зі стрічки. Для цього прочитаємо ключі і токени з файла twitter_credentials.json і використаємо їх у наступному коді:
import tweepy
import json
# Завантажити credentials із JSON файла
with open("twitter_credentials.json", "r") as file:
creds = json.load(file)
# Функція доступу до API
def connect_to_twitter_OAuth():
auth = tweepy.OAuthHandler(creds['CONSUMER_KEY'], creds['CONSUMER_SECRET'])
auth.set_access_token(creds['ACCESS_TOKEN'], creds['ACCESS_SECRET'])
# клас API надає доступ до всіх методів Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True)
return api
# Створити API об'єкт
api = connect_to_twitter_OAuth()
# отримати останніх 20 твітів з власної стрічки
public_tweets = api.home_timeline()
for tweet in public_tweets:
print(tweet.text)
Twitter вимагає для усіх запитів використовувати OAuth для автентифікації.
|
Для прикладу, отримаємо інформацію з облікового запису користувача Twitter про необхідність верифікації номера телефону, який пов’язаний з обліковим записом. Для цього необхідно доповнити наш код такими рядками (user_name - це ім’я користувача):
info = api.get_user('name_user')
print(info.needs_phone_verification)Результатом виконання буде одне з двох значень: True чи False.
Кожен об’єкт твіт має довгий список атрибутів, включаючи атрибути тексту і верифікації номера телефону, які були використані вище.
Напишемо функцію для отримання атрибутів твітів для певного облікового запису. Спочатку визначимо змінну user_tweets для зберігання твітів (user_name - це ім’я користувача):
user_tweets = api.user_timeline('user_name')Код функції буде наступним:
def extract_tweet_attributes(tweet_object):
# створення списку для збереження твітів
tweet_list =[]
# прохід по твітах у циклі
for tweet in tweet_object:
tweet_id = tweet.id # унікальний ідентифікатор для твіту (ціле число)
text = tweet.text # utf-8 текст твіту
created_at = tweet.created_at # utc час створення твіту
source = tweet.source # утиліта для публікації твіту
retweets = tweet.retweet_count # кількість ретвітів
favorites = tweet.favorite_count # кількість лайків
# приєднання атрибутів до списку
tweet_list.append(
{'tweet_id': tweet_id,
'text': text,
'created_at': created_at,
'source': source,
'retweets': retweets,
'favorites': favorites
}
)
return tweet_listВикличемо створену функцію для отримання доступу до атрибутів кожного твіту, використовуючи наступний код:
ut = extract_tweet_attributes(user_tweets)
for item, value in enumerate(ut):
print(item)
for key, val in value.items():
print('{0:<20} {1:}'.format(key, val))
print()Розглянемо іншу задачу. Створимо запит для API-пошуку за ключовим словом python, який повертає твіти за останні 7 днів. Визначимо для цієї задачі дві функції.
Перша функція матиме такі параметри: рядок з ключовим словом query, мову пошуку lang і обмеження на кількість твітів limit (за замовчуванням має значення None, тобто обмеження відсутнє):
def rest_tweets(query, lang='en', limit=None):
'''
функція повертає усі твіти за останні 7 днів від найновішого, відповідно до рядка пошуку query
параметр query містить слова для пошуку
параметр lang визначає мову твітів
параметр limit визначає максимальну кількість твітів для пошуку (за замовчуванням, None - безлімітно)
команда return tweets повертає список твітів, отримані після запиту
'''
# список для зберігання результатів пошуку
tweets = []
# пошук і зберігання результатів у список
for tweet in tweepy.Cursor(api.search, q=query, lang=lang).items(limit):
tweets.append(tweet._json)
# словник для зберігання окремих твітів та значень їх атрибутів
dict_tweets = {}
# заповнення словника
for index, tweet in enumerate(tweets):
dict_tweets.setdefault(index,
{'user': tweet['user']['screen_name'],
'location': tweet['user']['location'],
'description': tweet['user']['description'],
'date': tweet['created_at'],
'text': tweet['text'],
'favorite': tweet['favorite_count'],
'retweet': tweet['retweet_count']
}
)
return dict_tweetsВизначимо змінну user_tweets_by_query, яка буде отримувати словник словників із функції rest_tweets(). Наприклад, функція rest_tweets() може викликатися з такими аргументами:
user_tweets_by_query = rest_tweets('python', lang='en', limit=2)Визначимо другу функцію для друкування атрибутів твіту, в якій використовуються наступні параметри:
-
Перший параметр:
user_tweets_by_query- змінна, що зберігає словник словників, який повертає функціяrest_tweets(). -
Другий параметр:
content='text'- це параметр із значенням за замовчуванням (якщо у функцію не буде передано значення другого параметра, то буде використано значення за замовчуванням). Цей параметр вказує, які атрибути твіту необхідно обробляти, наприклад, значенняtextвказує на текст твіту, а значенняfavorite- на кількість лайків і т. д. При цьому будуть виводитися на друк значення лише єдиного вказаного атрибута знайдених твітів. -
Третій параметр:
all=False- це також параметр із значенням за замовчуванням (якщо у функцію не буде передано значення третього параметра, то буде використано значення за замовчуванням). Якщо у функцію на місці третього параметра буде передано значенняTrue, то функція виведе значення усіх атрибутів знайдених твітів. У разі використання для третього параметра значення за замовчуванням (False), функція відпрацює як у випадку із другим параметром.
Друга функція матиме натсупний код:
def print_tweets(user_tweets_by_query, content='text', all=False):
'''
функція для виведення значень атрибутів твітів
'''
k = 1
if not(all):
for key, value in user_tweets_by_query.items():
for item in user_tweets_by_query[key]:
if item == content:
print('{0:}: {1:<5}'.format(k, user_tweets_by_query[key][item]))
k += 1
else:
for key, value in user_tweets_by_query.items():
print('{0:>12}: {1:}'.format('id tweet', k))
for item in user_tweets_by_query[key]:
print('{0:>12}: {1:}'.format(item, user_tweets_by_query[key][item]))
k += 1
print()Декілька прикладів виклику функції print_tweets() з аргументами:
print_tweets(user_tweets_by_query, '', True)
print_tweets(user_tweets_by_query, 'user', True)
print_tweets(user_tweets_by_query, 'text')Остаточний код для нашої задачі виглядає так:
import tweepy
import json
# Завантажити credentials із JSON файла
with open("twitter_credentials.json", "r") as file:
creds = json.load(file)
# Функція доступу до API
def connect_to_twitter_OAuth():
auth = tweepy.OAuthHandler(creds['CONSUMER_KEY'], creds['CONSUMER_SECRET'])
auth.set_access_token(creds['ACCESS_TOKEN'], creds['ACCESS_SECRET'])
api = tweepy.API(auth, wait_on_rate_limit=True)
return api
# Створити API об'єкт
api = connect_to_twitter_OAuth()
def rest_tweets(query, lang='en', limit=None):
'''
функція повертає усі твіти за останні 7 днів від найновішого, відповідно до рядка пошуку query
параметр query містить слова для пошуку
параметр lang визначає мову твітів
параметр limit визначає максимальну кількість твітів для пошуку (за замовчуванням, None - безлімітно)
команда return tweets повертає список твітів, отримані після запиту
'''
# список для зберігання результатів пошуку
tweets = []
for tweet in tweepy.Cursor(api.search, q=query, lang=lang).items(limit):
tweets.append(tweet._json)
# словник для зберігання окремих твітів та значень їх атрибутів
dict_tweets = {}
for index, tweet in enumerate(tweets):
dict_tweets.setdefault(index,
{'user': tweet['user']['screen_name'],
'location': tweet['user']['location'],
'description': tweet['user']['description'],
'date': tweet['created_at'],
'text': tweet['text'],
'favorite': tweet['favorite_count'],
'retweet': tweet['retweet_count']
}
)
return dict_tweets
def print_tweets(user_tweets_by_query, content='text', all=False):
'''
функція для виведення значень атрибутів твітів
'''
k = 1
if not(all):
for key, value in user_tweets_by_query.items():
for item in user_tweets_by_query[key]:
if item == content:
print('{0:}: {1:<5}'.format(k, user_tweets_by_query[key][item]))
k += 1
else:
for key, value in user_tweets_by_query.items():
print('{0:>12}: {1:}'.format('id tweet', k))
for item in user_tweets_by_query[key]:
print('{0:>12}: {1:}'.format(item, user_tweets_by_query[key][item]))
k += 1
print()
user_tweets_by_query = rest_tweets('python', lang='en', limit=2)
# виклики функції print_tweets() з різними аргументами
print_tweets(user_tweets_by_query, '', True)
print_tweets(user_tweets_by_query, 'user', True)
print_tweets(user_tweets_by_query, 'text')
print_tweets(user_tweets_by_query, 'date')12.3. Веб-додатки на боці сервера
Python добре підходить для написання веб-серверів і програм, що працюють на боці сервера. Це зумовило появу великої кількості веб-фреймворків.
| Веб-фреймворк - програмний комплекс, який, як мінімум, обробляє запити клієнта і відповіді сервера. Також, він може мати розширені можливості, серед яких: маршрути, шаблони, авторизація користувачів, сесії тощо. |
Для отримання детальної інформації, перегляньте класифікацію фреймворків для Python.
|
Найпопулярнішим Python фреймворком, особливо для великих проектів, є Django .
Для короткого огляду можливостей фреймворків використаємо два мікрофреймворки Python: Bottle і Flask .
Веб-фреймворки і веб-сервери Python, про які йде мова далі, використовують WSGI Web Server Gateway Interface (WSGI) - універсальний API між веб-застосунками і веб-серверами.
|
12.3.1. Bottle
Bottle складається з одного файла Python, тому його досить легко випробувати і розгорнути. Bottle не є частиною стандартної бібліотеки Python, тому його треба встановити за допомогою наступної команди:
pip install bottleРозглянемо код, що запустить тестовий веб-сервер і на сторінці у браузері надрукує текстовий рядок, коли ви перейдете за URL http://localhost:9999/ . Збережіть цей файл як bottle1.py:
from bottle import route, run
@route('/')
def home():
return "It's my home page!"
run(host='localhost', port=9999)Bottle використовує декоратор route, щоб зв’язати URL з наступною функцією; у цьому прикладі / (/ - домашня сторінка сайту) обробляється функцією home().
| Декоратор - це функція, яка приймає одну функцію у якості аргументу і повертає іншу функцію. |
Запустимо цей сценарій сервера за допомогою наступної команди у вікні терміналу:
python bottle1.pyЯкщо в браузері набрати адресу http://localhost:9999/ , у вікні браузера з’явиться наш текстовий рядок:
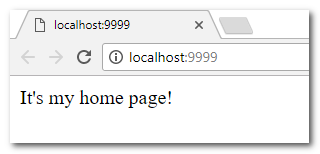
localhost і 127.0.0.1 - це IP-адреси клієнта, які є для протокола TCP синонімами локального комп’ютера, тому вони спрацюють незалежно від того, чи є підключення до Інтернету. 9999 - номер порту, через який здійснюється з’єднання.
|
Функція run() запускає вбудований тестовий веб-сервер Bottle.
Тепер замість створення у коді тексту для домашньої сторінки, створимо окремий HTML-файл, який називається index.html і містить такий рядок:
My <strong>new</strong> and <em>improved</em> home page!!!Bottle буде повертати вміст цього файла, коли запитується домашня сторінка. Збережіть цей сценарій як bottle2.py:
from bottle import route, run, static_file
@route('/')
def main():
return static_file('index.html', root='.')
run(host='localhost', port=9999)У виклику функції static_file() ми хочемо отримати файл index.html з каталогу, вказаному в root (у нашому випадку в '.', в поточному каталозі). Якщо код попереднього прикладу все ще виконується, то зупиніть сервер, використавши сполучення клавіш Ctrl+C. Після цього запустіть новий сервер:
python bottle2.pyТепер, кожен раз, коли ви звертаєтеся до сторінки http://localhost:9999/ , ви повинні бачити у браузері відформатоване повідомлення:
My new and improved home page!!!
Додамо ще один приклад, який демонструє, як передавати аргументи в URL і використовувати їх. Створіть новий файл і дайте йому назву bottle3.py:
from bottle import route, run, static_file
@route('/')
def home():
return static_file('index.html', root='.')
@route('/echo/<thing>')
def echo(thing):
return "Say hello to my little friend: {0:s}!".format(thing)
run(host='localhost', port=9999)У коді з’явилася нова функція echo(), у яку ми хочемо передавати рядковий аргумент через URL. За це відповідає рядок @route ('/echo/<thing>') у нашому прикладі.
Конструкція <thing> у маршруті @route означає, що все, що знаходиться в URL після /echo/, присвоюється рядковому аргументу thing, який передається функції echo.
Щоб побачити, що відбудеться у цьому випадку, зупиніть сервер, якщо він усе ще працює, і запустіть його з новим кодом:
python bottle3.pyДалі перейдіть у браузері за посиланням http://localhost:9999/echo/Alex . Ви повинні побачити у вікні браузера наступне:
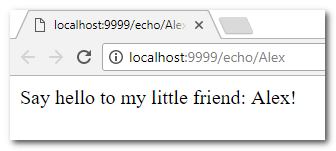
Дані приклади працюють, вводячи URL у адресний рядок браузера.
У виклик функції run() можна додати ще такі аргументи:
-
debug = True- створює сторінку налагодження, у разі отримання помилкиHTTP -
reloader = True- оновлює сторінку у браузері, якщо код програми змінився
12.3.2. Flask
Якщо необхідно більше можливостей від роботи фреймворка, можна спробувати Flask.
Flask у використанні майже такий простий, як і Bottle, але він підтримує багато розширень, які можуть бути корисними у професійній веб-розробці, наприклад аутентифікація за допомогою соціальних мереж і інтеграція з базами даних. У цьому фреймворку збалансовані простота використання і багатий набір функцій.
Встановити Flask можна за допомогою вікна терміналу і команди pip:
pip install flaskСпробуємо поекспериментувати із фреймворком Flask. У Flask каталог за замовчуванням для статичних файлів називається static, і URL для таких файлів теж починається зі /static. Змінимо каталог на '.' (поточний каталог) і префікс URL на '' (порожній), щоб дозволити адресі / відображати файл index.html. Збережіть код нижче у файлі flask1.py:
from flask import Flask
app = Flask(__name__, static_folder='.', static_url_path='')
@app.route('/')
def home():
return app.send_static_file('index.html')
@app.route('/echo/<thing>')
def echo(thing):
return "Say hello to my little friend: {0:s}".format(thing)
app.run(port=9999, debug=True)У функції run() установка параметра debug = True активізує також автоматичне овнолення веб-сторінки, тоді як фреймворк Bottle для налагодження і оновлення використовує окремі аргументи.
Далі запустіть сервер з терміналу:
python flask1.pyПротестуйте домашню сторінку, ввівши у адресний рядок браузера наступний URL: http://localhost:9999/ . У вікні браузера можна побачити наступне:
My new and improved home page!!!
Далі спробуйте перейти за адресою http://localhost:9999/echo/Mira і у вікні браузера на вас чекає повідомлення:
Say hello to my little friend: Mira
Є ще одна перевага установки параметра debug рівним True при виклику методу run. Якщо у серверному коді генерується виняток, Flask відкриває особливу відформатовану сторінку, яка містить корисні відомості про те, що і де пішло не так. Навіть більше: ви можете вводити команди, щоб побачити значення змінних у програмі сервера.
Не встановлюйте параметр debug = True на робочих веб-серверах. Це надасть потенційним зловмисникам занадто багато інформації про ваш сервер.
|
Flask містить jinja2 - велику систему шаблонів. Розглянемо невеликий приклад одночасного використання jinja2 і Flask.
Створіть каталог templates і файл flask2.html всередині нього з таким вмістом:
<html>
<head>
<title>Flask2 Example</title>
</head>
<body>
Say hello to my little friend: {{ thing }}
</body>
</html>Напишемо серверний код, який отримує цей шаблон, створює HTML і заповнює його значенням аргументу thing, який ми передаємо. Збережіть цей файл з ім’ям flask2.py:
from flask import Flask, render_template
app = Flask(__name__, static_folder='.', static_url_path='')
@app.route('/')
def home():
return app.send_static_file('index.html')
@app.route('/echo/<thing>')
def echo(thing):
return render_template('flask2.html', thing=thing)
app.run(port=9999, debug=True)Тепер у браузері перейдіть за цією адресою http://localhost:9999/echo/James і прочитайте наступне повідомлення:
Say hello to my little friend: James
Модифікуємо наш приклад і збережемо його у каталозі templates з ім’ям flask3.html:
<html>
<head>
<title>Flask3 Example</title>
</head>
<body>
Say hello to my little friend: {{ thing }} {{ place }}
<br>
Hello, {{ thing }}!
</body>
</html>Другий аргумент place в URL можна передати різними способами, наприклад, розширивши URL (збережіть файл як flask3a.py):
from flask import Flask, render_template
app = Flask(__name__, static_folder='.', static_url_path='')
@app.route('/')
def home():
return app.send_static_file('index.html')
@app.route('/echo/<thing>/<place>')
def echo(thing, place):
return render_template('flask3.html', thing=thing, place=place)
app.run(port=9999, debug=True)Зупиніть попередній сценарій тестового сервера, якщо він ще працює, і потім запустіть новий:
python flask3a.pyПерейшовши у браузері за новою адресою http://localhost:9999/echo/James/Bond , ви отримаєте:
Say hello to my little friend: James Bond Hello, James!
Аргументи можна передати як параметри команди GET (збережіть файл як flask3b.py):
from flask import Flask, render_template, request
app = Flask(__name__, static_folder='.', static_url_path='')
@app.route('/')
def home():
return app.send_static_file('index.html')
@app.route('/echo/')
def echo():
thing = request.args.get('thing')
place = request.args.get('place')
return render_template('flask3.html', thing=thing, place=place)
app.run(port=9999, debug=True)Запустіть новий сервер:
python flask3b.pyНа цей раз використайте новий URL: http://localhost:9999/echo/?thing=Frodo&place=Baggins . У вікні браузера має з’явитися наступне повідомлення:
Say hello to my little friend: Frodo Baggins Hello, Frodo!
Коли команда GET використовується в URL, будь-які аргументи повинні передаватися у форматі &key1=value1&key2=value2&….
Також можна використовувати оператор словника (**), щоб передати декілька аргуменів у шаблон за допомогою одного словника (файл flask3c.py):
from flask import Flask, render_template, request
app = Flask(__name__, static_folder='.', static_url_path='')
@app.route('/')
def home():
return app.send_static_file('index.html')
@app.route('/echo/')
def echo():
kwargs = {}
kwargs['thing'] = request.args.get('thing')
kwargs['place'] = request.args.get('place')
return render_template('flask3.html', **kwargs)
app.run(port=9999, debug=True)
**kwargs діє як команди thing = thing і place = place.
|
12.4. Скрапінг
Деякі кроки у процесі завантаження інформації (новини, курси валют, ціни на товар у різних інтернет-магазинах тощо) зі сторінок Інтернету можна автоматизувати.
Після того, як вміст веб-сторінки буде отримано з одного із веб-серверів, програма-парсер може проаналізувати її, щоб знайти якусь корисну інформацію.
| Якщо потрібно потужне рішення, що поєднує в собі можливості пошуку і вибірки даних, варто використати фреймворк Scrapy . |
12.4.1. Бібліотека beautifulsoup
Щоб cпробувати Python у скрапінгу , використаємо модуль BeautifulSoup , який не входить в стандартну бібілотеку Python. Для того щоб встановити BeautifulSoup, введіть наступну команду (в кінці назви вказана версія бібліотеки):
pip install beautifulsoup4Припустимо, із веб-сторінки https://bottlepy.org/docs/dev/ необхідно отримати усі присутні на ній гіперпосилання.
Тег мови HTML, який визначає гіперпосилання, - a, href - атрибут цього тега, який вказує на місце призначення посилання.
|
Визначимо функцію get_links(), яка автоматизує роботу по «збиранню» гіперпосилань, яка отримує один (як у нашому випадку) або кілька URL аргументів. Напишемо програму і збережемо у файлі з ім’ям scrap_links.py:
def get_links(url):
import requests
from bs4 import BeautifulSoup as soup
result = requests.get(url)
page = result.text
doc = soup(page, features='html.parser')
links = [element.get('href') for element in doc.find_all('a')]
return links
urls = ['https://bottlepy.org/docs/dev/']
for url in urls:
print('Links in', url)
for num, link in enumerate(get_links(url), start=1):
print(num, link)
print()У програмному коді функції використаний синтаксис включення для списків (рядок links = [element.get('href') for element in doc.find_all('a')]), який можна замінити звичайним синтаксисом Python:
def get_links(url):
links = []
import requests
from bs4 import BeautifulSoup as soup
result = requests.get(url)
page = result.text
doc = soup(page, features='html.parser')
for element in doc.find_all('a'):
links.append(element.get('href'))
return linksПерші рядки результатів виконання програми виглядатимуть так:
Links in https://bottlepy.org/docs/dev/
1 #bottle-python-web-framework
2 http://www.wsgi.org/
3 http://python.org/
4 http://docs.python.org/library/
5 tutorial.html#tutorial-templates
6 http://www.makotemplates.org/
7 http://jinja.pocoo.org/
8 http://www.cheetahtemplate.org/
9 http://pythonpaste.org/
10 https://github.com/william-os4y/fapws3
11 https://github.com/jonashaag/bjoern
12 https://developers.google.com/appengine/
13 http://www.cherrypy.org/
14 http://www.wsgi.org/
15 http://localhost:8080/hello/world
16 https://github.com/bottlepy/bottle/raw/master/bottle.py
...12.5. Завдання
12.5.1. Контрольні запитання
-
Для чого використовують бібліотеки
urllibіrequests? -
Об’єкт якого типу повертає функція
requests.get()? Яким чином можна отримати доступ до результату роботи цієї функції у вигляді рядкового значення? -
Як отримати код статусу
HTTPіз відповіді на запит модуляrequests? -
Що таке
API? -
Що таке «скрапінг»? Як можна застосувати бібліотеку
beautifulsoupдля скрапінгу? -
Назвіть фреймворки для
Python. У яких випадках необхідно їх використовувати?
12.5.2. Вправи
Виконайте в інтерактивному інтерпретаторі такі завдання:
-
За допомогою модуля
requestsвиконайте запит до сайту gutenberg.org . -
Виведіть на екран інформацію про статус запиту.
-
Виведіть на екран інформацію про кодування сторінки.
12.5.3. Задачі
Напишіть програми у середовищі програмування для розв’язування таких завдань:
Створіть каркас простого сайту з використанням фреймворка Flask.
Встановіть фреймворк. Використайте для роботи сервера за адресою localhost порт 5000. Якщо комп’ютер вже використовує цей порт, використайте інший. Додайте функцію home() для обробки запитів до домашньої сторінки, яка, наприклад, повертає рядок This is a web page project. It works!. Створіть шаблон jinja2, який називається project.html. Шаблон має зберігатися у каталозі templates і мати наступний вміст:
<html>
<head>
<title>This is a web page project. It works!</title>
<body>
This will be a {{name}}, where I will post {{videos}} and {{articles}}.
</body>
</html>
Модифікуйте функцію home(), щоб вона використовувала шаблон project.html. Передайте їй три параметра для команди GET: name, videos і articles.
Словник
- Алгоритм
-
набір формалізованих інструкцій, які описують порядок дій виконавця (комп’ютера, людини) для отримання результату розв’язання задачі за скінченну кількість кроків.
- Включення (
list comprehension,set comprehension,dictionary comprehension) -
cинтаксична конструкція в
Python, яка дозволяє створювати списки, множини або словники, об’єднуючи цикли та умовні перевірки в компактній і зрозумілій формі. - Генератор
-
об’єкт, який призначений для створення послідовностей. З допомогою генераторів можна проходити (ітерувати) по великим послідовностям без необхідності створення і збереження усієї послідовності у пам’ять відразу.
- Змінні
-
іменовані об’єкти, які посилаються на дані в пам’яті комп’ютера і можуть змінювати своє значення в межах програми.
- Імпорт
-
процес підключення модуля (файл
.py) або пакету в інший файл, щоб використовувати його функції, класи або змінні. Це дозволяє організовувати код, робити його модульним і повторно використовувати. - Інтерпретатор
-
програма, яка виконує код мовою програмування, перекладаючи його на машинні команди без попередньої компіляції. У контексті мови
Python, програма, яка виконуєPython-код, перетворюючи його на машинні команди без попередньої компіляції у виконуваний файл. Інтерпретатор читає код рядок за рядком, аналізує та виконує його. УPythonосновними інтерпретаторами єCPython(стандартна реалізація),PyPy,Jythonта інші. - Ітератор
-
об’єкт, що дозволяє перебирати усі елементи послідовності один за одним. Ітератори реалізують методи
__iter__()і__next__(). - Ітерація
-
один крок циклу.
- Клас
-
шаблон для створення об’єктів, який об’єднує дані (змінні) і методи (функції), що визначають поведінку цих об’єктів.
- Кортеж (
tuple) -
впорядкована незмінна послідовність елементів, яка може містити дані різних типів.
- Множина (
set) -
контейнер, що зберігає унікальні елементи без дотримання порядку. Елементами множини можуть бути лише незмінні типи даних: числа, рядки, кортежі.
- Мова програмування
-
мова, яка використовується для запису алгоритмів, призначених для виконання комп’ютером.
- Модуль
-
файл з розширенням
.py, який містить код наPython. Функціонально, модуль не відрізняється від звичайного файлуPython, але він призначений для повторного використання функцій, класів або змінних у різних частинах програми.Pythonмає багато вбудованих модулів, таких якmath,os, які доступні одразу після встановленняPython. Якщо файл використовується як модуль, його код виконується лише під час імпорту, але тільки один раз. - Налагоджувач (англ. debugger)
-
комп’ютерна програма, яка використовується для тестування і виправлення помилок інших програм.
- Об’єкт
-
є окремою одиницею сховища даних під час роботи програм, яке використовується як базовий елемент побудови програм.
- Операнд
-
аргумент операції; дані, які обробляються командою; граматична конструкція, яка позначає вираз, що задає значення аргументу операції.
- Оператор
-
виконує дію над операндами.
- Пакет
-
дозволяє згрупувати колекцію модулів під загальним ім’ям. Цей прийом дозволяє вирішити проблему конфліктів імен між іменами модулів, які використовуються у різних застосунках.
- Початковий код (англ. source code)
-
будь-який набір інструкцій або оголошень, написаних мовою програмування у формі, що її може прочитати і модифікувати людина.
- Програма
-
набір команд (вказівок, інструкцій), призначений для виконання комп’ютером у певній послідовності. Такий набір інструкцій називається початковим кодом.
- Програміст
-
фахівець, який пише та розробляє комп’ютерні програми для розв’язання різноманітних завдань.
- Програмування
-
передання комп’ютеру інструкцій, які вказують йому щось зробити. Наприклад, обчислити математичний вираз, змінити текст, здійснити пошук інформації у файлах або виконати обмін даними з іншими комп’ютерами через мережу Інтернет тощо.
- Простори імен (
namespaces) -
механізм для ізоляції імен об’єктів у програмі, щоб уникнути конфліктів між об’єктами з однаковими іменами.
- Псевдокод
-
неформальний запис алгоритму, який використовує структуру поширених мов програмування, але нехтує деталями коду, неістотними для розуміння алгоритму (опис типів, виклик підпрограм тощо). Псевдокод є зрозумілішим, ніж програми, формою запису алгоритмів.
- Регулярні вирази (англ. regular expression)
-
рядок, що описує або збігається з множиною рядків, відповідно до набору спеціальних синтаксичних правил.
- Розгалуження
-
конструкція мови програмування, що забезпечує виконання/невиконання певної команди (набору команд) за умови істинності/хибності деякого логічного виразу.
- Скрипт (сценарій)
-
файл із кодом, написаним мовою програмування, який виконується послідовно як програма, зазвичай без попередньої компіляції. У контексті мови
Python, файл із розширенням.py, який містить код наPython, призначений для виконання безпосередньо після запуску. На відміну від модуля, скрипт зазвичай використовується для виконання конкретної задачі, а не для повторного використання коду в інших програмах. - Словник (
dict) -
структура даних, яка зберігає пари «ключ: значення» з унікальними ключами. Ключами можуть бути тільки незмінні об’єкти (числа, рядки, кортежі тощо), а доступ до елементів здійснюється через ключ, а не за індексом.
- Список (
list) -
послідовність елементів, розташованих у певному порядку. Доступ до елементів здійснюється за індексом. Значення елементів списку можна змінювати.
- Тип даних
-
визначає множину допустимих значень, формат їхнього збереження, розмір виділеної пам’яті та набір операцій, які можна виконати над ними.
- Функція
-
частина програми, яка реалізує певний алгоритм і дозволяє звернення до неї з різних частин головної програми; функція повертає результат і може використовуватись як частина виразу.
- Цикл
-
будь-яка багатократно виконувана послідовність інструкцій.
Додаток A: Завантаження і встановлення Python
A.1. для Windows
Для встановлення Python, виконайте наступні дії:
Для операційної системи Windows XP остання підтримувана версія Python 3.4.4.
|
-
З’ясуйте розрядність вашої операційної системи.
-
Перейдіть на сайт https://www.python.org/downloads/ .
-
Оберіть версію
Python. -
Завантажте файл з розширенням
.exeвідповідної розрядності. -
Встановіть
Python:-
відзначте рекомендований параметр
Install launcher for all users -
не забудьте встановити прапорець
Add Python 3.x to PATH(це полегшить правильне налаштування системи) -
оберіть варіант налаштування установки
Customize installation -
вкажіть каталог установки
C:\PythonX(деX- номер версії)
-
Перевіримо, чи Python успішно був встановлений на комп’ютер.
Для цього натисніть сполучення клавіш Win+R на клавіатурі, введіть команду cmd і натисніть OK. У консольному вікні, що з’явилося, введіть команду python --version і натисніть Enter:
> python --version
Python 3.9.0Якщо ви отримали схожий результат, то Python відповідної версії успішно встановлений у вашій системі.
A.2. для Linux Ubuntu
У Linux-системи Python вже включений за замовчуванням. Перевіримо встановлену версію мови. Натисніть сполучення клавіш Ctrl+Alt+T на клавіатурі для виклику термінального вікна, введіть наступну команду і перегляньте результати її виконання:
$ python3 --version
Python 3.8.2Якщо необхідно встановити іншу версію, наприклад, Python 3.9, виконайте в термінальному вікні наступні команди:
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.9Для запуску в термінальному сеансі інтерактивного режиму конкретної версії інтерпретатора, наприклад, Python 3.9, введіть команду:
python3.9Додаток B: Налаштування середовища програмування
B.1. IDLE
Після встановлення Python у системі Windows інтерпретатор Python з’явиться у списку програм кнопки Пуск. Один з елементів у групі програм має назву IDLE - це інтегроване середовище, яке відразу готове для роботи (більшість налаштувань вже виконано за замовчуванням).
Для встановлення IDLE у Linux Ubuntu для конкретної версії Python 3 слід виконати команду, на зразок:
sudo apt install idle-python3.9
Для запуску IDLE через термінал Linux Ubuntu використовуйте команду, на зразок idle-python3.9.
|
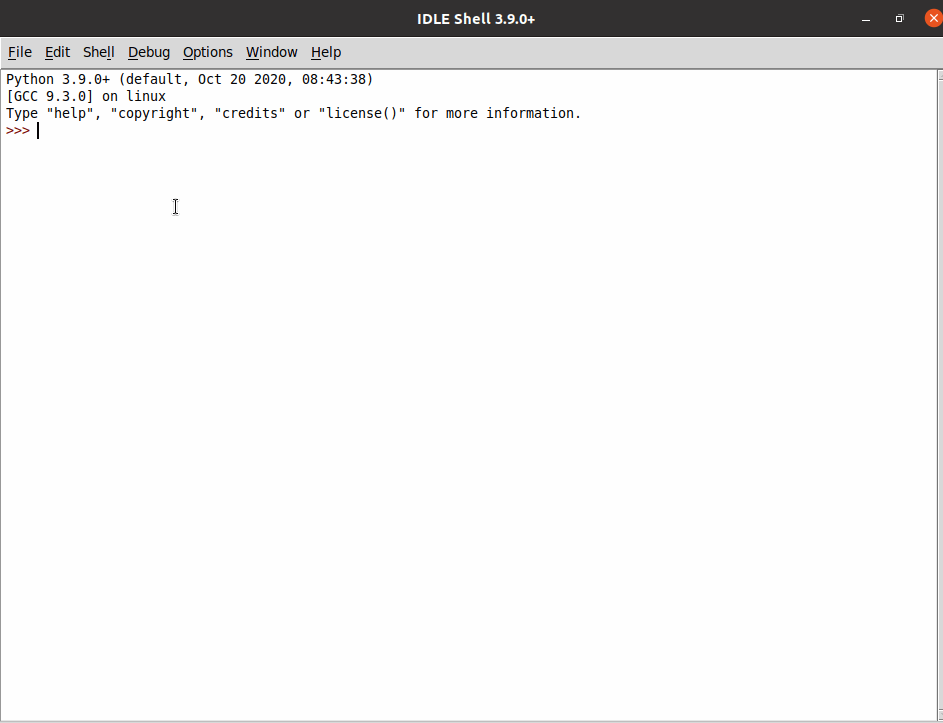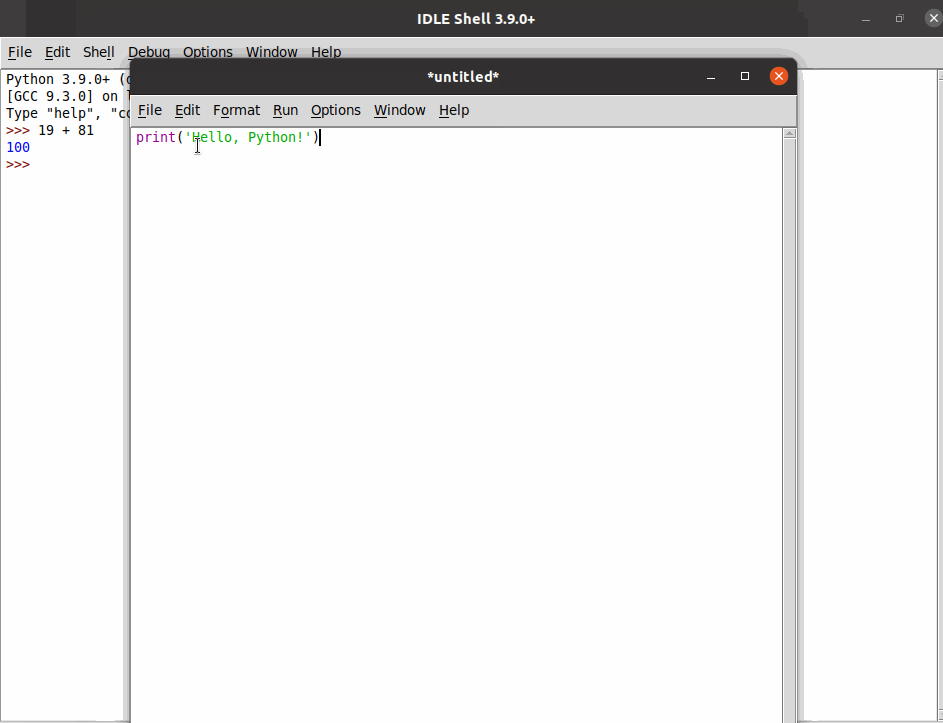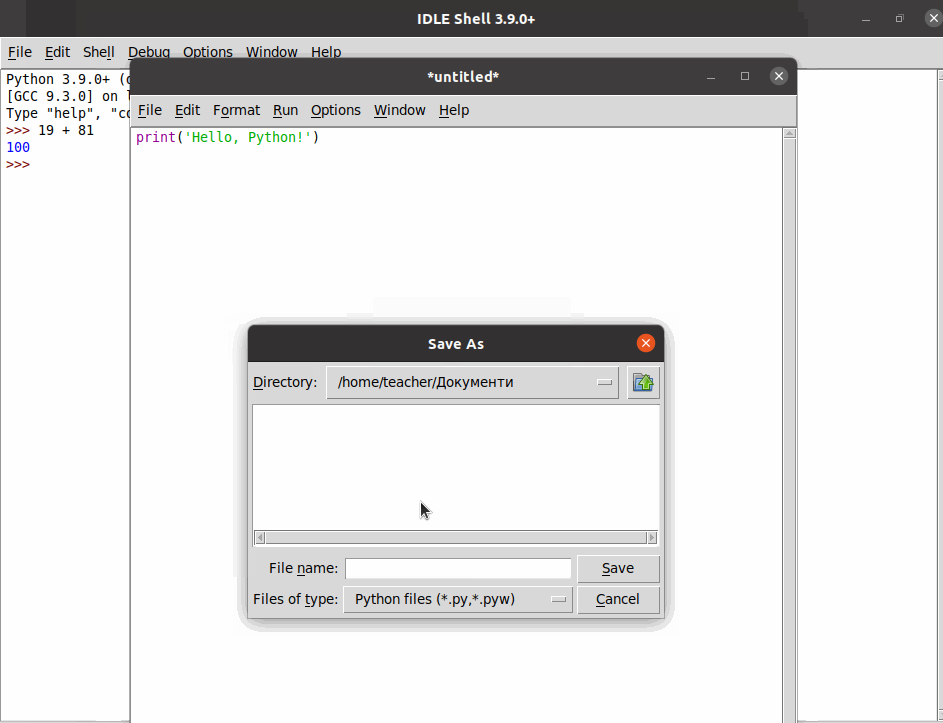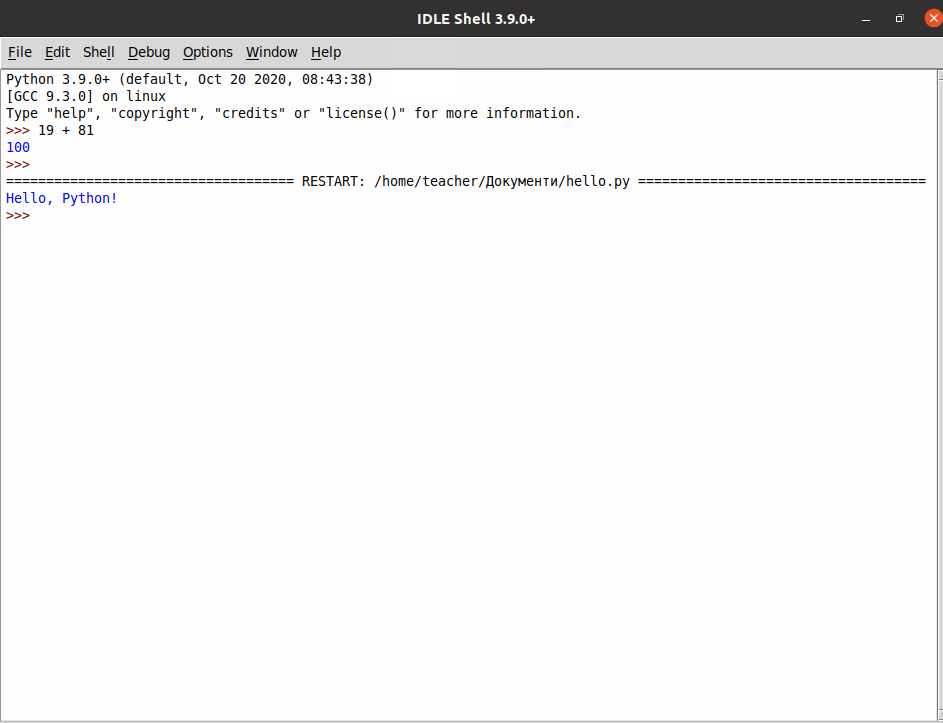
B.2. Notepad++
Завантажте текстовий редактор з офіційного сайту Notepad++ і встановіть програму стандартним способом. Виконайте початкові налаштування для вашої версії інтерпретатора Python, переглянувши анімацію.
Для запуску ваших програм використовуйте команду або клавішу F6.
Щоб консоль Notepad++ «працювала» в режимі UTF-8, у вікні Python додайте рядок env_set PYTHONIOENCODING=utf-8, а у вікні параметрів UTF-8.
|
B.3. Visual Studio Code
Завантажте IDE з офіційного сайту Visual Studio Code і встановіть стандартним способом для вашої операційної системи. Для зручного запуску коду на Python у Visual Studio Code можна встановити розширення, представлені в анімації.
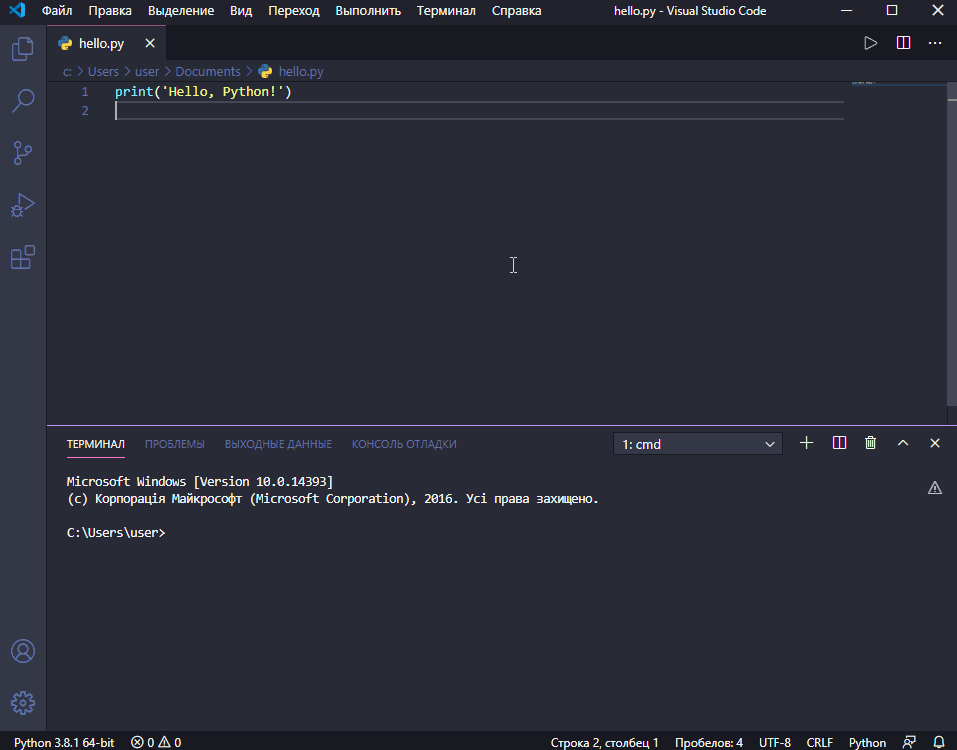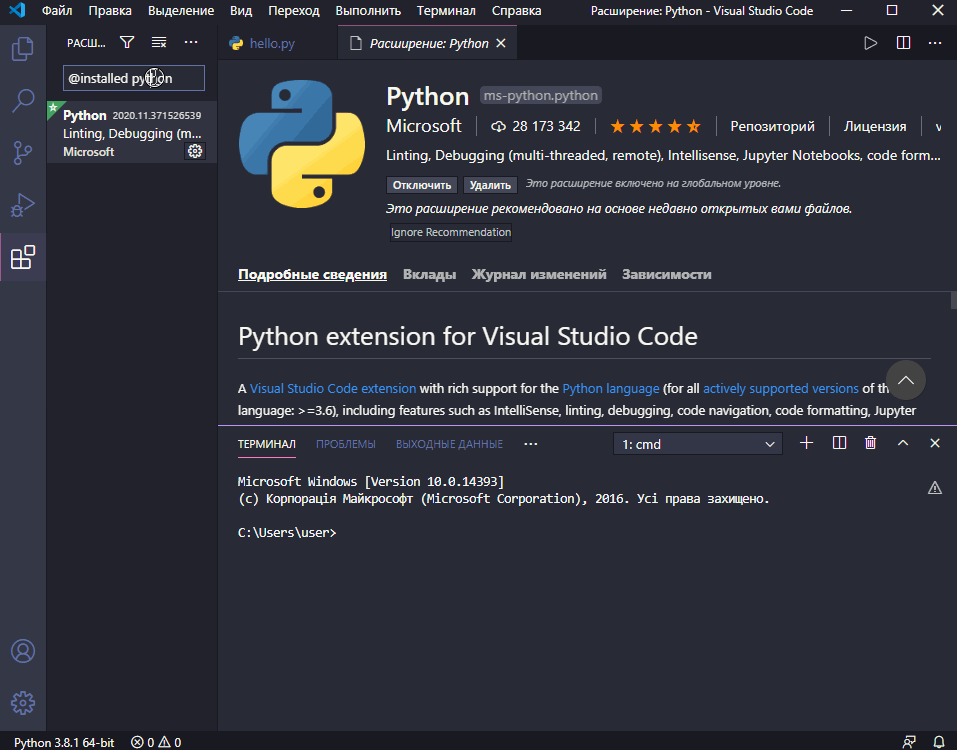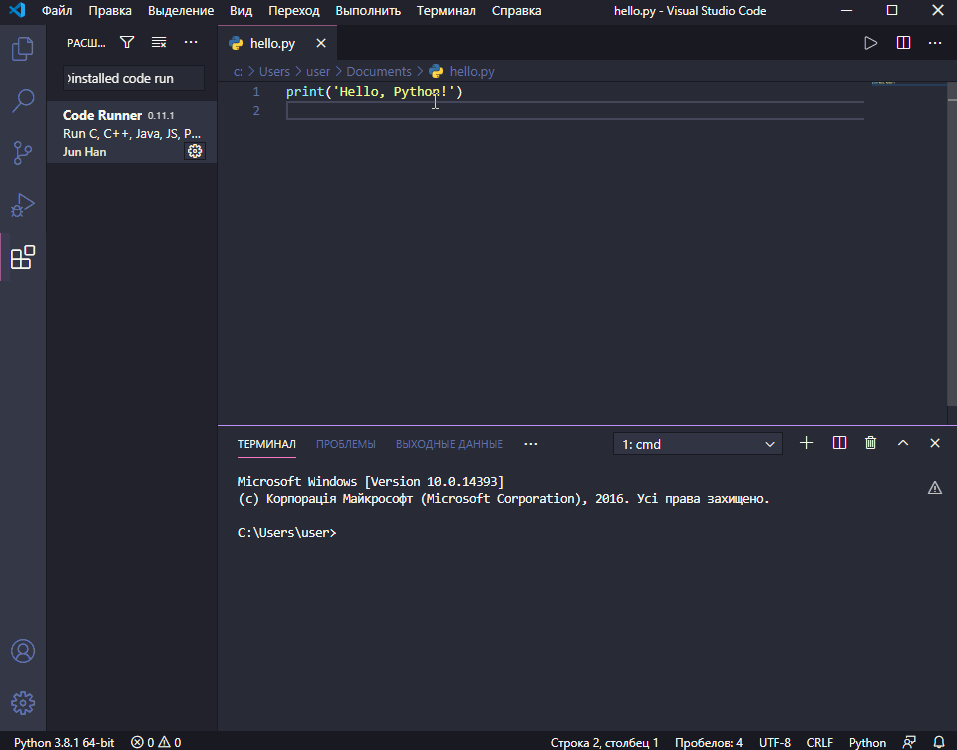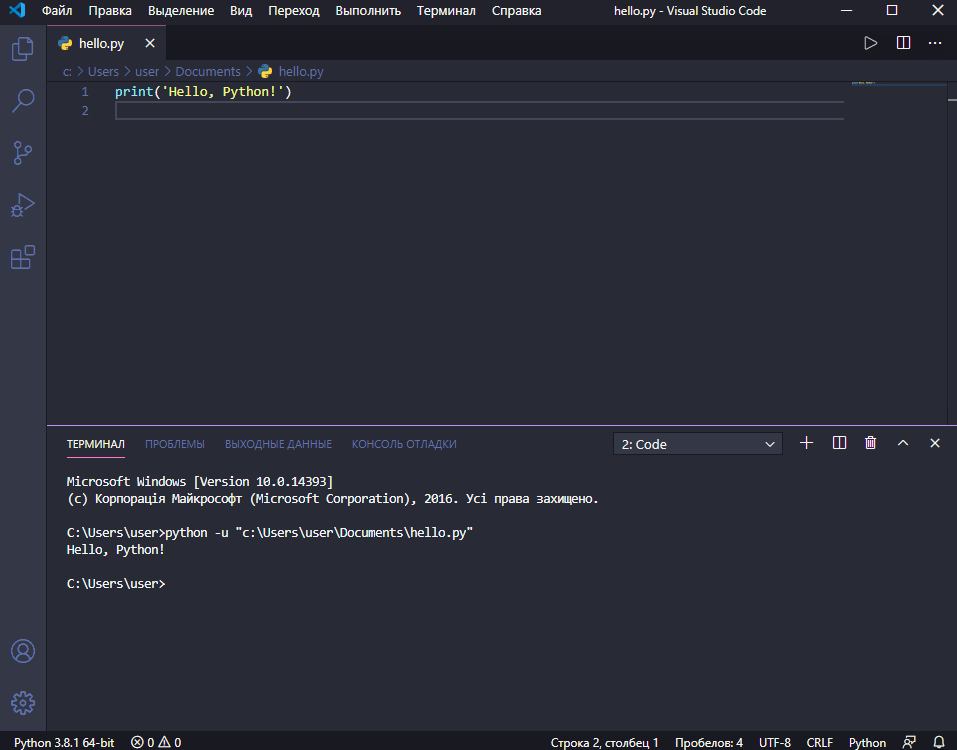
Для запуску ваших програм використовуйте сполучення клавіш Ctrl+Alt+N.
B.4. PyScripter
Завантажте IDE із офіційного сайту PyScripter (оберіть розрядність, що відповідає розрядності інтерпретатора Python, встановленого на вашому комп’ютері) і встановіть програму. Виконайте початкові налаштування, переглянувши анімацію.
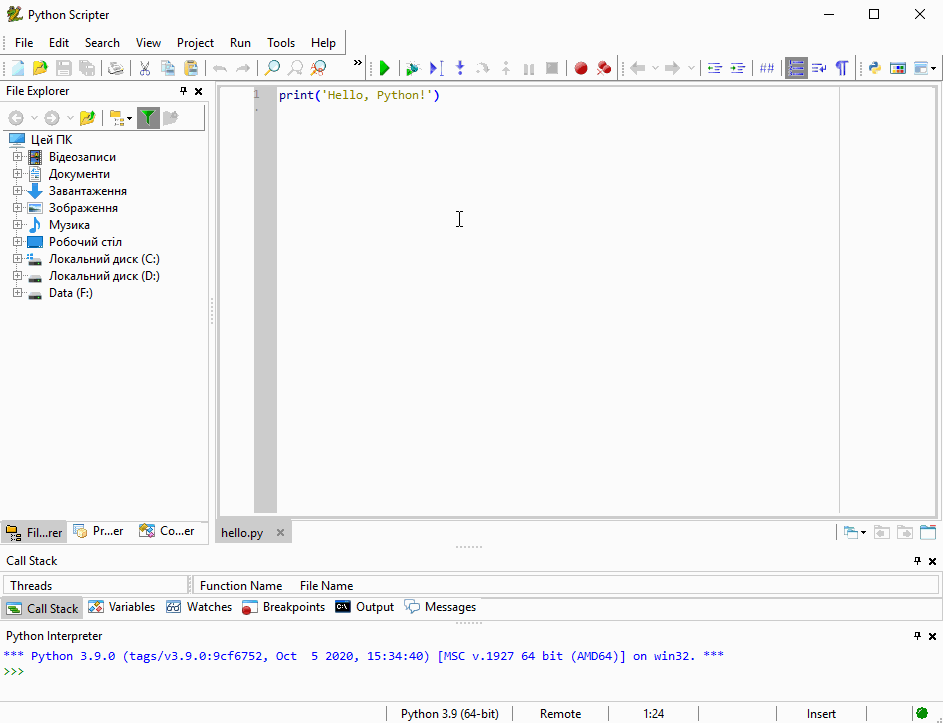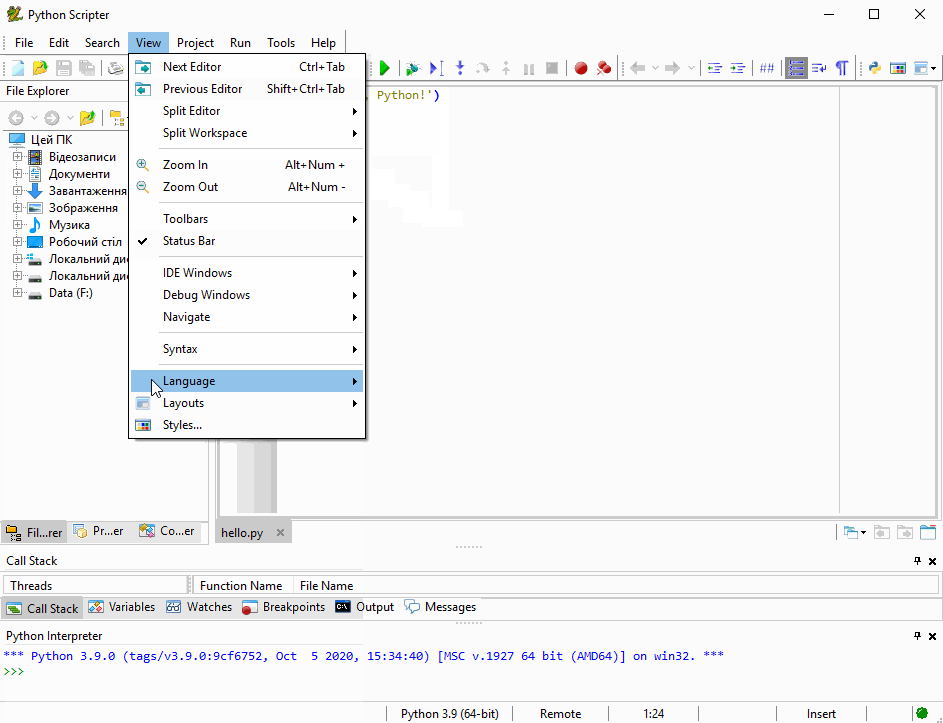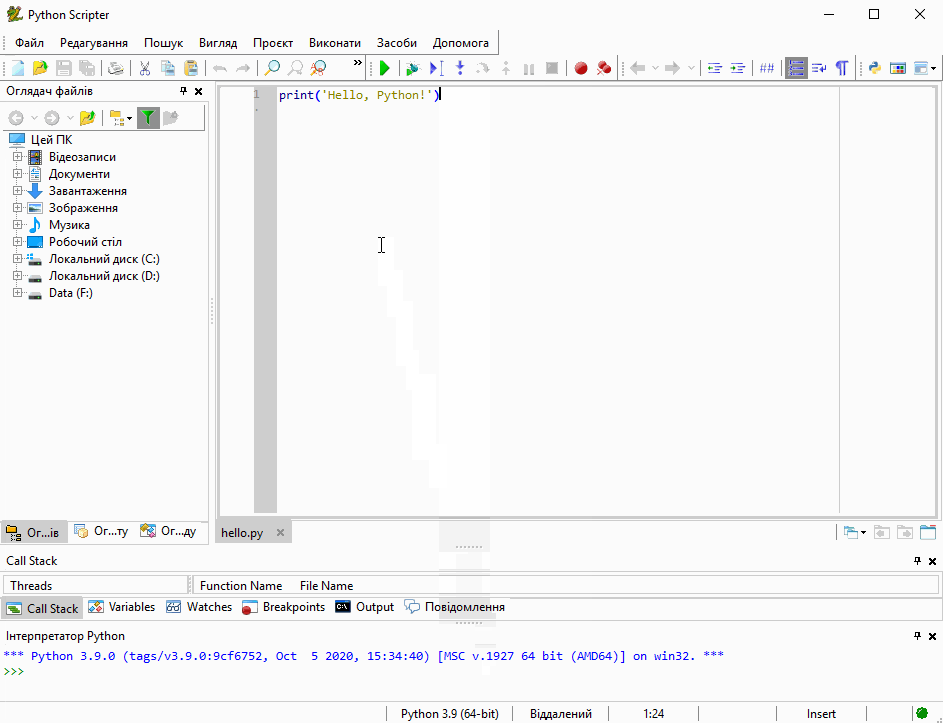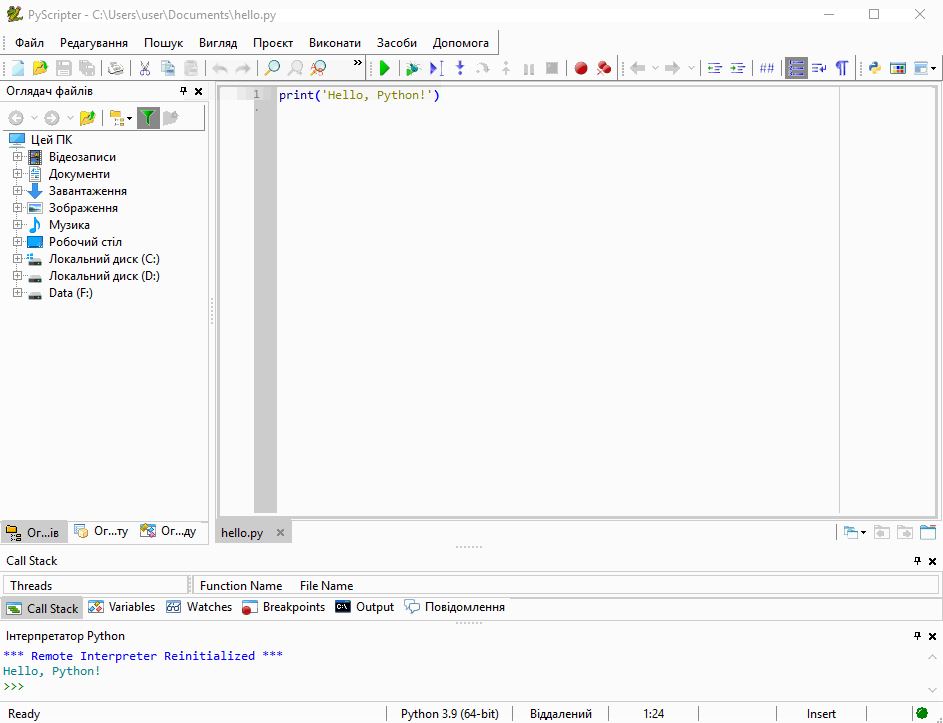
Для запуску ваших програм використовуйте сполучення клавіш Ctrl+F9.
B.5. Wing IDE 101
Завантажте IDE із офіційного сайту Wing IDE 101 і встановіть програму стандартним способом для вашої операційної системи. Виконайте початкові налаштування, переглянувши анімацію.
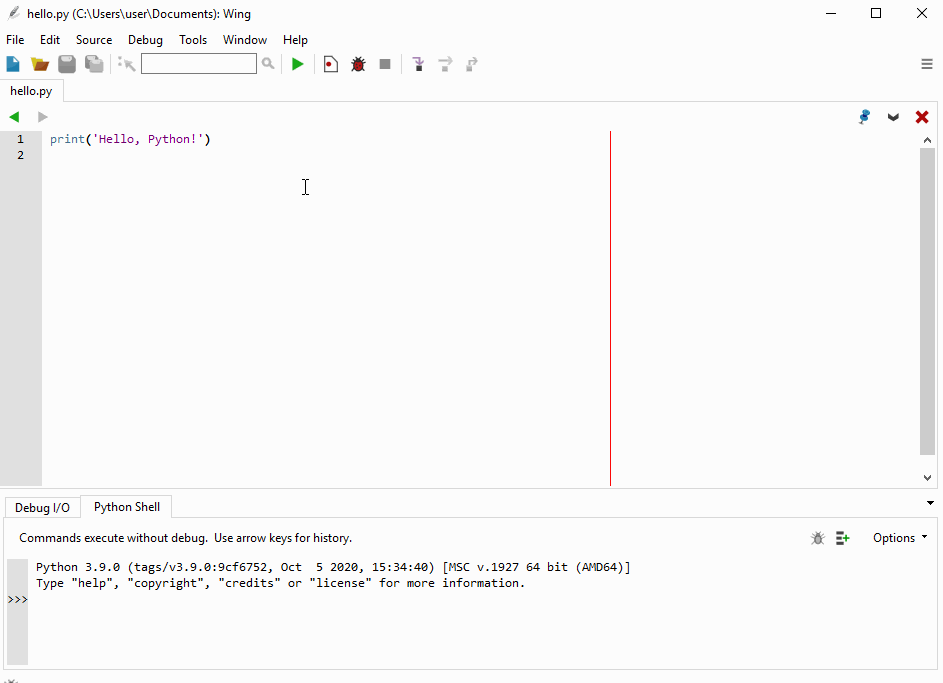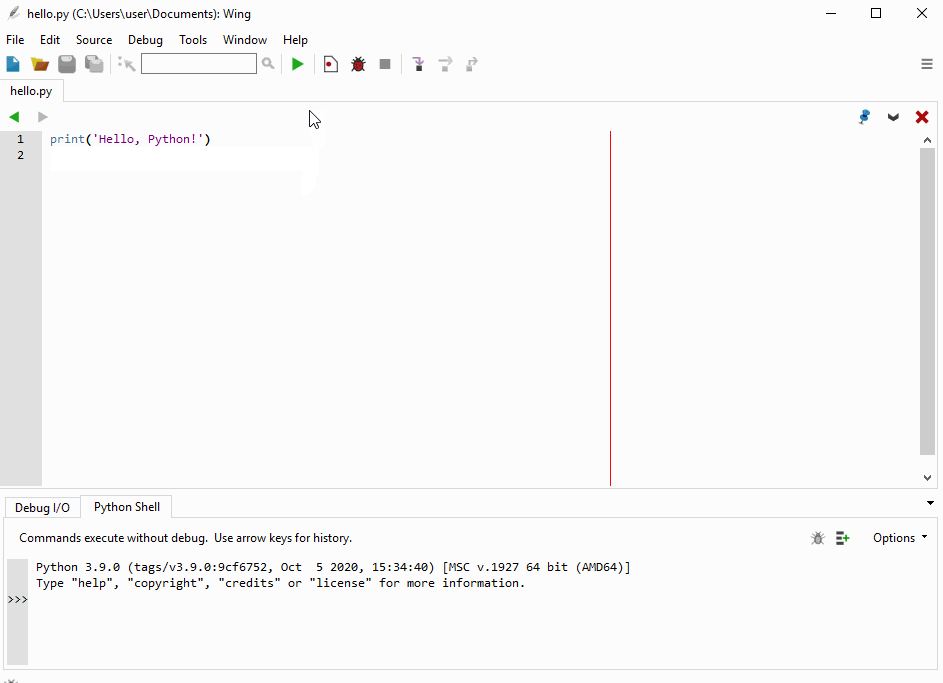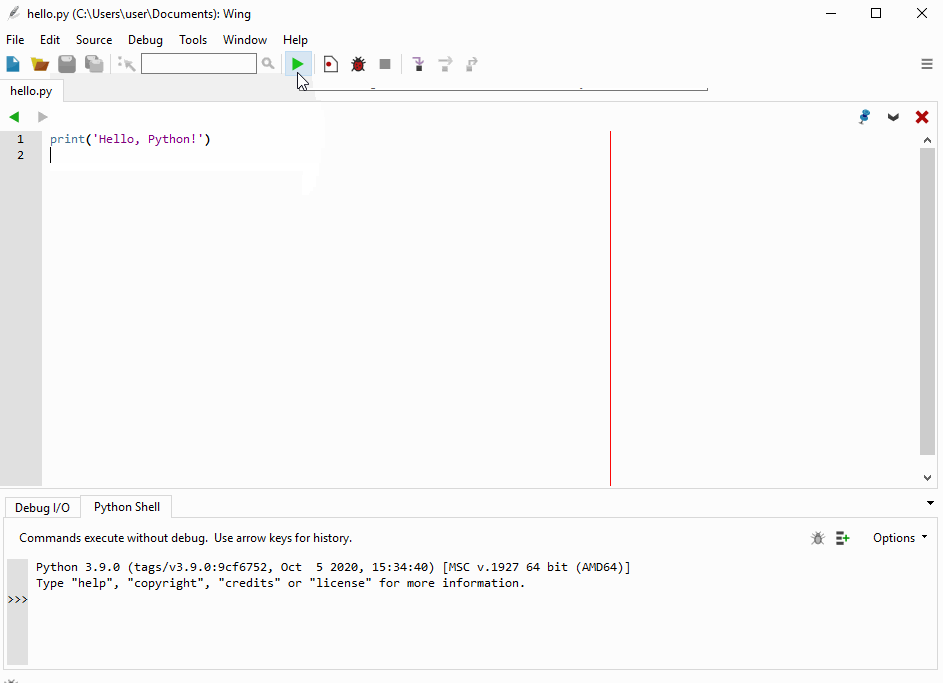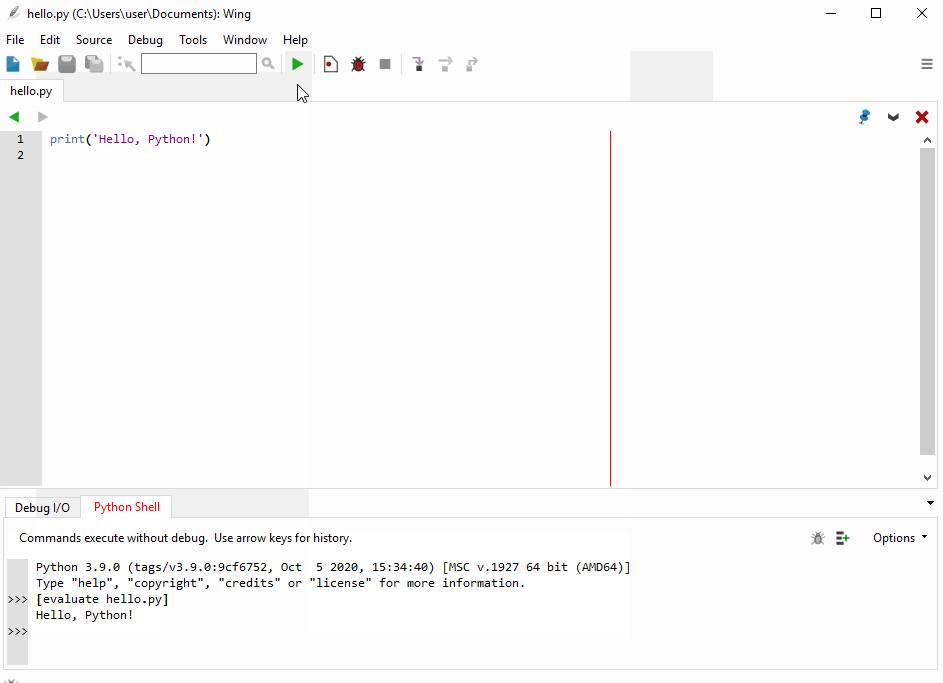
Для запуску програм використовуйте сполучення клавіш Ctrl+Alt+V.
B.6. Geany
Якщо ви використовуєте Windows, завантажте редактор із офіційного сайту Geany і встановіть програму. Перегляньте анімацію про використання Geany.
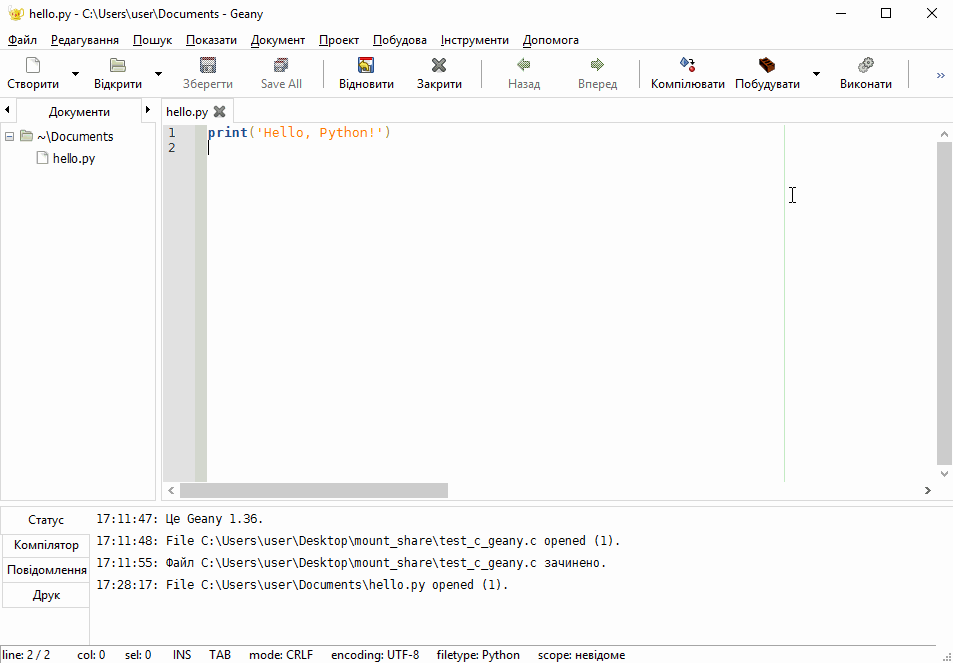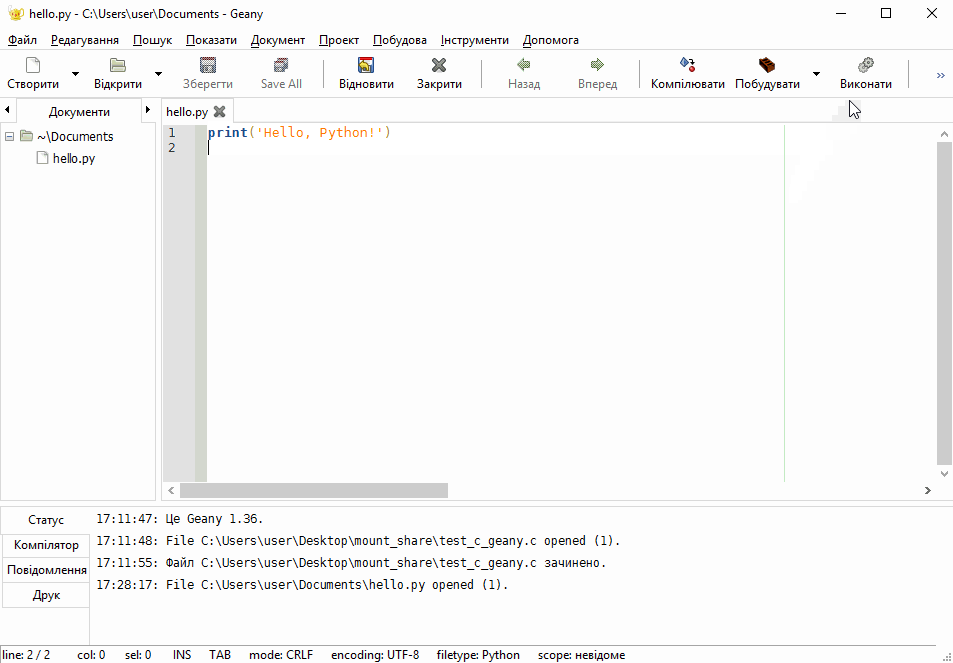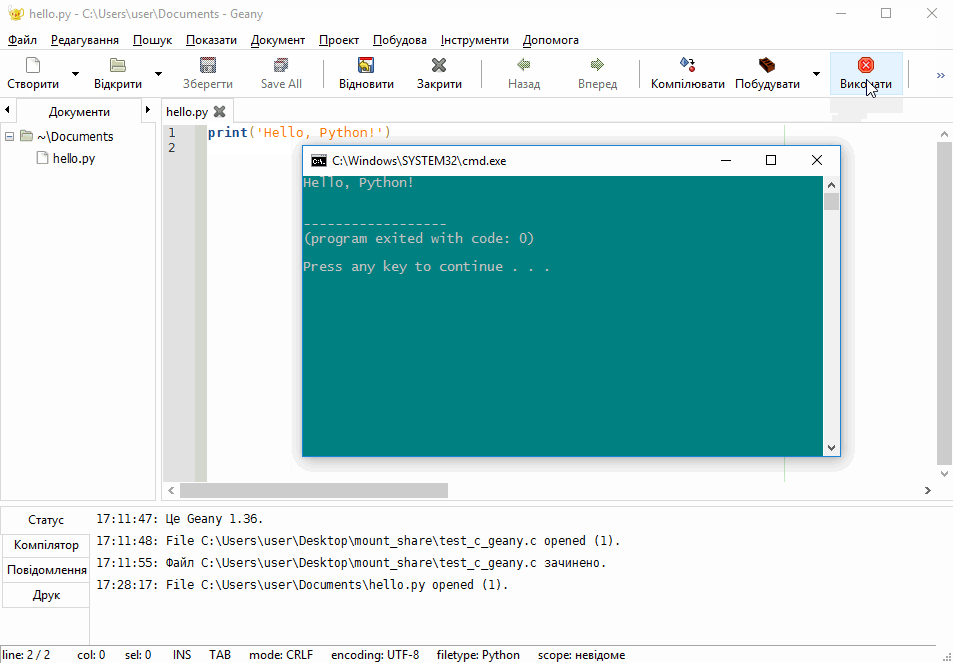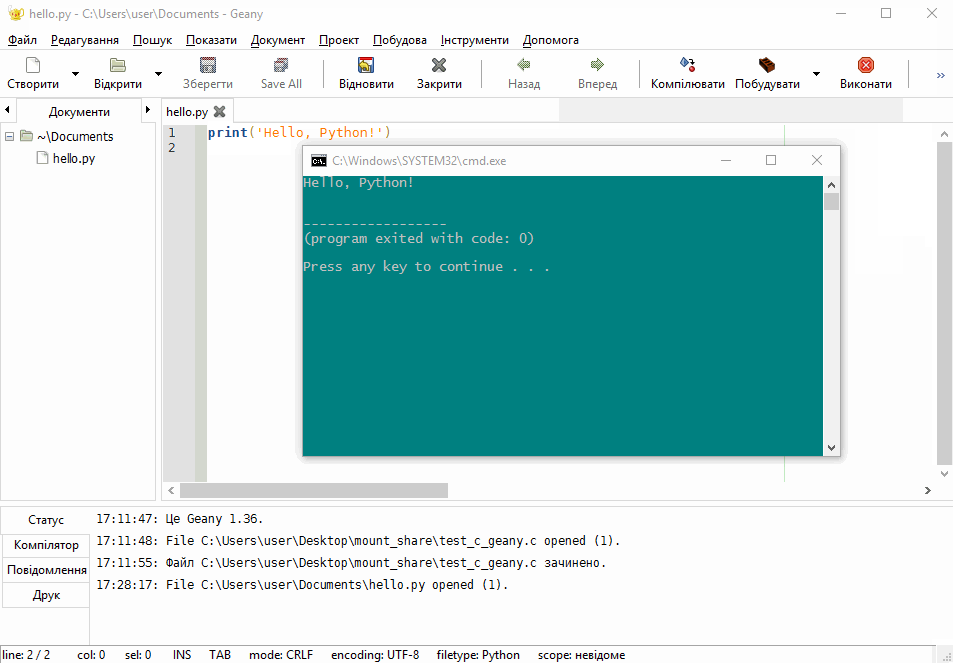
Якщо ви використовуєте Linux Ubuntu, відкрийте вікно терміналу сполученням клавіш Ctrl+Alt+T і виконайте послідовно команди для встановлення Geany:
sudo add-apt-repository ppa:geany-dev/ppa
sudo apt update
sudo apt install geanyДля запуску редактора Geany, в термінальному вікні виконайте команду
geanyі вкажіть для Geany встановлену на комп’ютері версію Python, як показано в анімації.
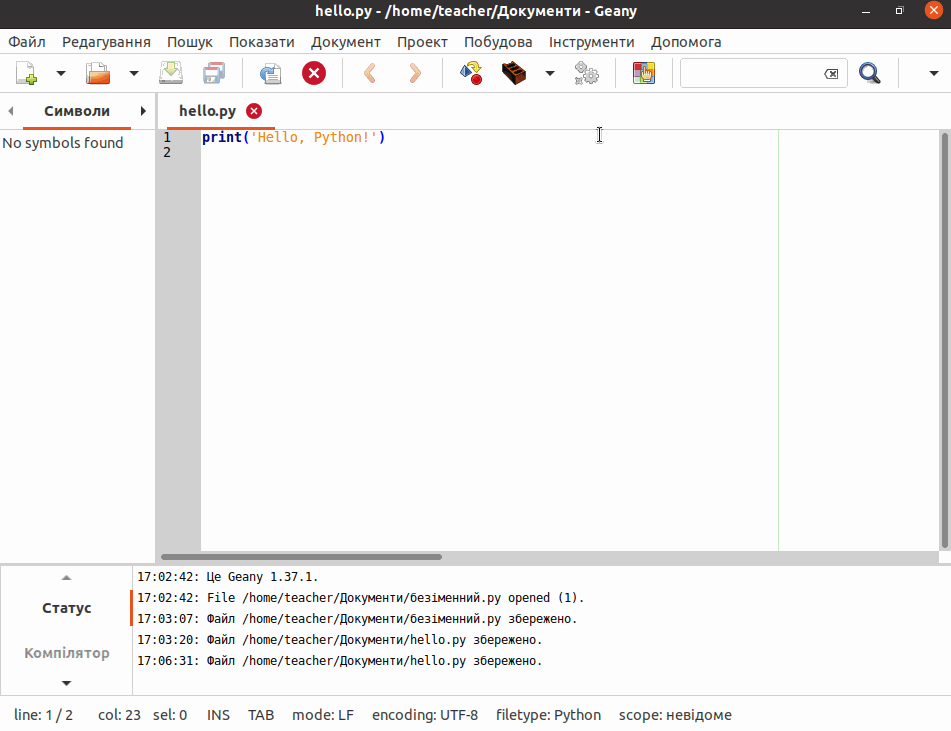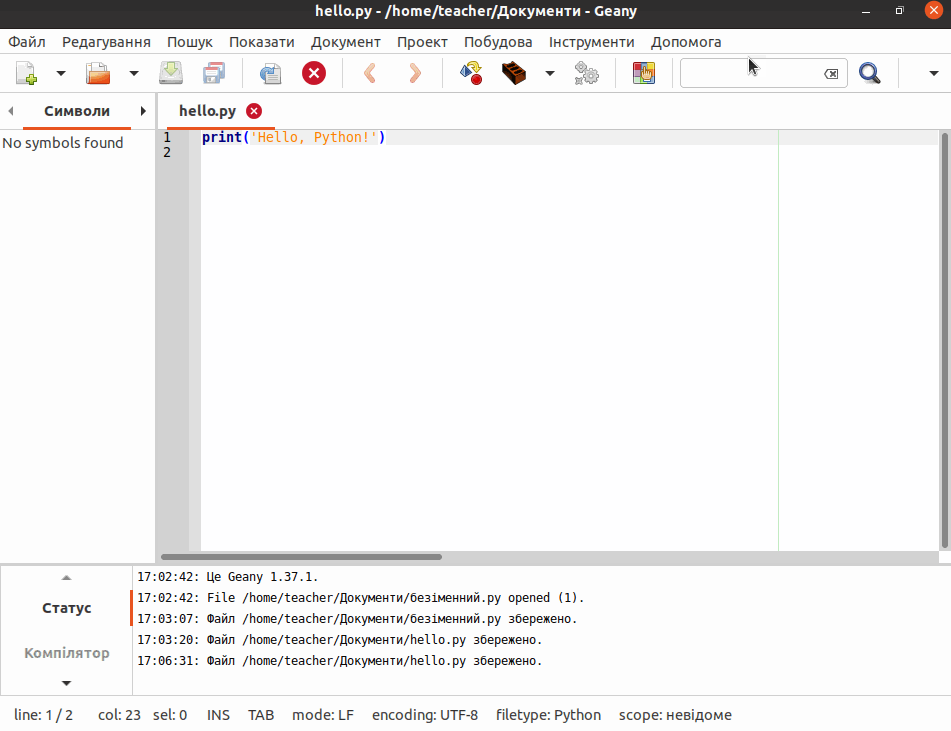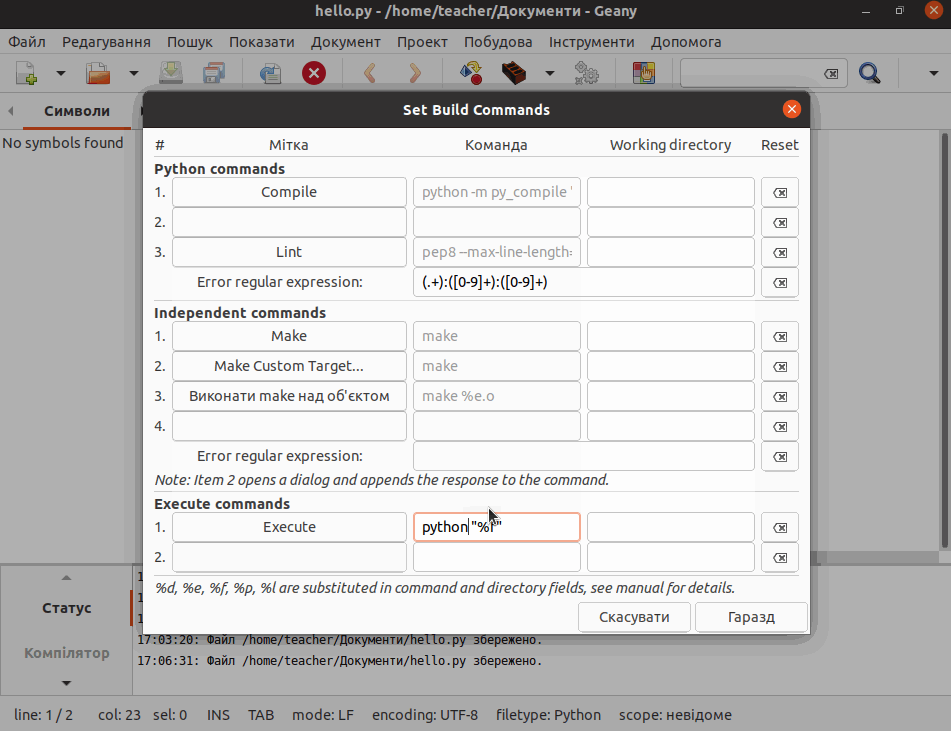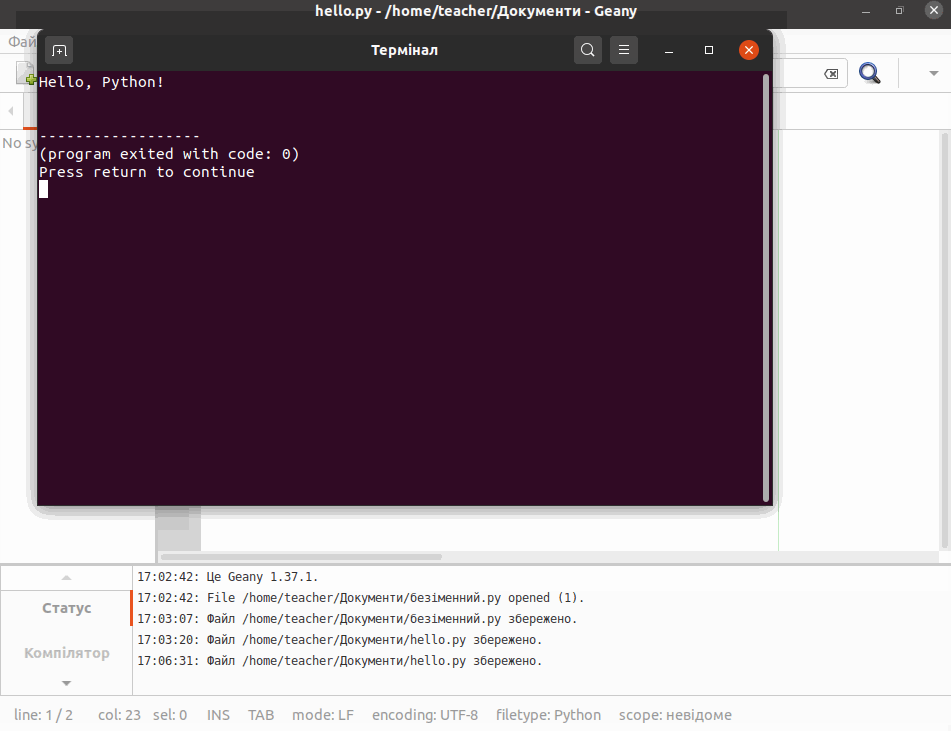
Для запуску програм використовуйте клавішу F5.
B.7. PyCharm
Для встановлення, запуску і налаштування PyCharm використовуйте інструкцію (англ.) на офіційному сайті.
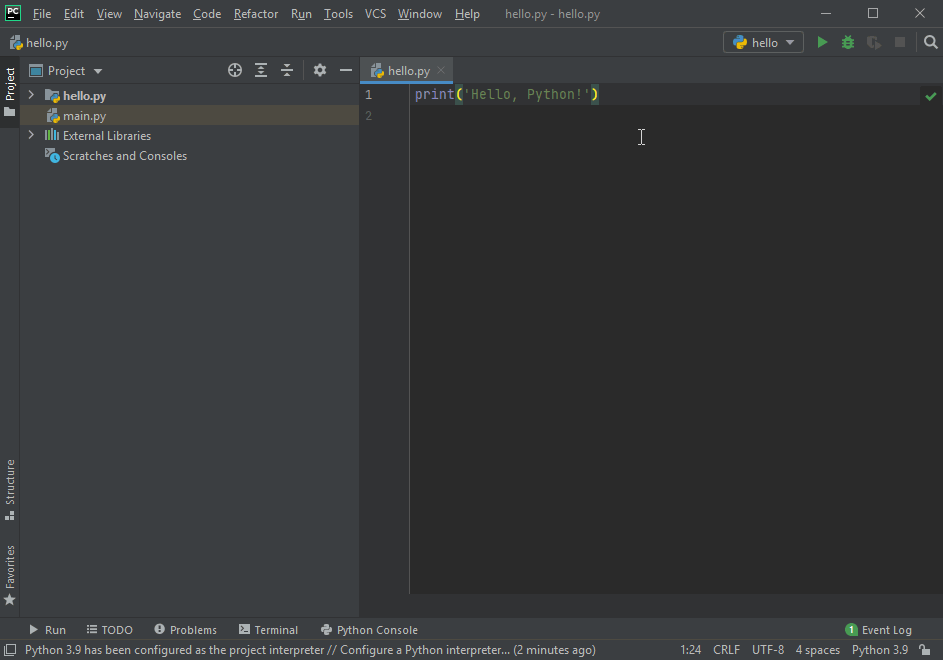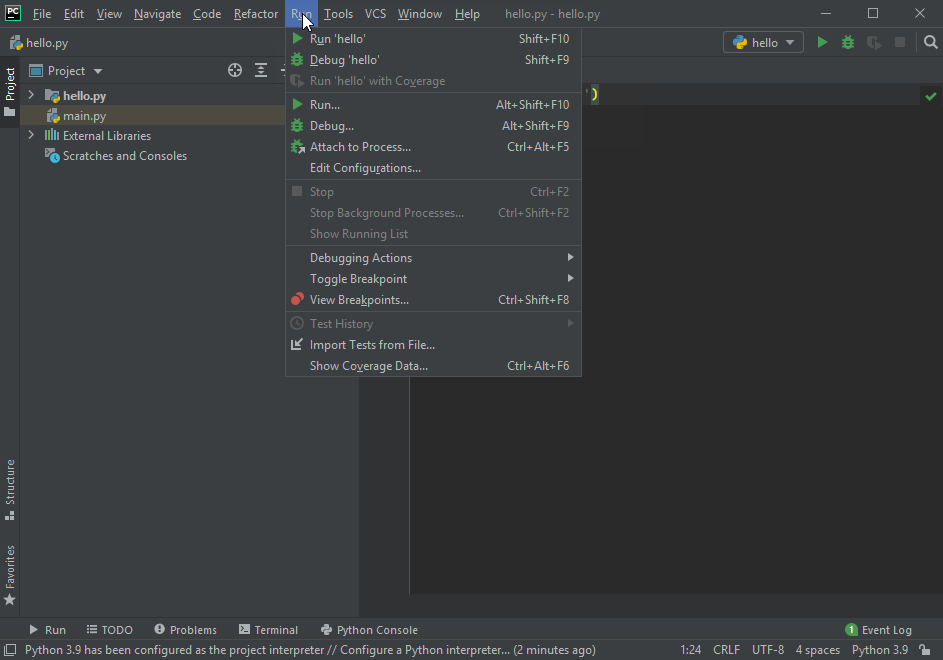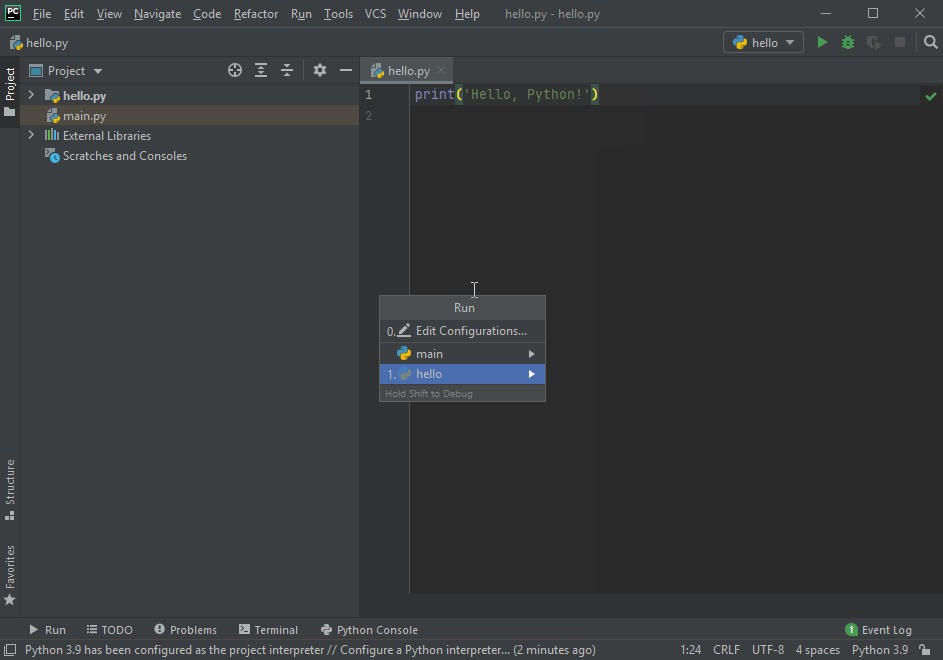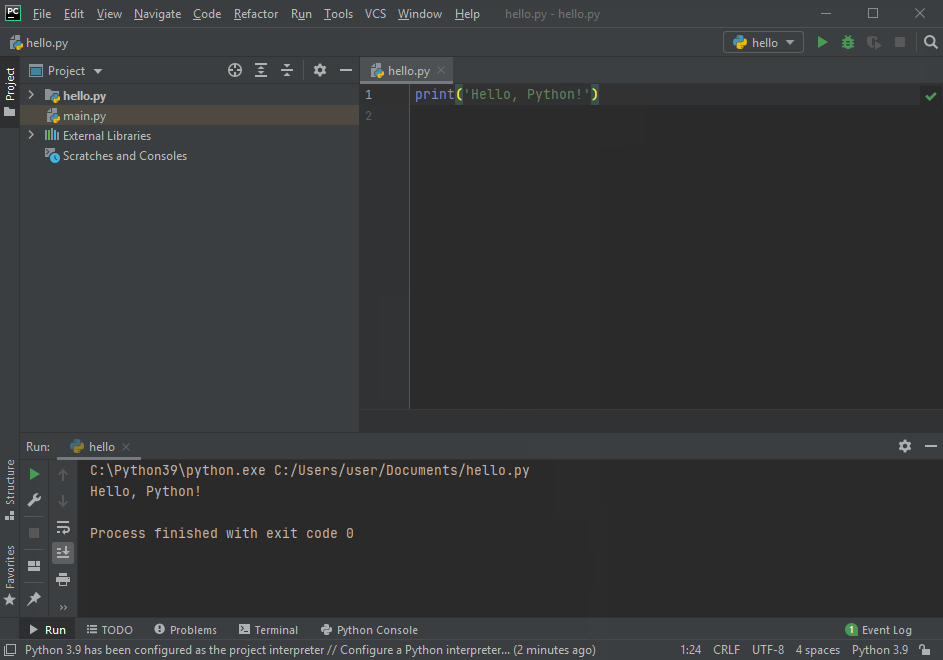
Додаток C: Довідкові таблиці
C.1. Зарезервовані слова Python
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C.2. Пріоритет операторів
| На практиці краще використовувати дужки для групування операторів і операндів, щоб в явному вигляді вказати порядок обчислення виразів. |
| Оператори із більш високим пріоритетом розташовуються у таблиці вище. |
|
Вираз в дужках, створення або включення списку/словника/множини |
|
Індекс, зріз, виклик функції, посилання на атрибут |
|
Піднесення до степеня |
|
Знаки |
|
Множення, ділення з рухомою крапкою, цілочисельне ділення, остача від ділення |
|
Додавання, віднімання |
|
Бітові зсуви |
|
Бітове І |
|
Бітове АБО |
|
Бітове виключення АБО |
|
Перевірка на приналежність і рівність |
|
Булеве (логічне) НІ |
|
Булеве (логічне) І |
|
Булеве (логічне) АБО |
|
Умовний вираз |
|
Лямбда-вираз |
C.3. Таблиці істинності
| Вираз | Результат |
|---|---|
|
|
|
|
|
|
|
|
| Вираз | Результат |
|---|---|
|
|
|
|
|
|
|
|
| Вираз | Результат |
|---|---|
|
|
|
|
C.4. Стандартні функції Python
Розширений список стандартних функцій Python і приклади їх використання можна переглянути на офіційному сайті документації Python або на programiz.com .
|
| Виклик функції | Опис |
|---|---|
|
Документація об’єкта |
|
Список імен/атрибутів об’єкта |
|
Тип об’єкта |
|
Ідентифікатор (адреса в пам’яті) об’єкта |
|
Виведення |
|
Відкриття файла |
|
Зчитування і повертання рядка |
|
Відформатоване подання рядка |
|
Значення хеш-функції об’єкта |
|
Перетворення об’єкта |
|
Перетворення об’єкта |
|
Перетворення об’єкта |
|
Повертає символ (у вигляді рядка), чия позиція коду для Юнікод дорівнює зазначеному цілому |
|
Повертає для зазначеного Юнікод-символу ціле число, що представляє його позицію коду |
|
Найближче ціле число до числа |
|
Абсолютне значення |
|
Піднесення числа |
|
Мінімальний елемент в ітерованому |
|
Максимальний елемент в ітерованому |
|
Сума елементів в ітерованому |
|
Довжина ітерованого |
|
Новий ітерований об’єкт, що містить елементи |
|
Новий ітерований об’єкт, що містить елементи |
|
Новий кортеж |
|
Новий список |
|
Нова множина |
|
Новий ітерований об’єкт, який містить числа від |
C.5. Модулі Python
Перед використанням функцій модуля необхідно його імпортувати таким чином: import назва_модуля .
|
Для використання функцій модуля необхідно використовувати такий запис: назва_модуля.назва_функції .
|
C.5.1. math
| Виклик функції/константи | Опис/значення |
|---|---|
|
Синус |
|
Косинус |
|
Перетворення |
|
Перетворення |
|
Експонентна функція |
|
Квадратний корінь |
|
Факторіал цілого числа |
|
|
|
|
C.5.2. string
| Атрибут | Значення |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C.5.3. random
| Виклик функції | Опис |
|---|---|
|
Випадкове ціле число із діапазону від |
|
Випадкове ціле число |
|
Випадковий елемент непорожньої послідовності |
|
Cписок довжиною |
|
Випадкове число від |
C.6. Методи
Розширений список методів Python і приклади їх використання можна переглянути на programiz.com .
|
C.6.1. Рядки
| Метод | Призначення |
|---|---|
|
Повертає копію рядка |
|
Повертає копію рядка |
|
Повертає копію рядка |
|
Повертає копію рядка |
|
Повертає копію рядка |
|
Для рядка |
|
Повертає найменший індекс з рядка |
|
Повертає найменший індекс з рядка |
|
Повертає найбільший індекс з рядка |
|
Повертає найбільший індекс з рядка |
|
Повертає копію рядка |
|
Повертає |
|
Повертає |
|
Повертає рядок, складений з елементів ітеративного об’єкта |
|
повертає копію рядка |
|
повертає копію рядка |
|
повертає копію рядка |
|
Розділення рядка |
|
Повертає відцентрований рядок, по краях якого стоїть символ |
|
Робить довжину рядка |
|
Робить довжину рядка |
|
Чи складається рядок |
|
Чи складається рядок |
|
Чи складається рядок |
|
Чи починаються слова в рядку |
|
Чи складається рядок |
|
Чи складається рядок |
C.6.2. Списки
| Метод | Призначення |
|---|---|
|
Додає елемент |
|
Розширює список |
|
Вставляє у списку |
|
Видаляє перший елемент у списку |
|
Видаляє із списку |
|
Повертає положення у списку |
|
Повертає кількість елементів із списку |
|
Сортує елементи списку |
|
Розвертає список |
|
Поверхнева копія списку |
|
Очищає список |
C.6.3. Словники
| Метод | Призначення |
|---|---|
|
Очистити словник |
|
Повертає копію словника |
|
Cтворює словник |
|
Повертає значення ключа із словника |
|
Повертає пари (ключ, значення) із словника |
|
Повертає ключі словника |
|
Видаляє ключ і повертає значення словника |
|
Видаляє і повертає пару (ключ, значення) словника |
|
Повертає значення ключа словника |
|
Оновлює словник |
|
Повертає значення із словника |
Додаток D: Код не працює: типові помилки
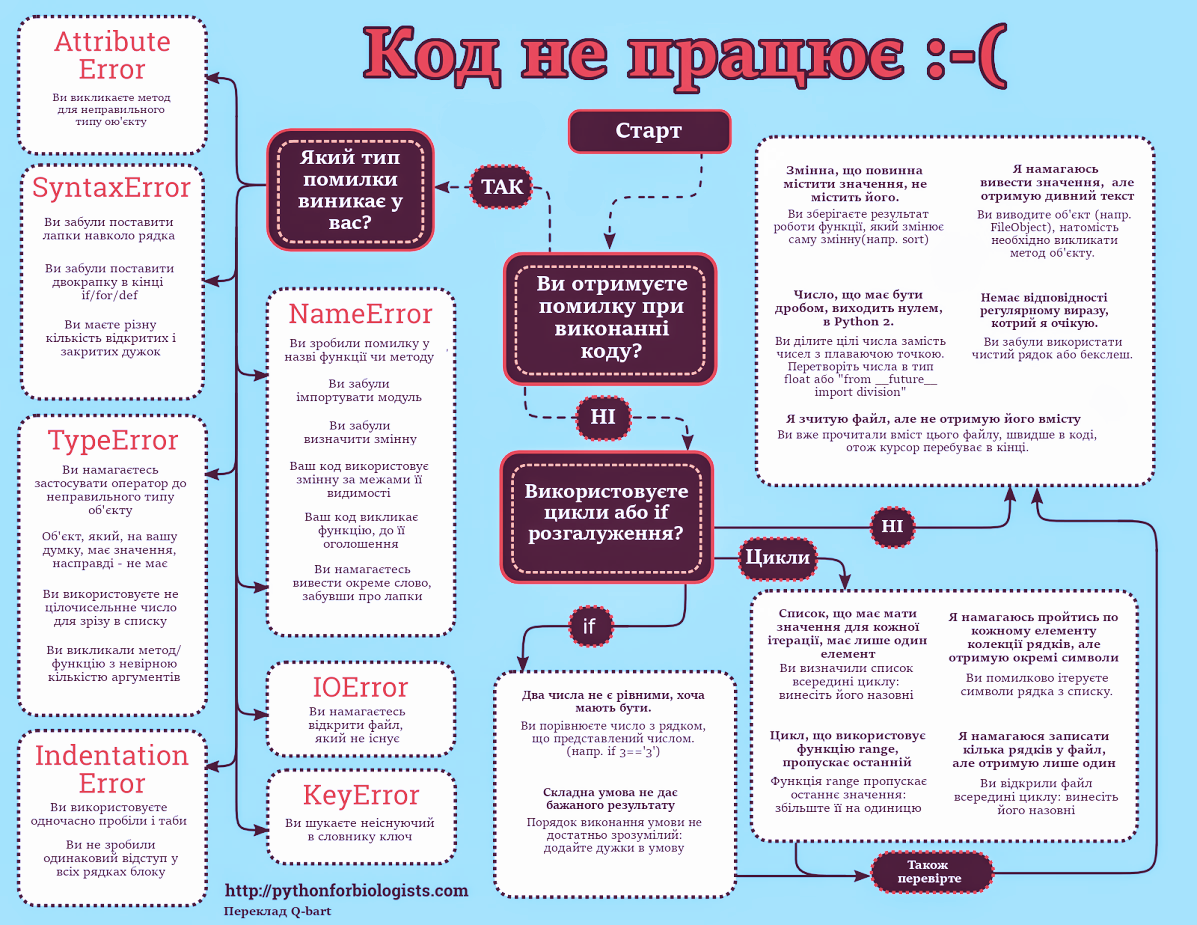
Додаток E: Налагодження і тестування коду
Налагодження і тестування коду - два важливих процеси для забезпечення якості написаної програми.
Налагодження (англ. debugging) - це процес виявлення, усунення і виправлення помилок (багів) у програмному коді.
|
Зазвичай налагодження необхідне, коли програма працює неправильно або видає непередбачувані результати. Налагодження дозволяє зрозуміти, чому програма не працює так, як очікується, і виправити ці проблеми.
Для налагодження застосовують відлагоджувачі - спеціальні програми, які зазвичай інтегровані в середовища розробки. Відлагоджувачі дозволяють по кроках проходити через код, спостерігаючи значення змінних, умови, виклики функцій тощо.
Мова Python також має вбудовані інструменти налагодження програм.
Найпростіший спосіб провести налагодження програми, написаної на Python, - додати інструкції print().
За допомогою print() можна надрукувати значення змінних чи повідомлення, щоб зрозуміти, як працює код на різних етапах виконання.
Наприклад, ви можете вставити рядки з print() в ключові місця коду
def divide(a, b):
print(f'Перед діленням: a = {a}, b = {b}')
return a / b
result = divide(10, 2)
print(result)щоб перевірити, які значення мають змінні на певному етапі виконання:
Перед діленням: a = 10, b = 2
5.0Цей спосіб підходить для простих програм, коли треба перевірити значення змінних або виконання певних ділянок коду. Після завершення налагодження рядки з print() можна вручну видалити або закоментувати.
Зручним інструментом для перевірки істинності умов в програмі є інструкція assert, синтаксис якої складається з:
-
умови - виразу, значення якого має бути істинним, щоб програма продовжила своє виконання;
-
повідомлення_про_помилку - необов’язкового тексту, який виводиться у разі, якщо значення виразу є хибним, а інтерпретатор
Pythonвикликає винятокAssertionError, що зупиняє виконання програми, відповідно.
assert умова, повідомлення_про_помилкуНаприклад, у коді
age = -1
assert age >= 0, "Вік не може бути від'ємним!"
print(f'Ваш вік: {age}')значення виразу age >= 0 є хибним, тому Python генерує виняток AssertionError і відбувається зупинка виконання програми:
assert age >= 0, "Вік не може бути від'ємним!"
^^^^^^^^
AssertionError: Вік не може бути від'ємним!У разі істинності умови age >= 0, наприклад, коли age має значення 43, програма продовжує виконання і в консолі друкується повідомлення:
Ваш вік: 43Поміркуйте, який вираз потрібно записати для інструкції assert, щоб згенерувався виняток AssertionError і в консолі надрукувалось повідомлення Ділення на нуль не дозволяється!?
def divide(a, b):
assert _____, "Ділення на нуль не дозволяється!"
return a / b
result = divide(10, 0)
print(result)Розв’язок.
def divide(a, b):
assert b != 0, "Ділення на нуль не дозволяється!"
return a / b
result = divide(10, 0)
print(result)Інструкція assert зручна в автоматичній перевірці умов й допомагає розробникам ідентифікувати помилки, проте вона не підходить для обробки помилок, наприклад, у разі введення користувачем некоректних даних.
Щоб перевірити, чи код працює так, як треба, для будь-яких вхідних даних, які він може отримувати, пишуть тести.
| Тестування - це процес перевірки програми на правильність її роботи. |
Для цілей тестування створимо три файли, які розмістимо в одному каталозі:
-
main.py- файл, який будемо запускати для проведення тестування; -
my_functions.py- файл з користувацькими функціями, які потрібно протестувати; -
utils.py- файл, який міститиме тести, що перевірятимуть правильність роботи користувацьких функцій.
Файли my_functions.py і utils.py будуть у цьому разі модулями, оскільки будуть імпортуватися: my_functions.py в utils.py, а utils.py в main.py.
Отож, файл main.py буде містити лише інструкцію імпорту усього вмісту з файлу utils.py:
import utilsФайл utils.py складатиметься з функцій, які будуть запускати тести для перевірки очікуваних результатів роботи користувацьких функцій з файлу my_functions.py.
Оскільки передбачаємо тестування в консолі, додамо в utils.py додаткову функцію console_color(), яка буде відображати текстові повідомлення результатів тестування в кольорі.
Тепер вміст файла utils.py матиме вигляд:
import sys
import os
import my_functions
if sys.platform.startswith("win32"):
os.system("color")
elif sys.platform.startswith("darwin") or sys.platform.startswith("linux"):
os.system("clear")
def console_color(text, color="green"):
colors = {
"red": "\033[31m",
"yellow": "\033[33m",
"green": "\033[32m",
"blue": "\033[34m",
"white": "\033[97m",
"magenta": "\033[35m",
"cyan": "\033[36m",
"lightred": "\033[91m",
"lightyellow": "\033[93m",
"lightgreen": "\033[92m",
"lightblue": "\033[94m",
"lightgray": "\033[37m",
"darkgray": "\033[90m",
"lightmagenta": "\033[95m",
"lightcyan": "\033[96m",
"reset": "\033[0m",
"default": "\033[39m"
}
return f"\n{colors[color]}{text}{colors["reset"]}"
У Windows 10 і новіших версіях інструкція os.system("color") вмикає підтримку ANSI escape sequences - спеціальних послідовностей символів, які починаються з \033 (за чим слідує набір кодів, наприклад, \033[31m для тексту червоного кольору) і використовуються для керування відображенням тексту у вікні командного рядка. Для Linux та darwin (macOS) підтримка ANSI-кодів вже увімкнена, а виклик os.system("clear") просто очищає термінал.
|
Опишемо у файлі utils.py функцію test(), яка буде друкувати в консолі текстове повідомлення про те, чи пройшов тест (OK зеленого кольору), чи ні (FAIL червоного кольору):
def test(received, expected):
if (expected == received):
print(console_color("OK"))
else:
print(console_color("FAIL", "red"))Значення received - це значення, яке потрапляє у функцію test() для перевірки, а expected - значення, яке очікують отримати. Якщо received і expected однакові, то тест пройшов успішно, інакше - ні.
Опишемо першу тестову функцію test_hello(). Назва тестової функції утворена зі слова test, символа підкреслення й назви користувацької функції hello, яку будуть тестувати:
def test_hello():
print("\nTesting hello!")
test(my_functions.hello(4), "hello" * 4)
test(my_functions.hello(1), "hello")
test(my_functions.hello(10), "hello" * 10)Ця тестова функція буде тестувати користувацьку функцію hello() з файла my_functions.py, покриваючи три тестові випадки. Наприклад, у першому тестовому випадку користувацька функція my_functions.hello(4) поверне результат, який буде порівнюватися з результатом обчислення виразу "hello" * 4.
Загалом усі тестові випадки будуть перевіряти, чи правильно був утворений рядок з n-повторень слова "hello", де n - ціле число, яке передається у користувацьку функцію hello().
Додамо виклик функції test_hello() у кінець файла utils.py і подивимось на увесь його вміст:
import sys
import os
import my_functions
if sys.platform.startswith("win32"):
os.system("color")
elif sys.platform.startswith("darwin") or sys.platform.startswith("linux"):
os.system("clear")
def console_color(text, color="green"):
colors = {
"red": "\033[31m",
"yellow": "\033[33m",
"green": "\033[32m",
"blue": "\033[34m",
"white": "\033[97m",
"magenta": "\033[35m",
"cyan": "\033[36m",
"lightred": "\033[91m",
"lightyellow": "\033[93m",
"lightgreen": "\033[92m",
"lightblue": "\033[94m",
"lightgray": "\033[37m",
"darkgray": "\033[90m",
"lightmagenta": "\033[95m",
"lightcyan": "\033[96m",
"reset": "\033[0m",
"default": "\033[39m"
}
return f"\n{colors[color]}{text}{colors["reset"]}"
def test(received, expected):
if (expected == received):
print(console_color("OK"))
else:
print(console_color("FAIL", "red"))
def test_hello():
print("\nTesting hello!")
test(my_functions.hello(4), "hello" * 4)
test(my_functions.hello(1), "hello")
test(my_functions.hello(10), "hello" * 10)
test_hello()Залишається реалізувати алгоритм у файлі my_functions.py в тілі користувацької функції hello(), який би задовільнив усі тестові випадки:
def hello(n):
return n * "hello"Запускаємо у командному рядку файл main.py на виконання
python main.pyі бачимо, що усі тести пройшли успішно:
Testing hello!
OK
OK
OKЧудово! Напишемо у файлі utils.py ще дві тестові функції.
def test_my_sum():
print("\nTesting my_sum!")
test(my_functions.my_sum([3, 6, 0]), 9)
test(my_functions.my_sum([0, 2, 3, 100]), 105)
test(my_functions.my_sum([-25, -10, 5, 20, 35]), 25)
def test_calc():
print("\nTesting calc!")
test(my_functions.calc('-', 5, 4), 1)
test(my_functions.calc('+', 15, 3), 18)
test(my_functions.calc('*', 25, 2), 50)
test(my_functions.calc('/', 15, 5), 3.0)
test(my_functions.calc('//', 24, 5), 4)
test(my_functions.calc('%', 24, 5), 4)
test_my_sum()
test_calc()Цього разу будуть тестуватися дві користувацькі функції my_sum() і calc() з файла my_functions.py.
Функція my_sum(numbers) повинна повертати без використання вбудованої функції sum() суму елементів списку numbers, який вона отримує як вхідний параметр. Функція calc(sign, a, b) має реалізувати простий калькулятор для арифметичних операцій sign (+, -, *, /, %, //) над двома числами a і b.
Напишемо алгоритми для розв’язування цих задач.
def my_sum(numbers):
s = 0
for n in numbers:
s += n
return s
def calc(sign, a, b):
result = {
"+": a + b,
"-": a - b,
"*": a * b,
"/": a / b,
"%": a % b,
"//": a // b,
}
return result[sign]У кінцевому підсумку наведемо повний вміст файлів utils.py
import sys
import os
import my_functions
if sys.platform.startswith("win32"):
os.system("color")
elif sys.platform.startswith("darwin") or sys.platform.startswith("linux"):
os.system("clear")
def console_color(text, color="green"):
colors = {
"red": "\033[31m",
"yellow": "\033[33m",
"green": "\033[32m",
"blue": "\033[34m",
"white": "\033[97m",
"magenta": "\033[35m",
"cyan": "\033[36m",
"lightred": "\033[91m",
"lightyellow": "\033[93m",
"lightgreen": "\033[92m",
"lightblue": "\033[94m",
"lightgray": "\033[37m",
"darkgray": "\033[90m",
"lightmagenta": "\033[95m",
"lightcyan": "\033[96m",
"reset": "\033[0m",
"default": "\033[39m"
}
return f"\n{colors[color]}{text}{colors["reset"]}"
def test(received, expected):
if (expected == received):
print(console_color("OK"))
else:
print(console_color("FAIL", "red"))
def test_hello():
print("\nTesting hello!")
test(my_functions.hello(4), "hello" * 4)
test(my_functions.hello(1), "hello")
test(my_functions.hello(10), "hello" * 10)
def test_my_sum():
print("\nTesting my_sum!")
test(my_functions.my_sum([3, 6, 0]), 9)
test(my_functions.my_sum([0, 2, 3, 100]), 105)
test(my_functions.my_sum([-25, -10, 5, 20, 35]), 25)
def test_calc():
print("\nTesting calc!")
test(my_functions.calc('-', 5, 4), 1)
test(my_functions.calc('+', 15, 3), 18)
test(my_functions.calc('*', 25, 2), 50)
test(my_functions.calc('/', 15, 5), 3.0)
test(my_functions.calc('//', 24, 5), 4)
test(my_functions.calc('%', 24, 5), 4)
test_hello()
test_my_sum()
test_calc()і my_functions.py
def hello(n):
return n * "hello"
def my_sum(numbers):
s = 0
for n in numbers:
s += n
return s
def calc(sign, a, b):
result = {
"+": a + b,
"-": a - b,
"*": a * b,
"/": a / b,
"%": a % b,
"//": a // b,
}
return result[sign]Виконавши файл main.py у командному рядку, отримуємо успішне проходження усіх тестів:
Testing hello!
OK
OK
OK
Testing my_sum!
OK
OK
OK
Testing calc!
OK
OK
OK
OK
OK
OKЗа потреби можна змінити код в тілі будь-якої користувацької функції, щоб отримати результати тестів, що зазнали невдачі.
Насамкінець, спробуйте самостійно у файлі my_functions.py написати користувацькі функції для розв’язування таких задач:
-
Напишіть функцію, яка завжди повертає число
5. Не можна використовувати символи:0123456789*+-/.
def unusual_five():
pass-
Ви можете надрукувати своє ім’я на рекламному щиті. Напишіть функцію, яка повертає суму у вигляді числа, скільки це вам коштуватиме. Ціна
priceкожного символу становить 25 доларів, але вона може бути іншою, якщо вам надано 2 параметри замість 1. Ви не можете використовувати оператор множення*. Наприклад, якби ваше ім’яnameбулоNiklaus Wirth, реклама коштувала б 325 доларів: 13 літер * 25 = 325 доларів (пропуски враховуються).
def billboard(name, price=25):
passТестові функції з наборами тестів у файлі utils.py мають такий вигляд:
def test_unusual_five():
print("\nTesting unusual_five!")
test(my_functions.unusual_five(), 5)
def test_billboard():
print("\nTesting billboard!")
test(my_functions.billboard("James Gosling"), 13 * 25)
test(my_functions.billboard("Dennis Ritchie", 30), 14 * 30)
test(my_functions.billboard("Brendan Eich", 30), 12 * 30)
test(my_functions.billboard("Guido van Rossum", 35), 16 * 35)
test(my_functions.billboard("Bjarne Stroustrup"), 17 * 25)
test(my_functions.billboard("Rasmus Lerdorf", 20), 14 * 20)
test(my_functions.billboard("Yukihiro Matsumoto"), 18 * 25)
test(my_functions.billboard("Niklaus Wirth", 25), 13 * 25)
test_unusual_five()
test_billboard()Розв’язок.
def unusual_five():
return len("five!")
def billboard(name, price=25):
return sum(price for letter in name)Тепер розглянемо юніт-тестування (Unit Testing) - тестування окремих частин програми, зазвичай функцій або методів, за допомогою пакета unittest зі стандартної бібліотеки Python.
Наприклад, для функції add(), яка додає два числа
def add(a, b):
return a + bюніт-тест може виглядати так:
import unittest (1)
class TestAddFunction(unittest.TestCase): (2)
def test_add(self): (3)
self.assertEqual(add(2, 3), 5) (4)
self.assertEqual(add(-1, 1), 0)
self.assertEqual(add(-1, -1), -2)
if __name__ == "__main__":
unittest.main() (5)| 1 | Модуль unittest - стандартна бібліотека Python, яка забезпечує механізм для створення і виконання автоматизованих тестів. Він дозволяє організувати тестування функцій і класів. |
| 2 | Тестовий клас TestAddFunction успадковується від класу unittest.TestCase. Це дозволяє використовувати всі функції та методи, які надає unittest для тестування. Оскільки клас успадковує TestCase, ви можете створювати тестові методи в ньому, а unittest зможе автоматично виконати їх під час тестування. |
| 3 | test_add - це метод тестування, який перевіряє функцію add(). Усі методи тестування повинні починатися з test_. Це дозволяє unittest визначати, що це саме тестовий метод. |
| 4 | self.assertEqual(a, b) - це метод першої перевірки. Він порівнює два значення: перше - add(2, 3) - результат, що повертає функція add() та друге - 5 значенння, яке очікується з функції add(). Якщо вони не рівні, тест зазнає невдачі - згенерується виняток AssertionError. Аналогічно проходять друга та третя перевірки. |
| 5 | Запуск тестування, якщо цей файл запускається безпосередньо (вираз __name__ == "__main__" є істинним), а не імпортується. unittest.main() автоматично знайде всі методи, які починаються з test_, і виконає їх. Якщо все тестування успішне, не буде виведено жодних помилок, і програма завершиться успішно. Якщо хоча б один тест не пройде, виведеться повідомлення про помилку, і програма завершиться з помилкою. |
Збережемо обидва фрагменти коду в одному файлі
import unittest
def add(a, b):
return a + b
class TestAddFunction(unittest.TestCase):
def test_add(self):
self.assertEqual(add(2, 3), 5)
self.assertEqual(add(-1, 1), 0)
self.assertEqual(add(-1, -1), -2)
if __name__ == "__main__":
unittest.main()і виконаємо код:
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK
Якщо результати виконання виводяться у інтерактивний інтерпретатор, використовуйте виклик unittest.main(exit=False).
|
У цьому разі unittest виконав перевірки і всі тести успішно пройшли:
-
Перша перевірка: чи додається 2 і 3, результат повинен бути 5.
-
Друга перевірка: чи додається -1 і 1, результат повинен бути 0.
-
Третя перевірка: чи додається -1 і -1, результат повинен бути -2.
Якщо якийсь тест не пройде, виведеться помилка. Наприклад, для тесту self.assertEqual(add(1, 1), 10) буде наступний результат:
F
======================================================================
FAIL: test_add (__main__.TestAddFunction.test_add)
----------------------------------------------------------------------
Traceback (most recent call last):
self.assertEqual(add(1, 1), 10)
AssertionError: 2 != 10
----------------------------------------------------------------------
Ran 1 test in 0.003s
FAILED (failures=1)Розглянемо детальніше процес тестування за допомогою бібліотеки unittest.
Напишемо програму, що сладатиметься з однієї функції, яка кожне слово в тесті записує з великої букви. Наприклад, текст "eagle" має перетворитися на "Eagle", а "The cat sleeps on the sofa" має перетворитися на "The Cat Sleeps On The Sofa" тощо.
Перший варіант нашої функції буде використовувати стандартний метод для роботи з рядками capitalize(), який перетворює перший символ рядка на велику літеру, а всі інші символи - на малі букви, і зберігатиметься у файлі c.py:
def up_case(text):
return text.capitalize()Як вже зрозуміло з попереднього прикладу, основна ідея тестування полягає у тому, щоб зрозуміти, який результат ви хочете отримати при певних вхідних даних. У нашому прикладі потрібно отримати текст, який ввели, записавши кожне слово тексту з великої літери.
Очікуваний результат називається твердженням (assertion), тому в межах пакету unittest ви перевіряєте результат за допомогою методів, чиї імена починаються зі слова assert, наприклад assertEqual.
В офіційній документації Python описуються й інші assert-методи.
|
Отже, для функції up_case() напишемо юніт-тест і збережемо під назвою test_c.py:
import unittest
import c (1)
class TestCap(unittest.TestCase):
def setUp(self): (2)
pass
def tearDown(self): (3)
pass
def test_one_word(self): (4)
text = 'ostrich'
result = c.up_case(text)
self.assertEqual(result, 'Ostrich')
def test_multiple_words(self): (5)
text = 'panda family'
result = c.up_case(text)
self.assertEqual(result, 'Panda Family')
if __name__ == '__main__':
unittest.main() (6)| 1 | Імпорт всього вмісту файлу c.py (у цьому разі c.py вважається модулем) у файл test_c.py. Модуль c.py містить лише одну функцію up_case(). |
| 2 | Перед кожним методом перевірки викликається метод setUp(). |
| 3 | Після кожного із методів перевірки викликається метод tearDown(). Задачею методів setUp() і tearDown() є виділення та звільнення ресурсів, необхідних для тестів, на зразок з’єднання з базою даних або створення деяких тестових даних. У цьому разі тести автономні, і нам не потрібно описувати методи setUp() і tearDown(), однак створювати їх порожні версії не зашкодить. |
| 4 | Першим тестом є метод test_one_word(), який запускає визначену нами функцію up_case() з імпортованого модуля c.py з різними вхідними параметрами і перевіряє, чи отримано очікуваний результат. |
| 5 | Другим тестом є метод test_multiple_words(), який запускає визначену нами функцію up_case() з імпортованого модуля c.py з різними вхідними параметрами і перевіряє, чи отримано очікуваний результат. |
| 6 | Запуск тесту. |
Якщо результати виконання файлу test_c.py виводяться у інтерактивний інтерпретатор, використовуйте виклик unittest.main(exit=False).
|
Команда python test_c.py у вікні терміналу викликає два наших методи тестування:
F.
======================================================================
FAIL: test_multiple_words (__main__.TestCap.test_multiple_words)
----------------------------------------------------------------------
Traceback (most recent call last):
self.assertEqual(result, 'Panda Family')
AssertionError: 'Panda family' != 'Panda Family'
- Panda family
? ^
+ Panda Family
? ^
----------------------------------------------------------------------
Ran 2 tests in 0.001s
FAILED (failures=1)Пакет unittest задоволений результатом першої перевірки (test_one_word), але не результатом другої (test_multiple_words). Символи ^ показують, які рядки відрізняються.
Що особливого у прикладі з кількома словами? Після прочитання документації для методу capitalize(), зрозуміла причина проблеми: метод перетворює перший символ рядка на велику літеру, а всі інші символи - на малі.
Використаємо у нашому модулі c.py в тілі нашої функції up_case() метод title(), який записує перший символ кожного слова у рядку з великої літери (якщо перший символ є буквою):
def up_case(text):
return text.title()і повторимо тести, виконавши команду python test_c.py у терміналі:
..
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OKЦього разу два тести були успішними.
Додамо ще один метод у файл test_c.py
import unittest
import c
class TestCap(unittest.TestCase):
...
def test_words_with_apostrophes(self):
text = "a fox’s keen sense of smell helps it find food"
result = c.up_case(text)
self.assertEqual(result, "A Fox’s Keen Sense Of Smell Helps It Find Food")
if __name__ == '__main__':
unittest.main()і запустимо наші тести командою python test_c.py у терміналі:
..F
======================================================================
FAIL: test_words_with_apostrophes (__main__.TestCap.test_words_with_apostrophes)
----------------------------------------------------------------------
Traceback (most recent call last):
self.assertEqual(result, "A Fox’s Keen Sense Of Smell Helps It Find Food")
AssertionError: 'A Fox’S Keen Sense Of Smell Helps It Find Food' != 'A Fox’s Keen Sense Of Smell Helps It Find Food'
- A Fox’S Keen Sense Of Smell Helps It Find Food
? ^
+ A Fox’s Keen Sense Of Smell Helps It Find Food
? ^
----------------------------------------------------------------------
Ran 3 tests in 0.002s
FAILED (failures=1)Метод title() перетворив у верхній регістр букву s у тексті Fox’s. У документації до методу title() зазначено, що він некоректно працює з апострофами. Наприкінці документації стандартної бібліотеки, що стосується рядків, знаходимо ще одного кандидата для up_case() - допоміжну функцію з ім’ям capwords(). Використоємо її у файлі c.py:
def up_case(text):
from string import capwords
return capwords(text)і знову запустимо тести командою python test_c.py у терміналі:
...
----------------------------------------------------------------------
Ran 3 tests in 0.003s
OKУсі тести успішно проходять. Але чи усі варіанти вони покривають? Додамо ще один тест у файл test_c.py:
import unittest
import c
class TestCap(unittest.TestCase):
...
def test_words_with_quotes(self):
text = "\"I'm amazed by the dolphin’s intelligence,\" said the researcher"
result = c.up_case(text)
self.assertEqual(result, "\"I'm Amazed By The Dolphin’s Intelligence,\" Said The Researcher")
if __name__ == '__main__':
unittest.main()Запустимо тести командою python test_c.py у терміналі:
...F
======================================================================
FAIL: test_words_with_quotes (__main__.TestCap.test_words_with_quotes)
----------------------------------------------------------------------
Traceback (most recent call last):
self.assertEqual(result, "\"I'm Amazed By The Dolphin’s Intelligence,\" Said The Researcher")
AssertionError: '"i\'m Amazed By The Dolphin’s Intelligence," Said The Researcher' != '"I\'m Amazed By The Dolphin’s Intelligence," Said The Researcher'
- "i'm Amazed By The Dolphin’s Intelligence," Said The Researcher
? ^
+ "I'm Amazed By The Dolphin’s Intelligence," Said The Researcher
? ^
----------------------------------------------------------------------
Ran 4 tests in 0.002s
FAILED (failures=1)Щоб тест test_words_with_quotes проходив, потрібно змінити тіло функції up_case() у файлі c.py, щоб вона враховувала випадки з апострофами та лапками.
def up_case(text):
return ' '.join(word[0].upper() + word[1:] if word else '' for word in text.split())Запустимо тести командою python test_c.py у терміналі:
....
----------------------------------------------------------------------
Ran 4 tests in 0.000s
OKТепер успішно проходять усі 4 тести.
Насамкінець, спробуйте самостійно змінити функцію up_case() для проходження тесту, коли в тексті зустрічаються цифри, зокрема з цифр можуть починатися слова:
import unittest
import c
class TestCap(unittest.TestCase):
...
def test_words_with_numbers(self):
text = "4penguins"
result = c.up_case(text)
self.assertEqual(result, "4Penguins")
if __name__ == '__main__':
unittest.main()Розв’язок.
def up_case(text):
result = ''
for word in text.split():
if word and word[0].isalpha():
word = word[0].upper() + word[1:]
elif word:
for i, d in enumerate(word):
if d.isalpha():
word = word[:i] + word[i].upper() + word[i+1:]
break
result += word + ' '
return result.rstrip()